
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




就在几个小时前,DeepSeekAI宣布官方的聊天模型从DeepSeek-V3升级到了DeepSeek-V3.1,上下文拓展至128K。虽然,官方目前没有给出这个模型的详细信息,DataLearnerAI已经搜集到很多信息供大家参考。

Aider 是一个在终端里进行结对编程的开源工具。为评估不同大模型在“按照指令对代码进行实际可落地的编辑”上的能力,Aider 提出并维护了公开基准与排行榜,用于比较模型在无人工干预下完成代码修改任务的可靠性与成功率。该评测已被多家模型提供方在技术说明中引用,用作代码编辑与指令遵循能力的对照指标。

GPT-5 在指令遵循和推理能力上比前代更强,但也因此更“敏感”:如果规则里有冲突或表述过度强硬,模型往往会卡壳或输出异常。为此,OpenAI 发布了面向开发者的 《GPT-5 for Coding》技巧小抄,其中总结了使用 GPT-5 进行编程与代码生成时最实用的六条经验。这些技巧与普通的“写作提示工程”不同,它们专门针对软件开发场景:如何写规则、怎样控制推理强度、如何避免模型“想太多”,以及怎样利用 GPT-5 的新特性把它真正驯化成可靠的结对编程伙伴。本文对这六条技巧逐条进行解释总结。
谷歌开源了其Gemma 3模型系列的新成员——Gemma 3 270M。该模型的设计理念并非追求通用性和大规模,而是专注于为定义明确的特定任务提供一个高效、紧凑的解决方案。其核心价值在于通过微调(fine-tuning)来执行专门化任务。

GPT-5 在 ChatGPT 中引入了“自动在普通/推理间切换”的机制,但模式命名、配额规则和速率限制让许多用户困惑。本文梳理不同模式的作用、是否计入推理配额、各订阅层的可用性与限制、旧模型的替换规则,并提供三步配额优化策略。特别提示:编码与大上下文任务应优先使用 GPT-5 Thinking(≈196k 上下文),而普通 Chat 模式上下文为 32k。
在衡量大语言模型(LLM)智能水平的众多方法中,除了常见的常识推理、专业领域测评外,还有一个正在兴起且极具挑战性的方向——算法问题求解。在这一领域,几乎没有哪项比赛能比 国际信息学奥林匹克(International Olympiad in Informatics,简称 IOI) 更具权威性与含金量。

智谱AI刚刚开源了新一代视觉-语言模型(Vision-Language Model, VLM)——GLM-4.5V。该模型基于其旗舰文本基础模型GLM-4.5-Air(总参数量1060亿,激活参数量120亿),延续GLM-4.1V-Thinking的技术路线,在42项公开视觉多模态基准测试中,在同规模模型中实现领先性能。GLM-4.5V面向图像、视频、文档理解以及GUI任务等常见多模态场景,采用Mixture-of-Experts(MoE)架构,并保持开源。
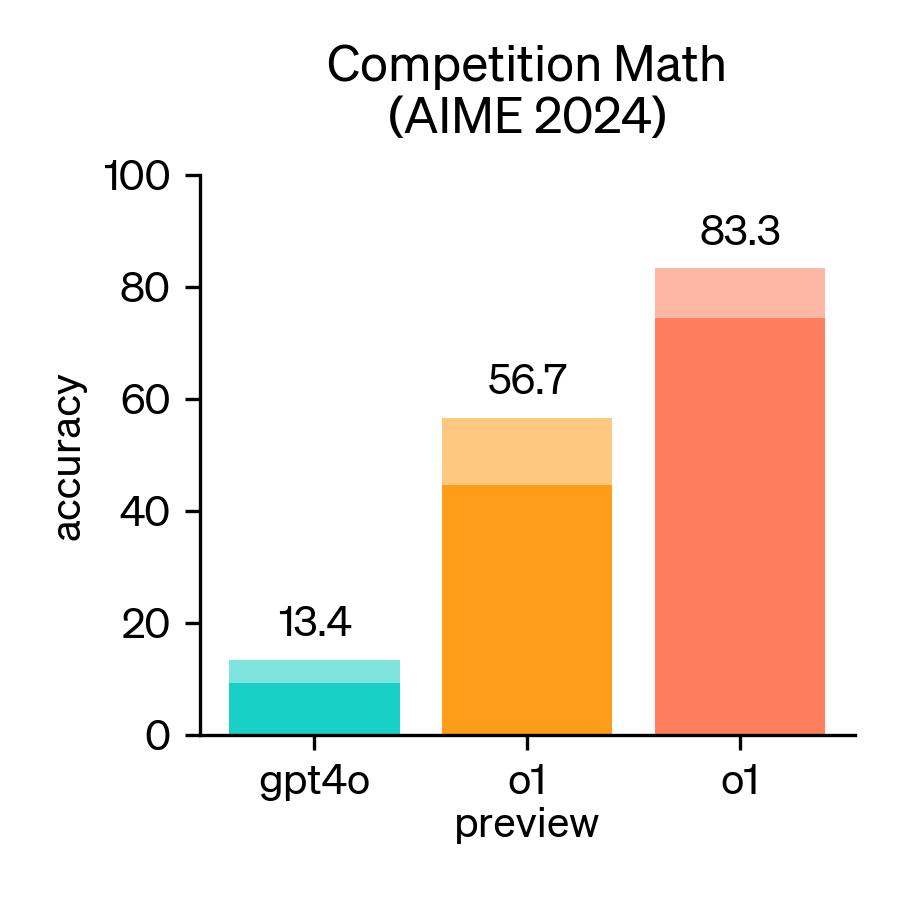
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。
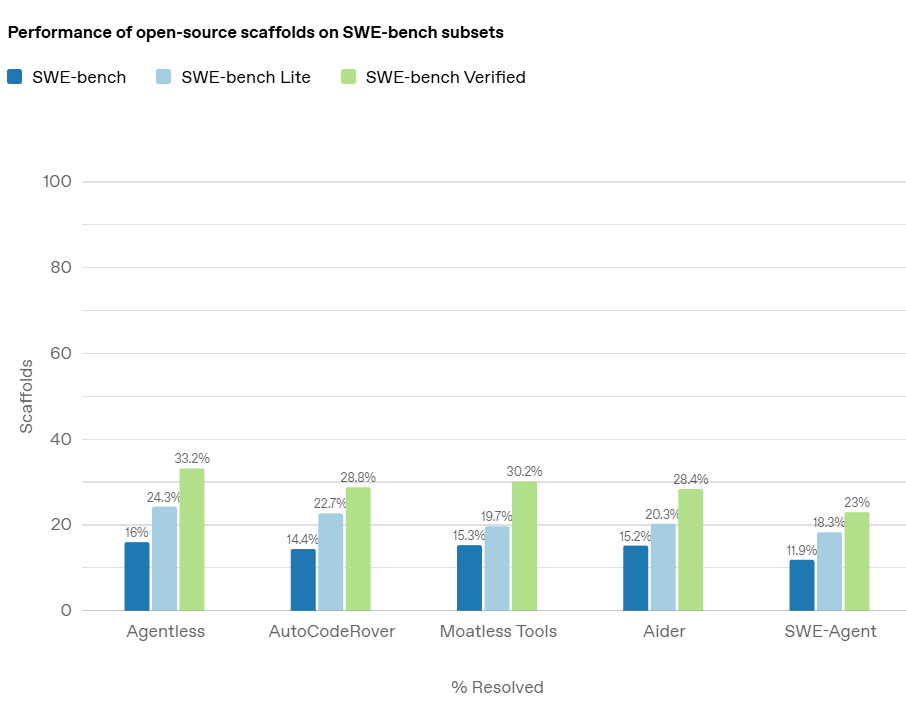
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
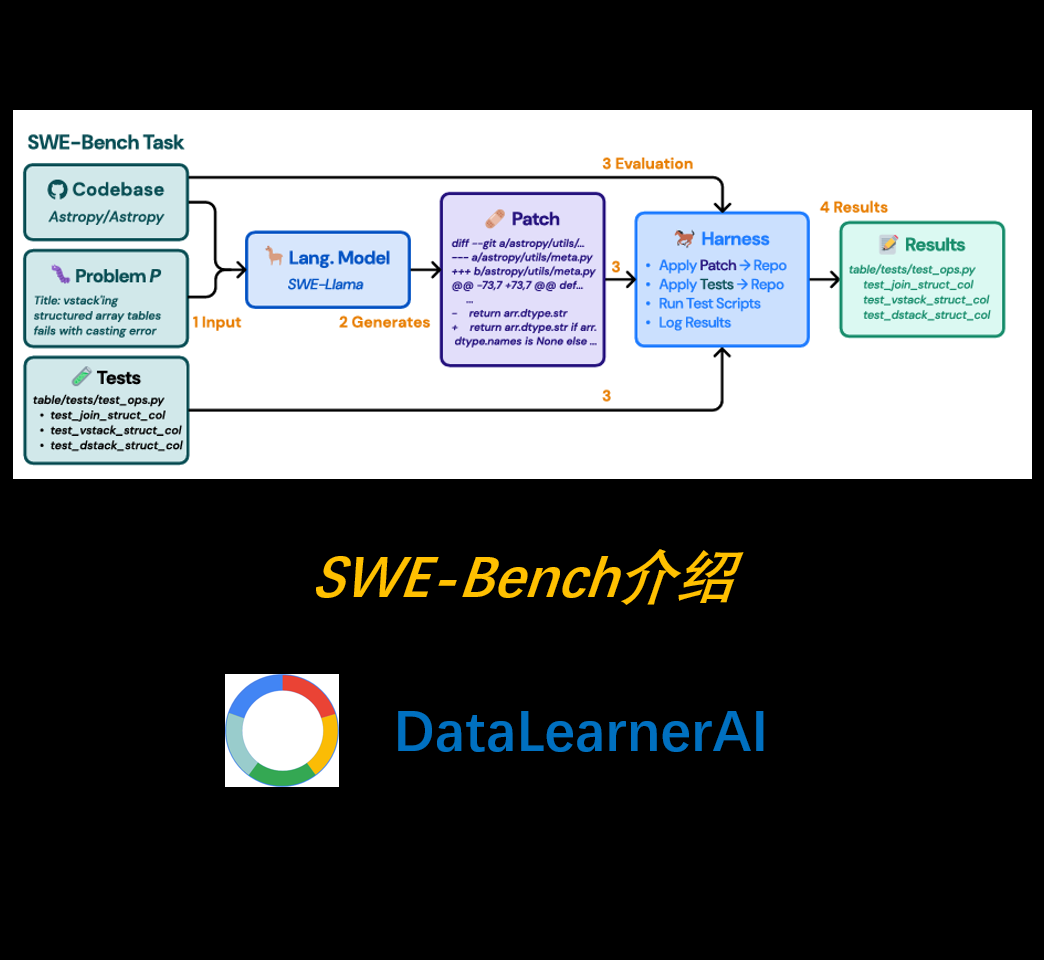
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。

阿里巴巴的 Qwen Code 是一款开源的命令行 AI 工具,旨在提升开发者的编程效率,特别适用于处理大型代码库和复杂的开发任务。 2025年8月9日,阿里宣布提供每天2000次的免费Qwen Code服务,应该是满足大多数开发者的日常需求了。

Grok Imagine 是一个由 xAI 开发的创新功能,集成到 Grok AI 聊天机器人中,旨在让用户能够从文本和视觉命令快速生成图像和视频。Grok Imagine最大的特点是能够生成长达 15 秒的视频,带有同步音频,使其成为 OpenAI 的 Sora 和 Google 的 Veo 3 等工具的直接竞争者。此外,它还包括一个“Spicy”模式,允许生成成人或显式内容,这一点引发了伦理和潜在误用的争议。
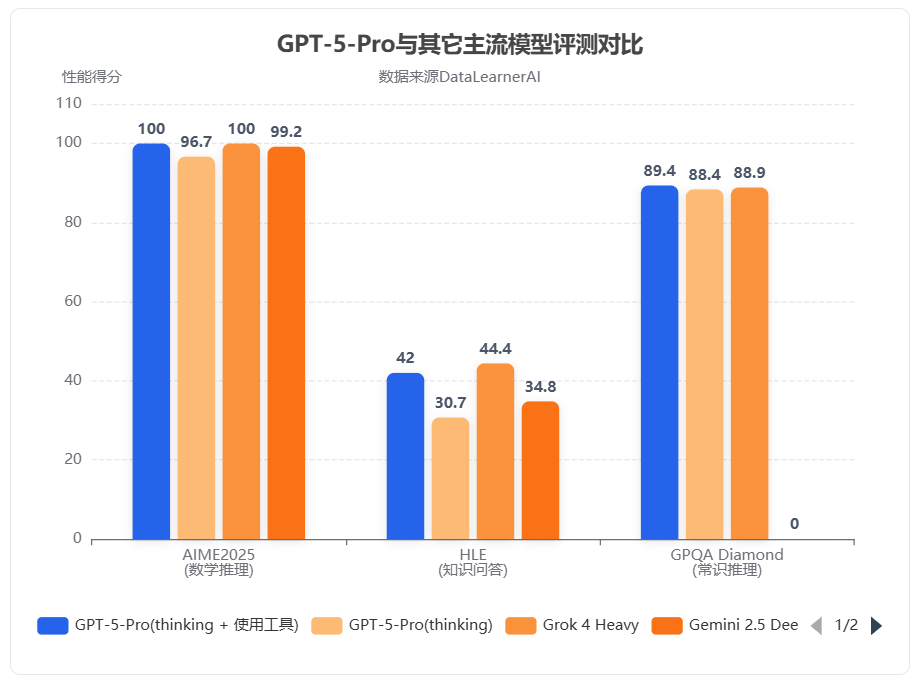
几个小时前,OpenAI发布了全新一代大模型GPT-5系列。本次发布的是一个全新的AI系统,而非一个单独的模型系列。GPT-5背后包含了5个不同的模型系列或者版本,分别是GPT-5-Pro、GPT-5、GPT-5-mini、GPT-5-nano和GPT-5-Chat。
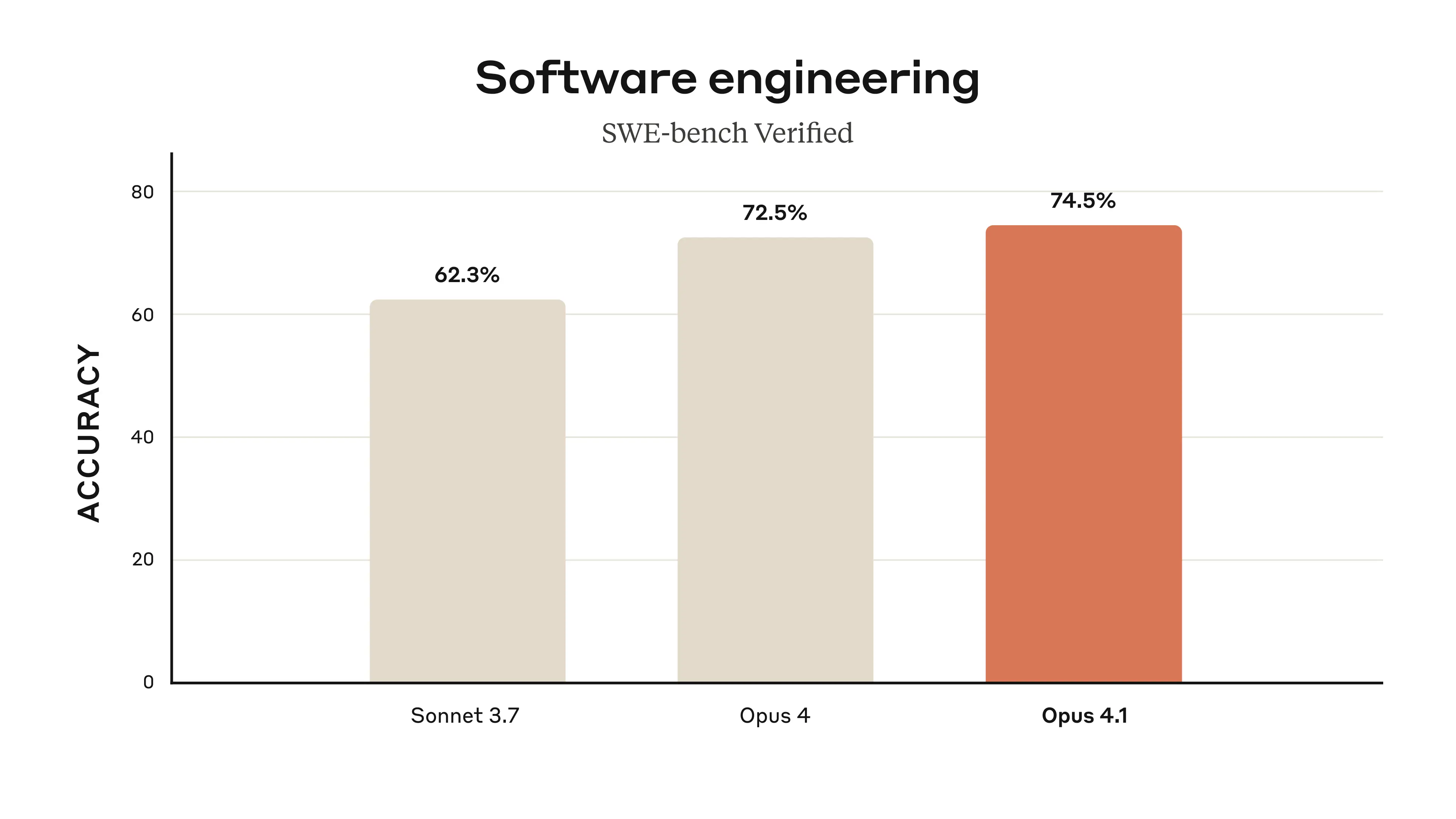
Anthropic 在 Opus 4 发布不到三个月后推出 Claude Opus 4.1,宣称“可直接替换”旧版模型。更新聚焦真实世界编码、长链路代理(agentic)任务和细粒度推理,同时保持相同 API 名称结构和计费档位,方便现有应用平滑迁移。
近日,OpenAI在发布其开源模型gpt-oss-120b和gpt-oss-20b的同时,也推出了一种专为这些模型设计的全新消息格式——Harmony。对于希望在自有解决方案中充分利用这些开源模型的开发者而言,理解Harmony至关重要。本文将以客观的第三方视角,详细解析Harmony格式的设计理念与技术细节。
今日推荐
MetaAI官宣开源编程大模型CodeLLaMA!基于LLaMA2微调!超越OpenAI的Codex,最高支持10万tokens输入!
Google反击OpenAI的大杀器!下一代语言模型PaLM 2:增加模型参数并不是提高大模型唯一的路径!
DeepSeekAI开源国产第一个基于混合专家技术的大模型:DeepSeekMoE-16B,未来还有1450亿参数的MoE大模型
Seq2Seq的建模解释和Keras中Simple RNN Cell的计算及其代码示例
吴恩达AI系列短课再添精品课程:如何基于LangChain使用LLM构建私有数据的问答系统和聊天机器人
HuggingFace官方宣布将对GGUF格式的大模型文件增加更多的支持,未来可以直接在HF上查看GGUF文件的元数据信息!