阿里正式开源Qwen3.6-27B:代码智能体能力上超越全面超越前代旗舰版本之 Qwen3.5-397B-A17B
通义千问团队于2026年4月22日发布 Qwen3.6-27B,这是 Qwen3.6 系列的第二款开源模型,也是该系列迄今唯一的稠密架构(Dense)开源版本。模型权重已上传至 Hugging Face 和 ModelScope,同时可通过 Qwen Studio 在线体验,阿里云百炼 API 接入即将开放。

另外,这个图是用最新的GPT-Image-2.0生成的,其实也就一句话,我提供了官方博客链接和DataLearner的模型链接,然后就有这个图片了,实在是强!
Qwen3.6-27B 是什么?与前代有何不同?
Qwen3.6-27B 的核心定位是:以27B参数规模实现此前需要数百B大模型才能达到的代码智能体能力。官方数据显示,它在 SWE-bench Verified、Terminal-Bench 2.0、SkillsBench 等主要编程评测上全面超越 Qwen3.5-397B-A17B——后者的参数量约为其15倍。这是 Qwen 系列在参数效率上的一次明确突破。
与上一代同规模的 Qwen3.5-27B 相比,Qwen3.6-27B 并不是均匀的全面升级,而是有明确方向侧重的迭代:代码智能体(Agentic Coding)和实际工程任务是本次的核心发力点,通用知识能力大体持平。
稠密架构:部署比 MoE 更简单直接
Qwen3.6-27B 是稠密(Dense)模型,与同系列的 Qwen3.6-35B-A3B(MoE 混合专家架构)不同,稠密模型的全部参数在每次推理时都参与计算,不需要像 MoE 模型那样在多个"专家模块"之间动态分配任务,部署和调试更加直接,主流推理框架(vLLM、SGLang、llama.cpp)均可直接支持,对私有化部署团队更加友好。
27B 的参数规模也是目前开源社区中部署最广泛的档位,消费级多卡环境(如双张24G显卡)可以运行量化版本,这是许多团队在稠密架构和更大 MoE 模型之间的现实选择依据之一。
思考模式与思考保留:一段"合→拆→合"的演进历史
这里我们还发现一个有意思的点,那就是Qwen3.6-27B又回到“老思考模式”了。
Qwen2.5 时代,推理能力和对话能力由两个完全独立的模型承担:QwQ-32B 负责深度推理,Qwen2.5-Instruct 系列负责日常对话,开发者需要根据任务类型切换不同的模型。Qwen3(2025年4月)首次将两种模式统一进同一个模型,通过特殊指令 /think 和 /no_think 即可在推理和对话模式之间切换,无需换模型——这在工程上是有实质意义的进步,意味着深度推理能力和流畅对话能力可以在同一个模型内共存而不互相拖累。
然而,2025年7月,Qwen 团队又发布了纯推理专用和没有思考模式的 Qwen3 Instruct系列,但主要是MoE架构的版本,不过Qwen3-32B这种稠密模型依然只有一个模型,比较奇怪。
Qwen3.6延续了稠密模型支持思考和非思考模式2种。同时,在此基础上新增了**思考保留(Thinking Preservation)**机制:在多轮对话的智能体场景中,模型可以把前几轮的推理过程保留下来供后续轮次参考,而不是每轮都从头推理。这在代码调试、逐步分解复杂任务等场景中,能明显减少重复推理,降低响应延迟和 token 消耗。
模型支持的最长上下文为262,144个 token(约20万字),并可扩展至约100万 token,足以容纳大型代码仓库的完整内容。
原生多模态:图像、视频与文本统一理解
Qwen3.6-27B 是一个原生多模态模型,同一个模型同时支持文本、图片甚至视频等多模态输入,无需搭配额外的视觉模型。支持文档理解、图表分析、视觉问答、空间推理等任务,视觉理解能力同样支持思考和非思考两种模式,与纯文本侧保持一致的使用体验。
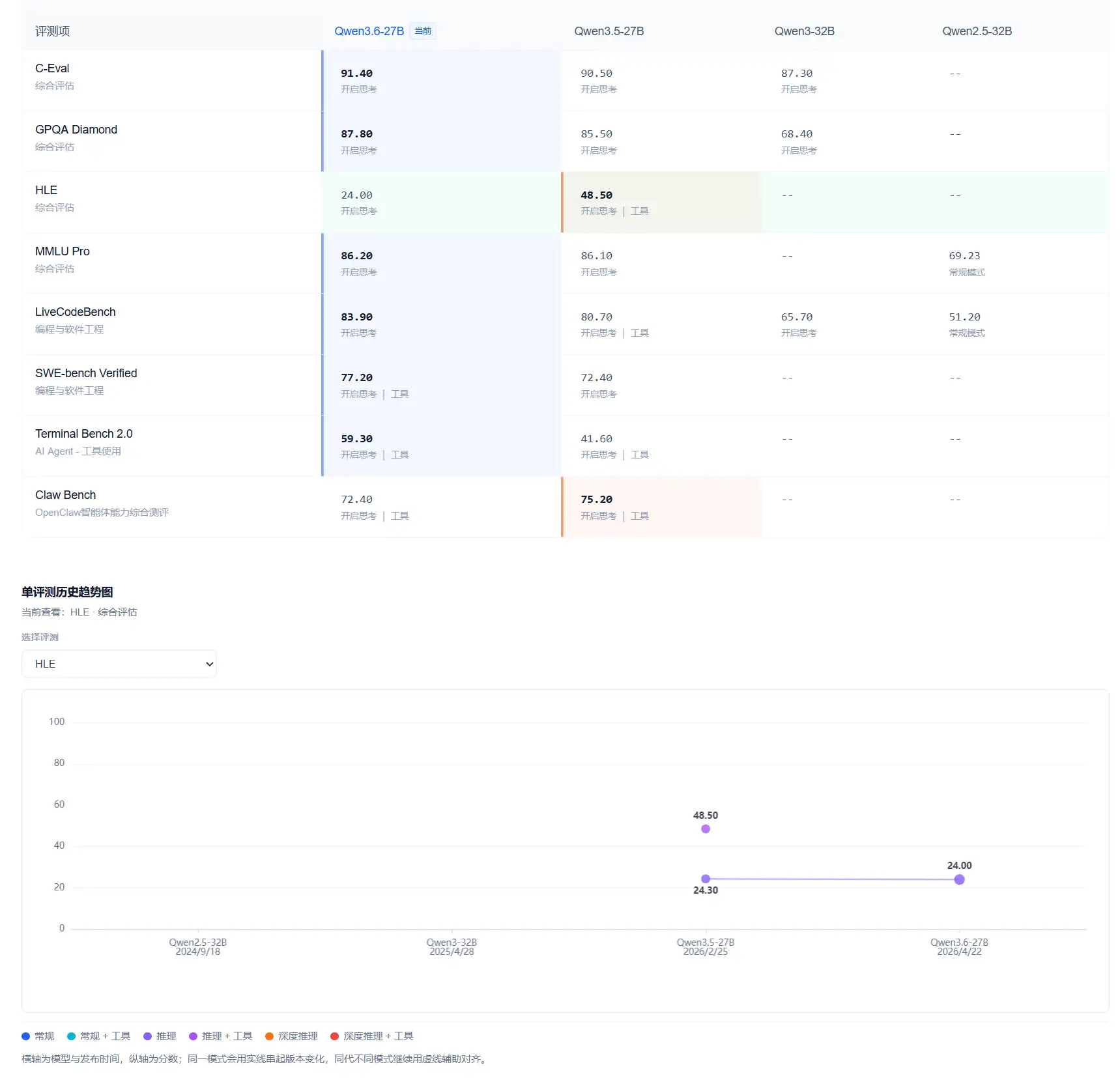
Qwen3.6的评测结果:通用能力没有明显变化,但智能体水平提升明显
在 DataLearner 收录的评测数据中,Qwen3.6-27B 在编程和数学推理维度表现突出。编程侧:LiveCodeBench 83.9(全库第13/112),SWE-bench Verified 77.2(第16/97),Terminal Bench 2.0 59.3(第14/36),三项均全面超越参数量是其15倍的 Qwen3.5-397B-A17B。数学推理方面,AIME 2026 得分94.1。综合知识维度,GPQA Diamond 87.8,MMLU Pro 86.2,C-Eval 91.4,较前代均有小幅提升或持平。
具体如下图所示:
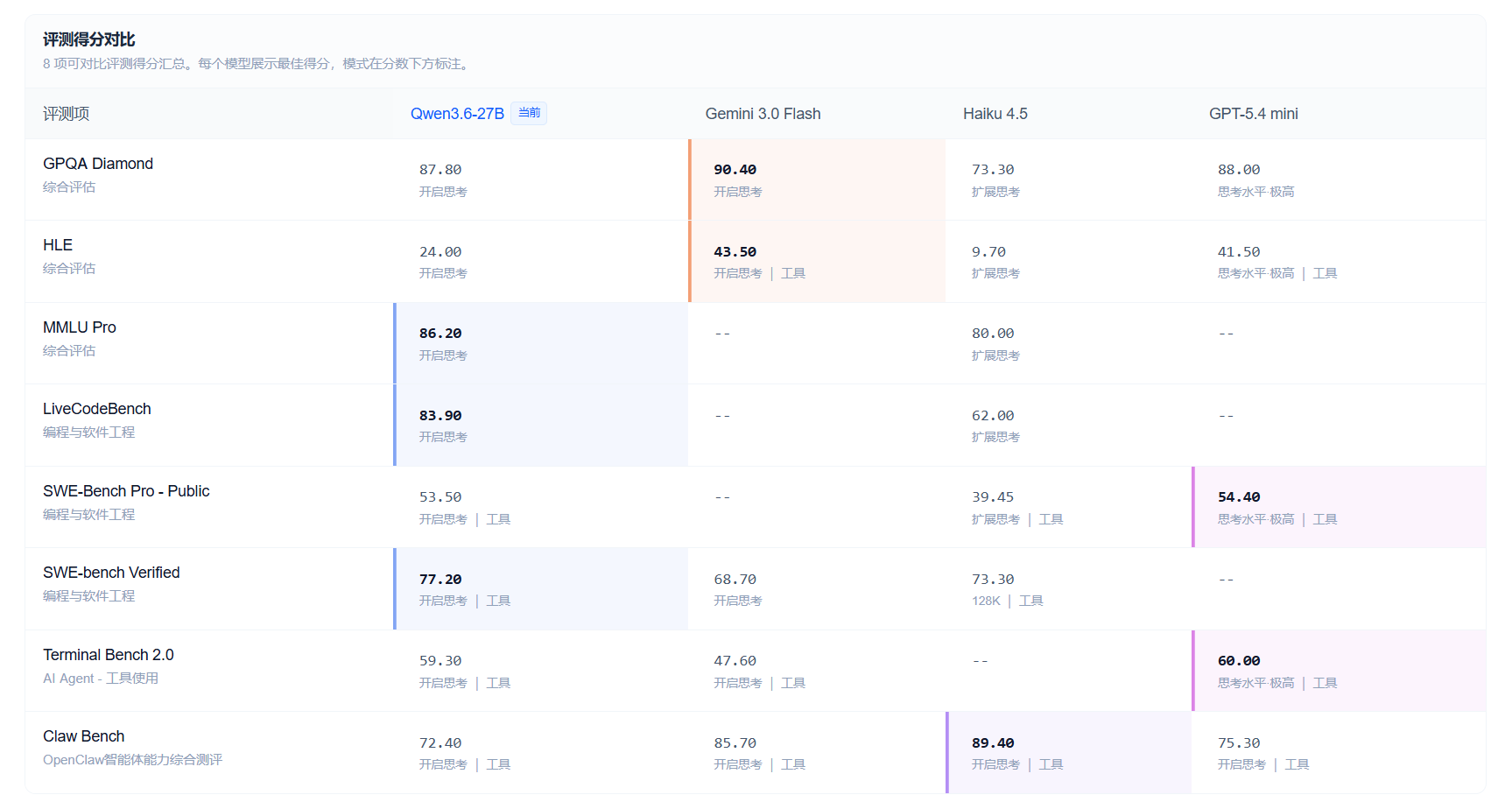
与同类规模竞品横向对比,可以看到,与gemini 3.0 flash、haiku 4.5以及GPT-5.4 mini相比各有优劣吧,应该可以称得上是同一水平差不多的模型,只是能力侧重有差异。
HLE(顶尖专家综合推理)得分24.0,较 Qwen3.5-27B 的24.3在相同条件下略有下降,与397B前代的28.7也仍有差距——这一能力方向尚需后续版本持续跟进。
Qwen 3.6-27B完全开源,可以免费使用
模型权重已在 Hugging Face(Qwen/Qwen3.6-27B)和 ModelScope 公开发布,支持通过 vLLM、SGLang 等框架自行部署。推理时建议保持至少128K token 的上下文长度,以充分发挥思考模式的推理能力。在线体验可直接访问 Qwen Studio。阿里云百炼 API(模型名 qwen3.6-27b)接入正在准备中,同时兼容 OpenAI 和 Anthropic 两种接口规范,方便已有项目直接对接。
本文数据来源:Qwen 官方发布博客(2026年4月22日)及 DataLearner 评测数据库。完整评测得分与竞品对比图表见 Qwen3.6-27B 评测分析页。
