重磅!苹果官方发布大模型框架:一个可以充分利用苹果统一内存的新的大模型框架MLX,你的MacBook可以一键运行LLaMA了
2,886 views
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。
Follow DataLearner WeChat for the latest AI updates

根据官方的介绍,MLX的设计受到PyTorch、Jax和ArrayFile的启发,目的是设计一个对用户极其友好,但同时在训练和部署上也非常高效的框架。所以,它的接口你会非常熟悉,因为它的Python接口与NumPy很相似,而它的神经网络模型的接口和PyTorch非常类似。所以如果此前你使用Python编写相关模型代码,几乎是没有障碍的使用和切换。
MLX的关键特性如下:
熟悉的API:MLX 有一个 Python API,紧密遵循 NumPy。MLX 还有一个功能齐全的 C++ API,与 Python API 非常相似。MLX 拥有像mlx.nn和 mlx.optimizers这样的高级包,其 API 紧密遵循 PyTorch,以简化构建更复杂的模型。
可组合的函数转换:MLX 具有可组合的函数转换,用于自动微分、自动向量化和计算图优化。
延迟计算:MLX 中的计算是延迟的。数组仅在需要时才实体化。
动态图构建:MLX 中的计算图是动态构建的。更改函数参数的形状不会触发缓慢的编译,调试简单直观。
多设备:操作可以在任何支持的设备上运行(目前是 CPU 和 GPU)。
统一内存:MLX 与其他框架的一个显著区别是统一内存模型。MLX 中的数组存在于共享内存中。对 MLX 数组的操作可以在任何支持的设备类型上执行,无需移动数据。
从上面的描述中可以看到,MLX与其它框架的最大的不同点是可以充分使用苹果的统一内存来计算,而不需要搬运数据。关于统一内存架构相比显存和内存的方式运行大模型参考:https://www.datalearner.com/blog/1051698716733526
从官方的示例看,苹果的MLX框架完成度很高,它支持transformer架构模型的训练、当前预训练模型如何LLaMA的推理、基于LoRA的高效参数微调、支持载入使用多模态大模型Stable Diffusion和Whisper等。
此外,MLX还有个配套框架教MLX Data,这是一个不依赖特定框架的数据加载库,可以与PyTorch、Jax 或 MLX 一起使用。MLX Data数据加载库的目标是高效但同时也具有灵活性,例如能够每秒加载和处理数千张图片,同时也能在生成的批次上运行任意 Python 转换。这个库的推出很有可能与苹果的统一内存数据的使用有关,有了它应该可以更加高效地在苹果设备上读写数据。
下图是一个Transformer语言模型的MLX代码样例:

可以看到,这个代码风格和PyTorch极其相似。
此外MLX支持的特性很新,例如,它还提供了一个官方的RoPE实现(Rotary Positional Encoding (RoPE) 是一种在自然语言处理和其他序列建模任务中用于编码序列位置信息的技术。它主要用于 Transformer 模型中,用来增强模型对序列中元素位置的理解。RoPE 的核心思想是将位置信息编码到每个元素的表示中,而不是像传统,这是2021年推出的算法),还有MultiHeadAttention的官方实现。
在官方的实例中,还有一个306行的LLaMA1的推理代码,非常简洁,不仅适合学习MLX,也适合理解LLaMA模型。
从官方的代码示例看,MLX代码运行LLaMA的预训练模型需要先做一次模型权重的转换操作:
python convert.py <path_to_torch_weights> mlx_llama_weights.npz
这里的convert.py脚本是官方提供的torch转mlx的代码,其实非常简单,核心方法也就20行左右。但是,每一个预训练结果可能都要定制这样的代码才能运行,这对于大多数人来说可能门槛还是略高官方如果不能提供通用一点的方法那估计是一个障碍
目前官方的提供的样例中包含了LLaMA、Mistral、Stable Diffusion、Whisper四个模型的推理代码。其中LLaMA提供了基于LoRA微调的代码。
尽管发布才几个小时,但已经有人测试,M2 Pro Mac电脑使用MLX运行Stable Diffusion 2.1模型50个steps要55秒~
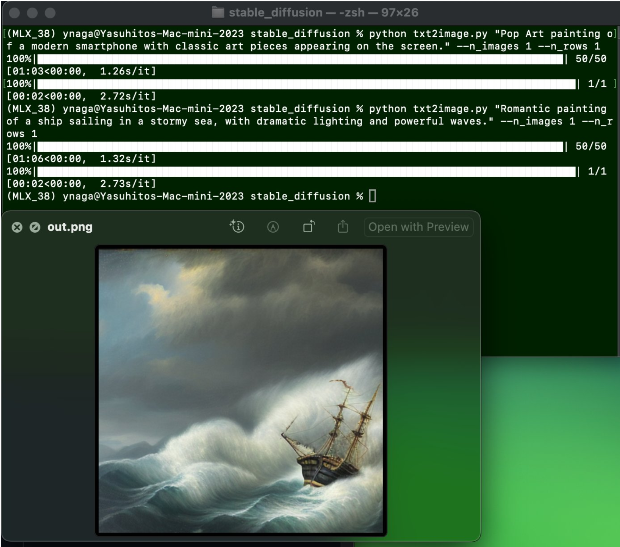
另外,还有网友测试M2 Ultra 64 GB电脑运行Mistral模型每秒25个tokens!
MLX开源协议是MIT,意味着这是一个完全自由商用协议的框架,目前官方开源了MLX框架和MLX Data框架,并在官方GitHub上提供了以MLX的示例,预计未来会加入更多模型的实例。
MLX官方GitHub地址:https://github.com/ml-explore/mlx MLX Data官方GitHub地址:https://github.com/ml-explore/mlx-data MLX Examples的地址:https://github.com/ml-explore/mlx-examples
下图展示了MLX的Stars数量,可以看到几个小时突破了2.5K个: