
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



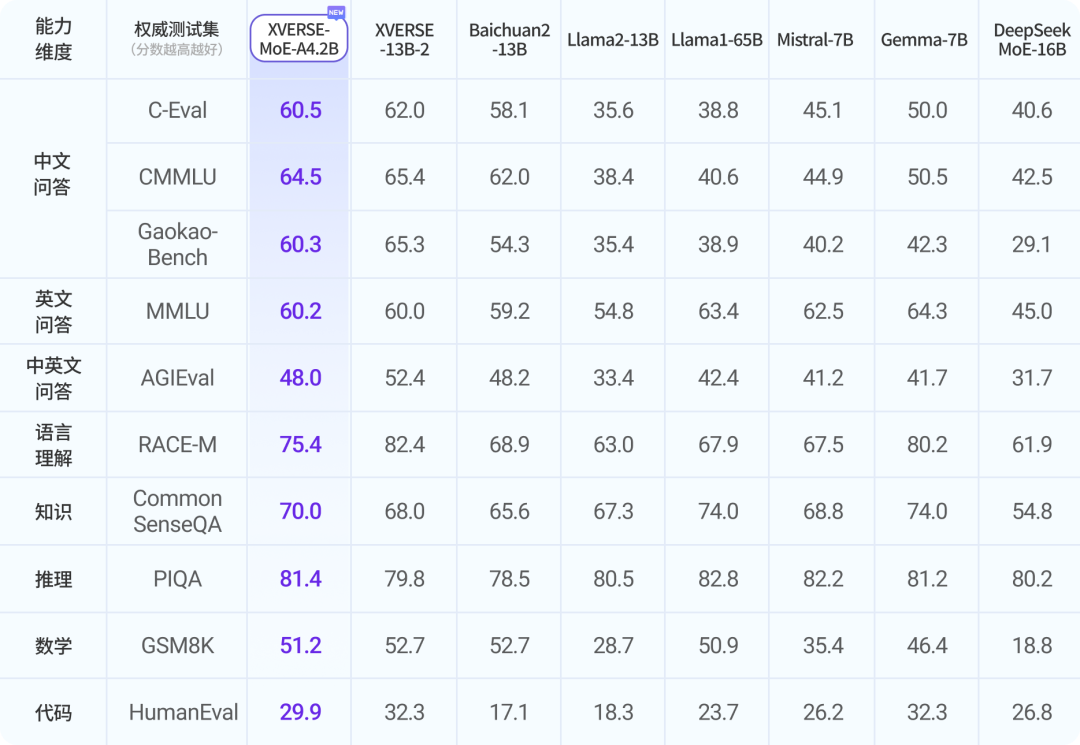
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
今日推荐
OpenAI发布最新最强大的AI对话系统——GPT3.5微调的产物ChatGPT
如何让大模型提取更有信息密度的文本摘要?SalesforceAI最新的密度链提示方法Chain of Density Prompting
当前业界最优秀的8个编程大模型简介:从最早的DeepMind的AlphaCode到最新的StarCoder全解析~
Keras中predict()方法和predict_classes()方法的区别
使用Let's Encrypt生成Tomcat使用的SSL证书并使用
阿里开源最新Qwen-14B:英文理解能力接近LLaMA2-70B,数学推理能力超过GPT-3.5!