
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




开源大语言模型经过一年多的发展,终于有一个模型可以在权威榜单上击败GPT-4的较早的版本,这就是CohereAI企业开源的Command R+。这是一个开源但是不允许商用的模型,参数规模达到1040亿,也是目前为止开源参数规模最大的一个模型。
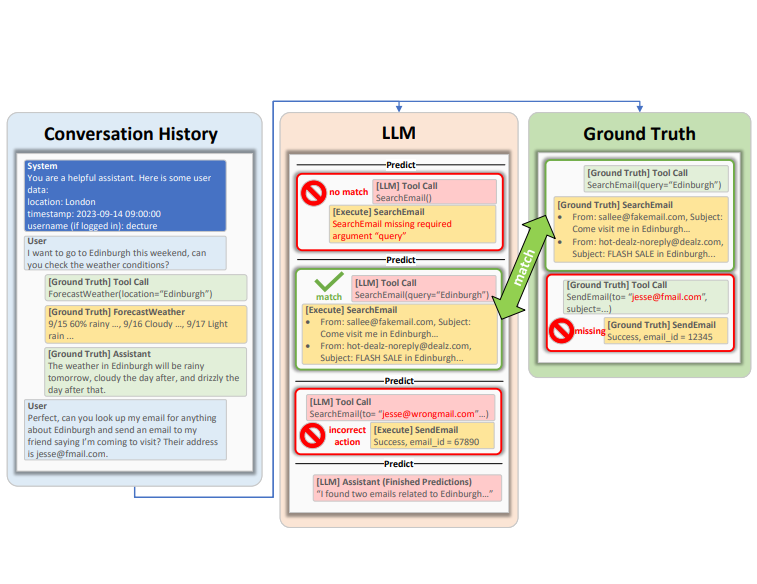
为了更好地评估大语言模型的工具使用能力,微软的研究人员提出了ToolTalk Benchmark基准测试工具,可以帮助我们更加简单地理解大语言模型在工具使用方面的水准。ToolTalk旨在评估大型语言模型(LLMs)在对话环境中使用工具的能力。这些工具可以是搜索引擎、计算器或Web API等,它们能够帮助LLMs访问私有或最新的信息,并代表用户执行操作。
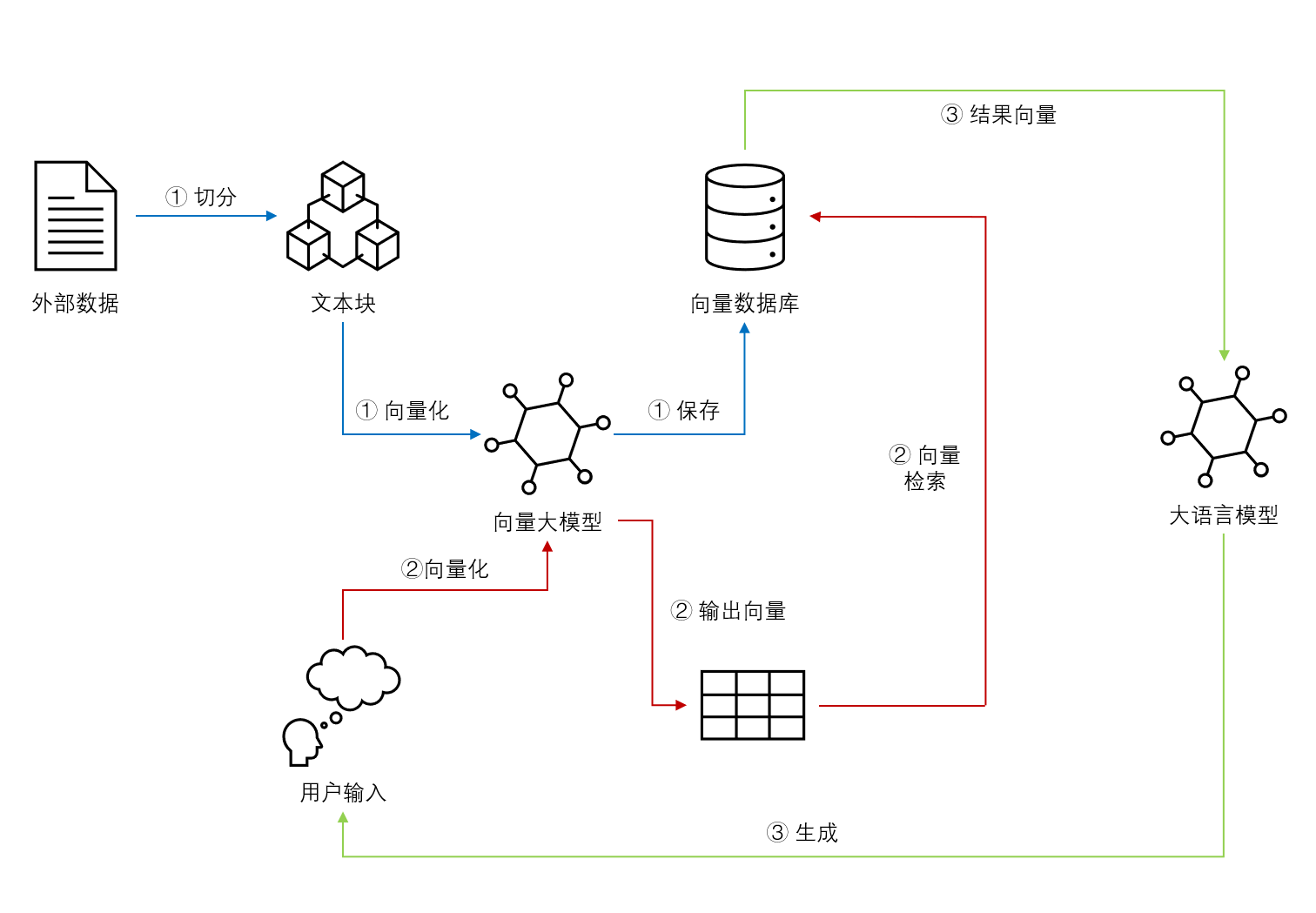
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。

检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。

在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。
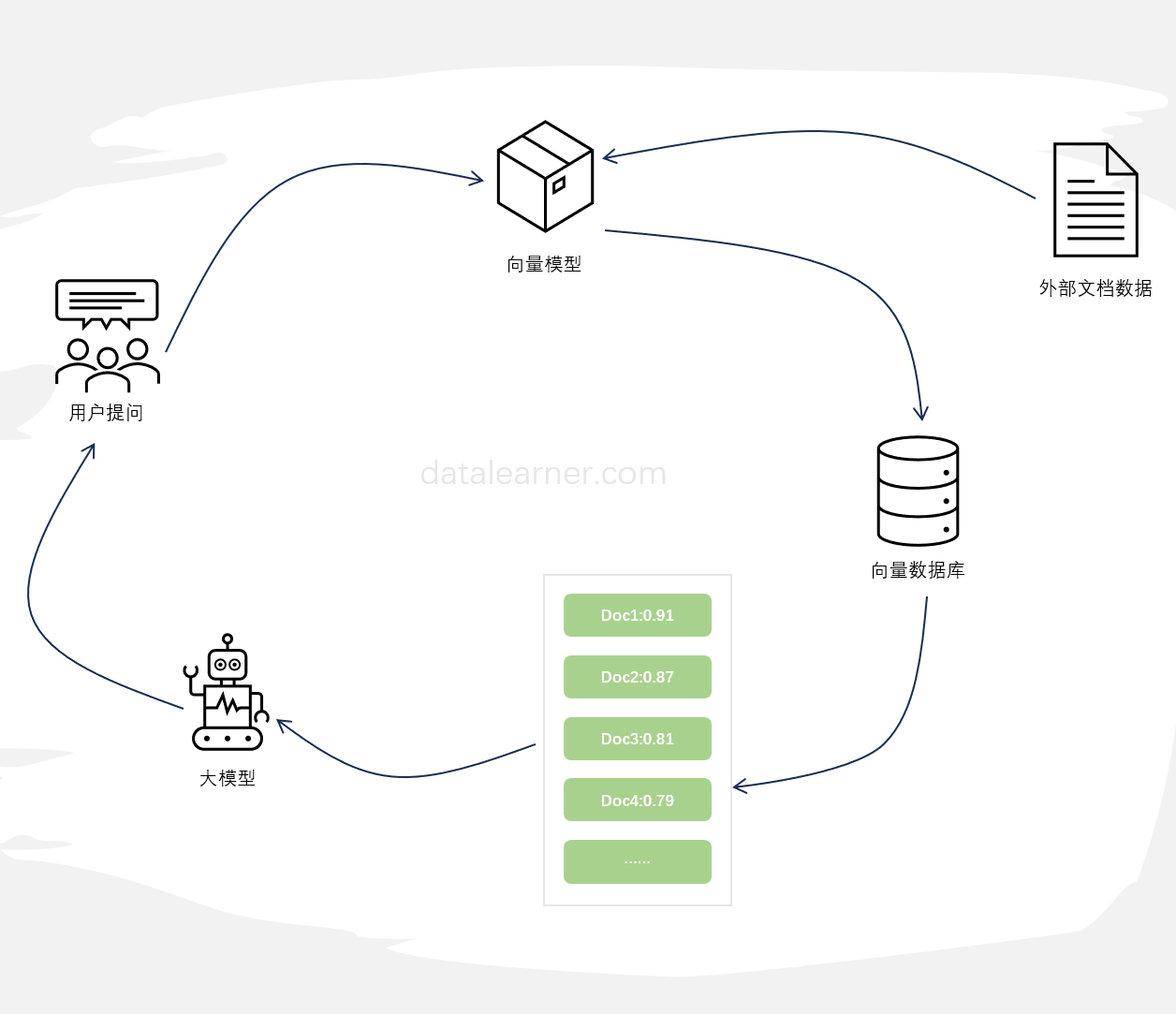
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。
今日推荐
如何用7.7亿参数的蒸馏模型超过5400亿的大语言模型——Google提出新的模型蒸馏方法:逐步蒸馏(Distilling step-by-step)详解
HuggingFace官方宣布将对GGUF格式的大模型文件增加更多的支持,未来可以直接在HF上查看GGUF文件的元数据信息!
使用SpringMVC创建Web工程并使用SpringSecurity进行权限控制的详细配置方法
【转载】全面解读ICML 2017五大研究热点 | 腾讯AI Lab独家解析
最新发布!截止目前最强大的最高支持65k输入的开源可商用AI大模型:MPT-7B!
主题模型聚类匹配2018TKDE阅读笔记(Topic Models for Unsupervised Cluster Matching)