
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
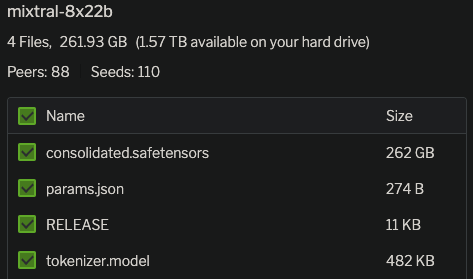
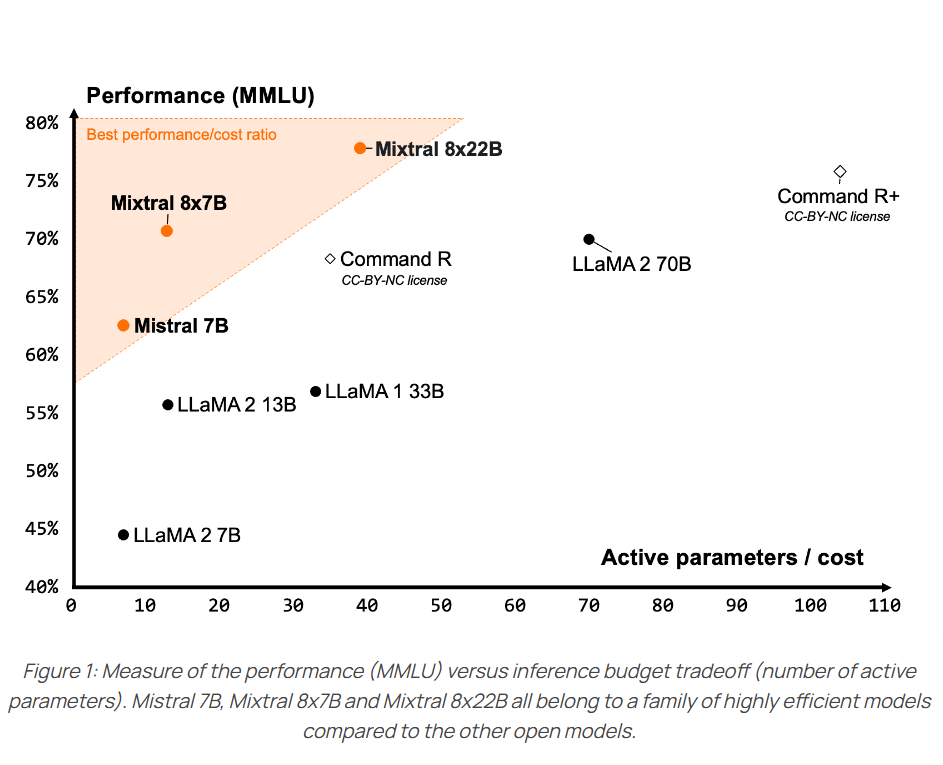
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。

Mistral-7B是由MistralAI开源的一个73亿参数规模的大语言模型,最早在2023年9月底开源。因为其良好的性能和友好的开源协议被很多人使用。今天,这个模型升级到来v0.2版本Mistral-7B-v0.2。基于Mistral-7B-v0.2进行指令微调的模型 Mistral-7B-Instruct-v0.2在2023年11月11日公布,而这个基座模型则是在2023年3月24日开源。
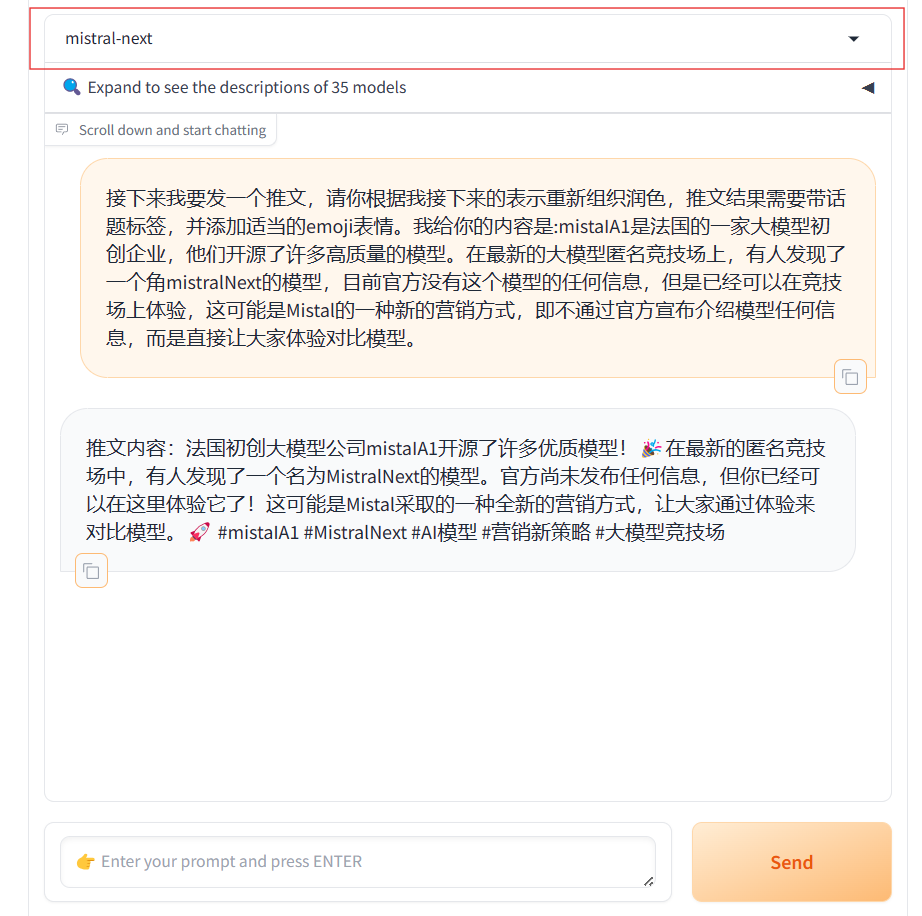
MistralAI又悄悄地上线了另一个模型,即Mistral Next。相比之前的发布预训练种子引起大家猜测的方式,本次MistralAI又把模型发布玩出了花,他们没有公布任何信息,选择直接上架LM-SYS的大模型竞技场Chat Arena,让大家直接体验对比。

在人工智能快速发展的今天,创新型模型如Mixtral 8x7B的出现,不仅推动了技术的进步,还为未来的AI应用开辟了新的可能性。这款基于Sparse Mixture of Experts(SMoE)架构的模型,不仅在技术层面上实现了创新,还在实际应用中展示了卓越的性能。尽管一个月前这个模型就发布,但是MistralAI今天才上传了这个模型的论文,我们可以看到更详细的信息。

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。