Voicebox
Voicebox 是由 Facebook AI研究实验室 发布的 AI 模型,发布时间为 2023-06-16,定位为 基础大模型,参数规模约为 3.72B,上下文长度为 2K,模型文件大小约 0GB,采用 不开源 许可。
数据优先来自官方发布(GitHub、Hugging Face、论文),其次为评测基准官方结果,最后为第三方评测机构数据。 了解数据收集方法
Voicebox是由MetaAI发布的一个类似大语言模型的生成式语音模型。它是一种基础模型,可以完成类似大语言模型的功能,可以针对语音数据进行编辑、补充、去噪音等。是语音数据处理的一个里程碑式的大模型。
Voicebox的目的也是建立一个类似LLM的训练机制,创建一个生成式的模型。
与LLM不同的是,Voicebox使用的是语音和对应文本记录数据。它的训练目标是根据音频周围的数据和相关的文本记录数据来预测目标音频。这也可以当作是一种情景学习,其中语音的风格是来自于音频情景和文本内容。
Voicebox不需要任何音频的风格标注数据(包括录制人的信息、感情、噪音等),对音频数据要求很低,这些音频数据更加容易获得。因此可以很容易在更大规模数据集上训练。
Voicebox本身不是一个自回归模型,而是一个连续正规化流模型(continuous normalizing flow,CNF)。有点像CV领域的扩散模型。它的目的是对一种转化方式进行建模。这个转化方式的目的是可以将一个简单的分布转换成复杂的数据分布。
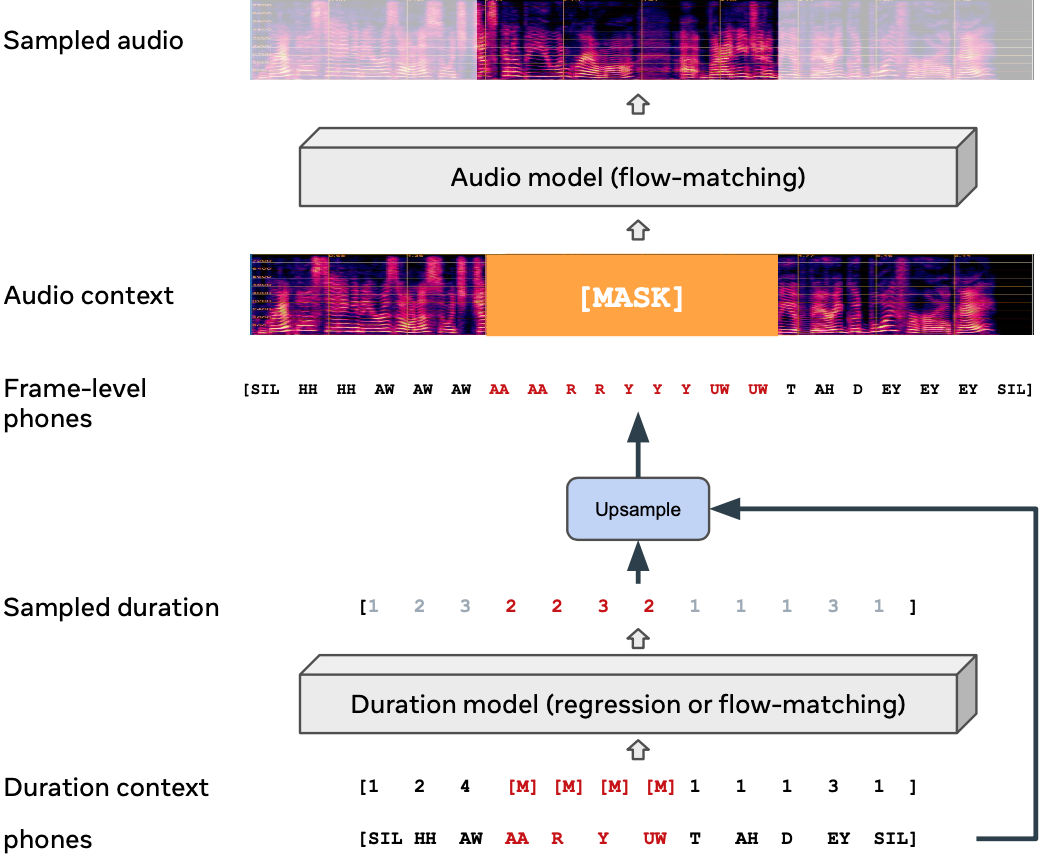
上图是Voicebox的模型示意图。
Voicebox在6万小时的英语音频和5万小时多语音音频数据上训练。支持英语、法语、西班牙语、德语、波兰语和葡萄牙语。
根据官方的描述,Voicebox是一种音频处理的突破性方式。它通过学习解决类似大语言模型的训练方法,实现了音频领域的大规模训练,可以通过情景学习的方式来完成没有训练过的任务。
Voicebox的效果超过了此前的所有模型。在zero-shot的英文语音合成任务上,已经将此前的单词错误率从5.9%下降到1.9%(此前英文领域的zero-shot的TTS表现最好的应该是VALL·E)。
Voicebox也是第一个可以完成高质量跨语言的zero-shot的语音合成模型,它不需要对语音数据集进行风格、录制者相关的标注即可完成相关的训练。大大降低了训练模型对于语音数据集的质量要求。
Voicebox在如下任务中表现很好:
即给定一段文本和转录参考语音,直接生成此前没有训练过的语音风格的音频结果。
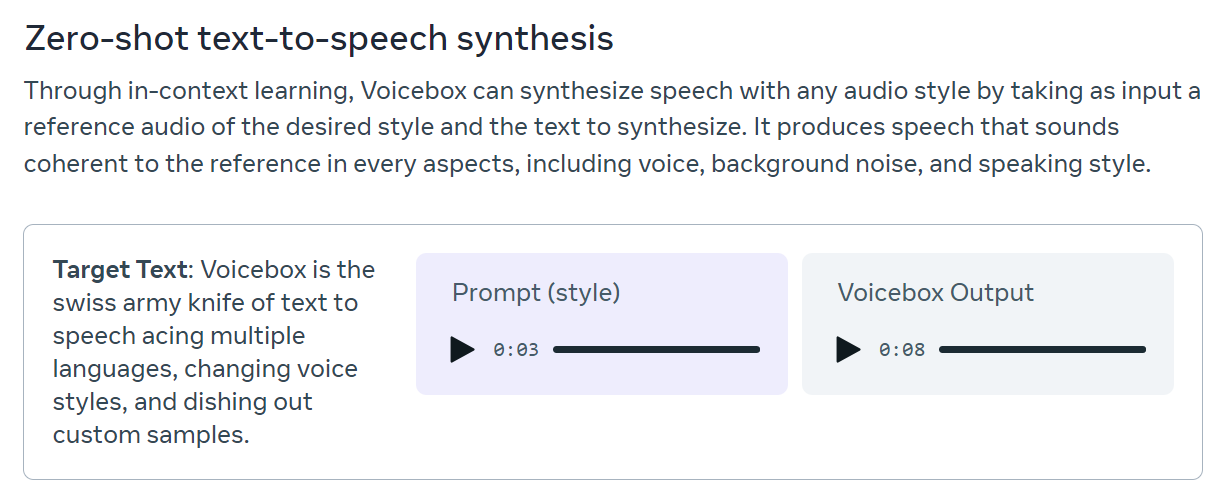
上图就是一个案例,给出这个文本,还有一个3秒的语音风格,它就可以基于这段文本生成一段音频,其声音、背景噪音和语速等都是与这3秒的转录音频类似,但是可以完全生成这段文本对应的结果!效果很好!
如果你有一段音频,但是里面包含狗叫或者关门声音,那么Voicebox也可以帮你去除。
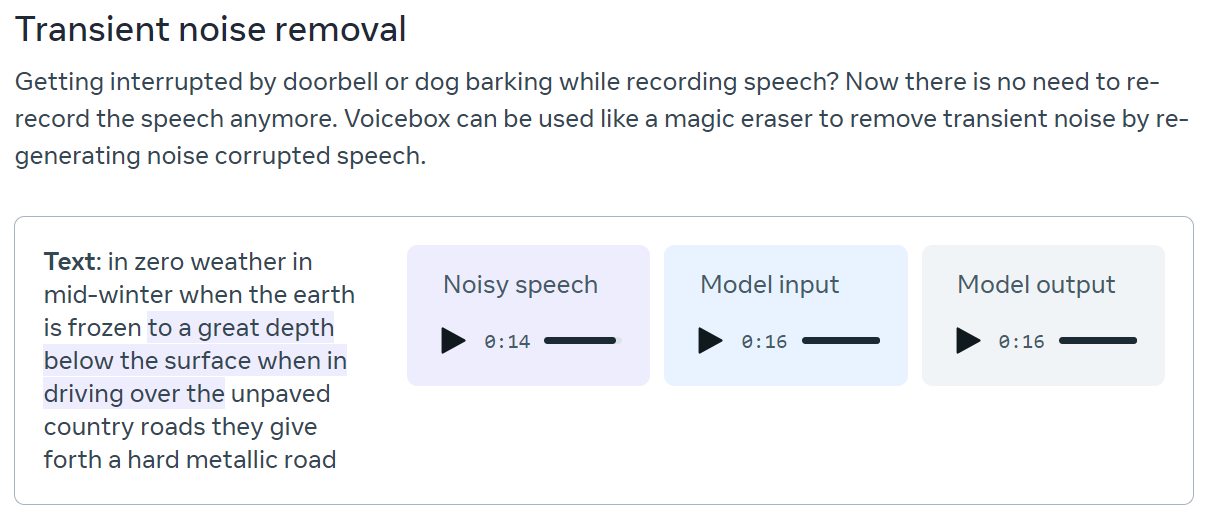
上图的案例是你有一段16秒音频,是左侧文本内容。但是阴影部分的文本有狗叫的背景,很难听清楚,那么你给模型这段16秒的音频,把其中有狗叫的部分静音掉。Voicebox就可以把这部分的音频补充进来,但是完全去掉狗叫声的噪音。
这个案例是指如果录音的内容有错,那么可以不用录制者重新录制既可以将部分内容换成需要的音频结果,但是你听不出来这中间有编辑过。

上图的左侧是原录音和源文本,阴影部分是想要重新录制的内容,可以用voicebox直接替换。但是音频结果非常丝滑。
这个。。。不就是如果某位演员出问题了,或者台词出问题了,重新配音就可以用这个模型来了,完全听不出来是后期补录的结果啊!
官方还有很多案例,大家可以亲自体验:https://voicebox.metademolab.com/
相信此时大部分人都知道,这个模型的能力虽然很好,但是也很可怕。如果模型不被控制,在诈骗、造谣等方面完全就无法控制。因此MetaAI虽然发布了论文,但是没有开源代码和预训练结果。但是为了不影响开源共享,MetaAI在论文里面详细描述了Voicebox模型。
但是,根据开源的速度,应该很快会有社区版本发布。而基于开源数据的训练结果很可能也会发布。这虽然令人期待,但是也不免让大家担心会出现很多问题!
论文中,MetaAI也描述了如何区分是Voicebox生成的音频还是真实音频,想必也是担心它的影响。
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送

暂时没有为该模型整理的相关对比页面。
想自定义其他组合?打开对比工具