DataLearner AI A knowledge platform focused on LLM benchmarking, datasets, and practical instruction with continuously updated capability maps.
© 2026 DataLearner AI. DataLearner curates industry data and case studies so researchers, enterprises, and developers can rely on trustworthy intelligence.
AI 的下一阶段,不是更长的推理链,而是真正的行动力,大模型训练将从“推理式思考”走向“智能体式思考”——前 Qwen 负责人林俊旸(Junyang Lin)最新判断 | DataLearnerAI
Home / Blog List / Blog Detail Junyang 是前 Qwen(通义千问)负责人,前段时间他的离职造成了许多人的关注。不过他并未沉寂,就在刚才,Junyang 发表了一篇关于如何训练大模型推理能力、以及未来大模型推理能力训练应该走向何方的深度讨论。文章里透露了一些关于 Qwen 训练过程中的思考和踩坑经历。原文稍有深度,在这里我们尽量用通俗易懂的语言和大家介绍一下其中的情况。
Follow DataLearner WeChat for the latest AI updates
先说说现在大模型发展到哪了 如果你最近在用各类 AI 产品,可能会有一个感受:现在的 AI 越来越"能干"了,不只是聊天,还能帮你写代码、查资料、做分析,甚至自动完成一套复杂流程。
最早的 GPT-3、GPT-4 这一代,核心逻辑是"读了很多书,所以什么都懂"——依靠海量数据预训练,模型变得博学,但本质上还是"问答机器"。2023 年底到 2024 年,OpenAI 推出 o1,引入了一个新概念:让模型在回答之前先"想一想"。效果在数学、代码、逻辑题上非常显著。DeepSeek-R1 随后跟进,证明这套方法可以被复现,而且成本可以更低。
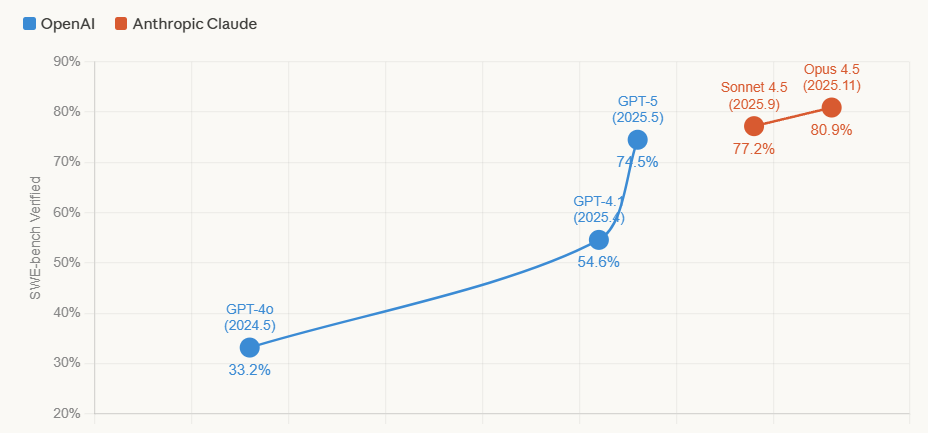
下面这张图,展示了从 GPT-4 到现在,主流模型在编程能力(SWE-bench)这个关键指标上的大致演进——这个数字越高,意味着模型能够独立解决真实世界的软件开发问题:
数据来源参考DataLearner的SWE-Bench Verified评测数据:https://www.datalearner.com/benchmarks/swe-bench-verified
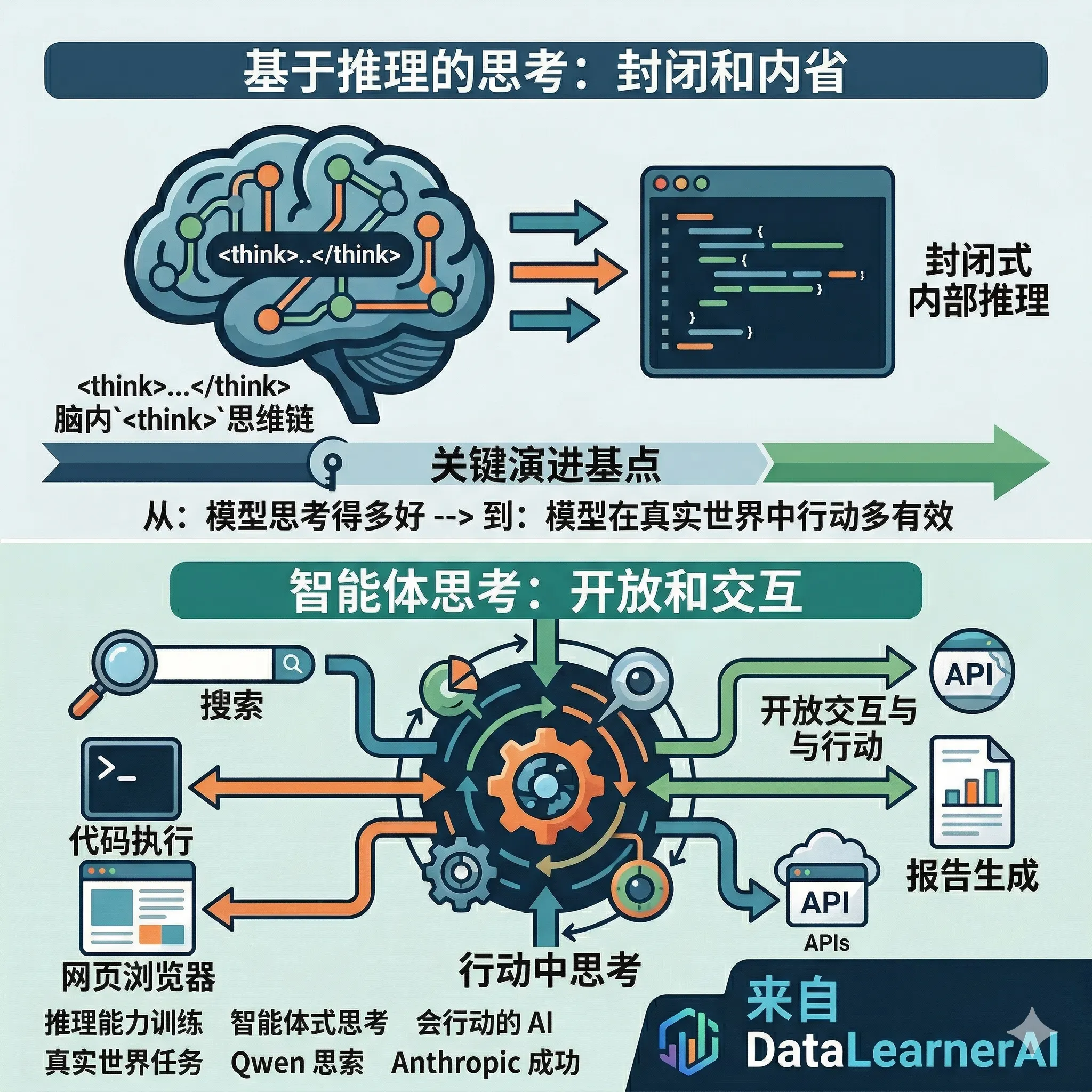
这一阶段,各家 AI 公司基本都在回答同一个问题:怎么让模型"想得更好"? Junyang 认为,这个问题仍然重要,但行业的重心已经开始转移——从"怎么想得更好"走向"怎么在真实环境中边想边做"。他把前者称为"推理式思考"(reasoning thinking) "智能体式思考"(agentic thinking)
一、"让模型学会思考",背后有多难? o1 和 R1 的成功,表面上看是"让模型多想一步",但实际上是一次系统性的工程革命。
强化学习(RL)并不是新技术,但要把它用在语言模型的"思考训练"上,有一个关键前提:你得有可靠的评分标准。 数学题对不对、代码能不能跑通,这些是有标准答案的,机器可以自动判断。这也是为什么早期推理模型的突破,几乎全部发生在数学和代码领域——这两个方向的反馈信号最干净
更关键的是,一旦走上"推理训练"这条路,整个训练基础设施都得跟上:大规模的"模拟推理过程"生成、高吞吐量的自动评分、稳定的模型更新机制……这套东西的复杂程度,不亚于重新搭一套训练系统。
Junyang 的原话是,推理模型的崛起"既是一个建模的故事,也同样是一个基础设施的故事"(as much an infra story as a modeling story)
二、Qwen 团队曾经想做一件很难的事 这里 Junyang 难得地透露了一些 Qwen 内部的决策过程。
2025 年初,Qwen 团队的目标是:把"思考模式"和"对话模式"合并进同一个模型 。理想状态是,模型能自己判断——这个问题简单,直接回答;那个问题复杂,多想一会儿——用户不需要手动切换。Qwen3 是这个思路最完整的一次公开尝试,引入了"混合思考模式",支持可控的思考预算,专门设计了"思考模式融合"阶段。
但 Junyang 坦言,这件事做起来远比想象中难,核心矛盾在于数据 :
做对话(instruct)的数据,追求的是简洁、高效、格式稳定 ,适合企业拿去批量跑客服、标注、摘要这类重复性任务。做思考(thinking)的数据则完全不同,它鼓励模型在中间过程里探索多条路径,允许走弯路再纠正,目标是最终正确率而非过程简洁 。
这两种行为目标在训练数据层面是互相拉扯的。如果数据配比和质量没有精心把控,合并出来的模型很容易两头不讨好:思考模式变得啰嗦但不深入,对话模式变得拖沓但不再干脆。Junyang 也承认,Qwen 团队在平衡模型合并和提升后训练数据质量与多样性的过程中,并没有把所有事情都做对。
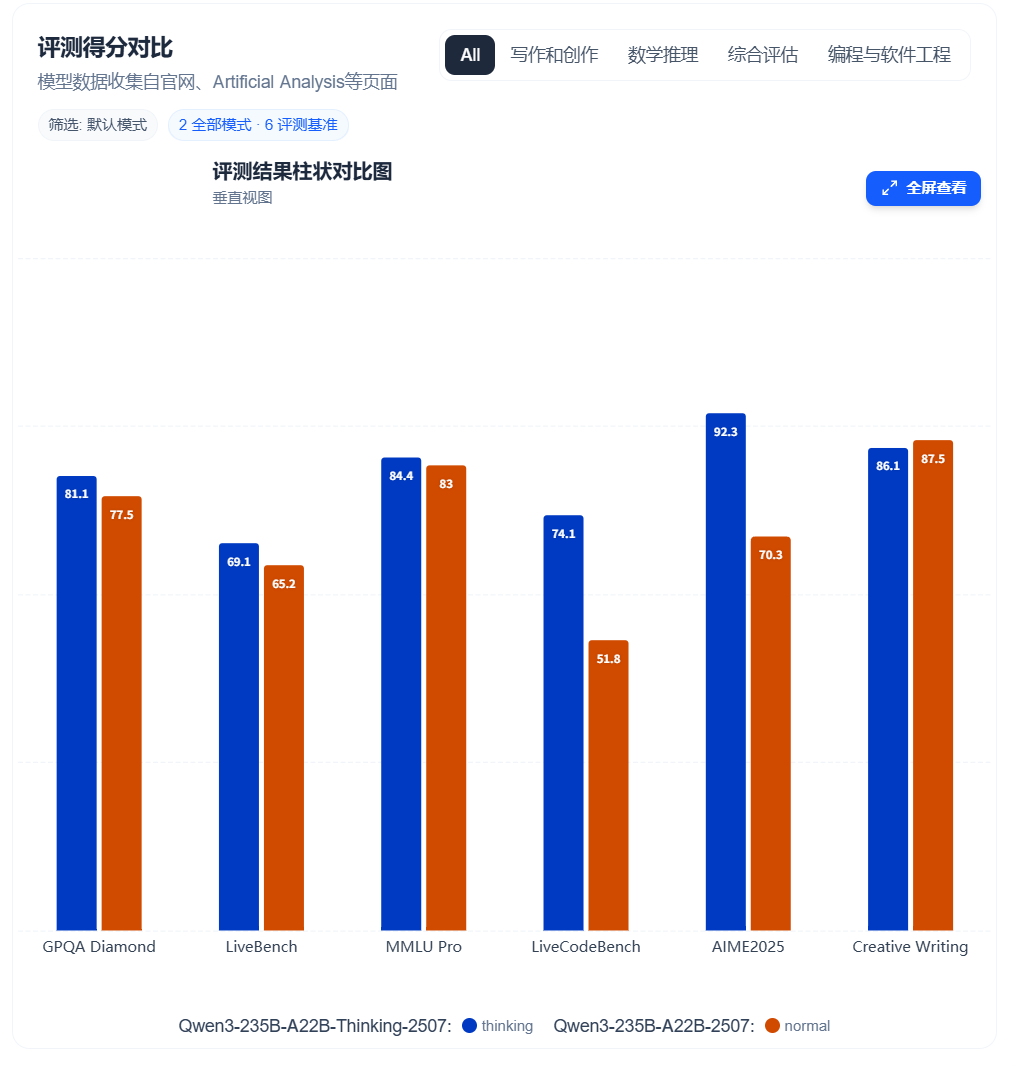
最终在实践中,分开做仍然有很强的吸引力。2025 年 7 月,Qwen 公开发布了 2507 更新 ,将 Instruct 版和 Thinking 版分拆为两条独立产品线,包括 30B 和 235B 的不同规格。Junyang 解释,这么做的一个重要原因是,大量商业客户确实需要纯粹的 instruct 模式——高吞吐、低成本、高度可控——对这些场景来说,合并并不能带来明显好处。分开反而让两个方向各自的数据和训练问题能解决得更干净。
Qwen3-235B-A22B与Qwen3-235B-A22B-Thinking 2507对比:https://www.datalearner.com/benchmark-compare/qwen3-235b-A22b-2507-thinking/Qwen3-235B-A22B-Instruct-2507
Anthropic 则坚持走另一条路:Claude 3.7 Sonnet 和 Claude 4 都是"合并"路线,用户可以手动设定思考预算,Claude 4 甚至允许思考过程中穿插工具调用。GLM-4.5、DeepSeek V3.1 后来也走了类似的混合路线。
那到底谁对谁错?Junyang 的看法是:关键不在于合不合并,而在于合并得是否"有机" 。如果思考和对话只是被塞进了同一个模型、但行为上仍然像两个别扭地缝在一起的人格,用户体验依然是割裂的
三、Anthropic 的克制,提供了一个有用的参照 Junyang 在文中对 Anthropic 的评价比较正面,但他的措辞是"有用的纠偏"(a useful corrective),态度相当克制。
他认为很多团队有一个误区:推理链越长,模型就越聪明。但 Junyang 指出,如果一个模型对所有问题都用同样冗长的方式去推理,这往往说明它不会合理分配计算资源——不知道什么该细想、什么该快速回答、什么时候该停下来动手。
Anthropic 的思路不一样。他们把思考能力跟具体任务目标绑定
Junyang 把这个方向概括为一句话:我们正在从"训练模型"的时代走向"训练智能体"的时代。 他在 Qwen3 的博客里也写过同样的话,并把未来 RL 的进步跟"来自环境的反馈"和"长程推理"联系在了一起。
编者补充: Junyang 原文没有展开讨论 Anthropic 的具体评测成绩,但从公开数据来看,Anthropic 的这条路线在 2025 年确实表现亮眼。Claude Opus 4.5 成为首个在 SWE-bench Verified 上突破 80% 的模型;Claude Sonnet 4.5 在 Artificial Analysis Intelligence Index 上的得分甚至超过了更贵的旧旗舰 Opus 4.1,打破了"更贵就更强"的惯例。Anthropic 发布 Opus 4.6 时,还直接引用了 OpenAI 自己 2025 年 4 月发布的 BrowseComp 基准来展示 Claude 的排名——这种"拿你的尺子量你"的操作在 AI 圈引发了不少讨论。这些成绩某种程度上印证了 Junyang 对 Anthropic 方向的认可。
四、真正的下一步:从"会思考"到"会行动" 这是整篇文章的核心论点。Junyang 认为,智能体式思考将成为主流的思考形式,并且很可能逐步取代那种过度冗长的、封闭式独白型推理
推理式思考 ,是模型在脑子里"打草稿":给一道题,闭门推演很久,输出一个答案。整个过程是封闭的,跟外部世界没有交互。评判标准也相对单一——最终答案对不对。
智能体式思考 ,是模型边做边想:遇到不知道的信息就去搜索,需要验证就执行代码,中间出错了就看错误信息、调整方案再来一遍。整个过程是开放的,跟真实环境持续交互。评判标准变成了——能不能在跟环境持续互动的过程中保持有效推进。
Junyang 在原文里列举了智能体式思考需要具体应对的几个难题:模型得判断什么时候该停下思考、开始行动;得选择调用哪个工具、按什么顺序调用;得处理来自环境的不完整甚至带噪声的观测结果;在行动失败之后得修正计划而不是卡住;还得在跨越很多轮对话和工具调用的过程中保持前后一致。这些是纯推理模型基本不需要面对的挑战。
举个直观的例子:你让 AI 帮你调研竞争对手并生成一份分析报告。在旧模式下,AI 凭训练数据里的存量知识给你写一份可能已经过时的报告。在新模式下,AI 先搜索最新信息,发现数据不够就换个关键词再搜一遍,把结果整理后写成报告,自己检查一遍逻辑,发现某个数据源有矛盾就再去交叉验证——全程不需要你介入。Claude 最新版本、OpenAI 的 Operator、Cursor 和 Devin 这类工具,都已经在朝这个方向走。
五、训练"会行动的 AI",难在哪? 训练一个只会"思考"的模型,评分系统相对简单——答案对不对,机器自动判断就行。但一旦目标变成训练一个跟环境交互的智能体,整个 RL 基础设施都得重新来过。
在传统推理 RL 里,模型的每一轮推演基本上是自包含的,有比较干净的自动评分器。但在智能体 RL 里,模型被嵌入了一个更大的系统:工具服务器、浏览器、终端、搜索引擎、代码执行沙箱、API 接口、记忆系统、调度框架……环境不再是一个静态的判卷老师,它本身就是训练系统的一部分。
Junyang 举了一个很具体的例子:假设你在训练一个编程智能体,它生成的代码需要在一个真实的测试环境里跑。推理端在等执行结果,训练端在等推理端交回完整的轨迹数据,整个流水线的 GPU 利用率远低于传统推理 RL 的预期。再加上工具调用的延迟、环境状态的不确定性,实验迭代速度会急剧下降,"还没到你想要的能力水平,实验就已经慢到做不下去了"。
还有一个更棘手的问题:奖励黑客(Reward Hacking) 。当 AI 只在脑子里推理时,作弊空间有限。但一旦它能调用搜索、执行代码、访问文件,作弊的方式就多了:直接搜到答案而不是真正学会推理;利用代码仓库里的未来信息;找到测试环境的漏洞让自己"看起来"完成了任务。这有点像考试时允许带手机——你很难分清学生是真懂了还是现场查的。
Junyang 认为,下一阶段最严肃的研究瓶颈会集中在训练环境设计、评分器的鲁棒性、反作弊机制、以及策略模型与外部世界之间的接口规范上。他甚至提到,搭建高质量训练环境已经开始成为一个真正的创业方向,而不再只是研究项目的附属品。
六、未来不只是单个智能体,而是智能体组成的系统 原文最后还有一个容易被忽略但很重要的判断:Junyang 认为,智能体式思考发展到后期,核心能力将越来越多地来自多个智能体的组织方式
他描述的架构是这样的:一个负责规划和任务分发的"调度智能体"(orchestrator),若干个具备领域专长的"专家智能体"(specialized agents),以及执行更细碎子任务的"子智能体"(sub-agents)。这些子智能体的存在不仅是为了分工,也是为了控制上下文长度、避免信息污染、在不同层级的推理之间维持清晰的边界。
他把这个演进概括为三级跳:从训练模型,到训练智能体,再到训练由多个智能体构成的系统。
结语:竞争的战场正在转移 Junyang 最后的判断是,AI 领域的竞争逻辑正在发生根本性的变化。
过去两年的核心竞争力在于 RL 算法、反馈信号强度、训练管线的可扩展性。接下来,差距将更多来自训练环境的真实度、训练与推理系统的紧密集成、harness 工程的成熟度,以及能否让模型的决策和决策的后果形成真正的闭环。
或者用 Junyang 自己在结尾的说法:好的思考不再是"最长的或者最显眼的那一种",而是"在真实世界约束下最能推动事情往前走的那一种"。
普通最小二乘法(Ordinary Least Squares,OLS)的详细推导过程