Java爬虫入门简介(三) —— Jsoup解析HTML页面
上一篇博客我们已经介绍了如何使用HttpClient模拟客户端请求页面了。这一篇博客我们将描述如何解析获取到的页面内容。
上一节我们获取了 http://www.datalearner.com/blog_list 页面的HTML源码,但是这些源码是提供给浏览器解析用的,我们需要的数据其实是页面上博客的标题、作者、简介、发布日期等。我们需要通过一种方式来从HTML源码中解析出这类信息并提取,然后存到文本或者数据库之中。在这篇博客中,我们将介绍使用Jsoup包帮助我们解析页面,提取数据。
Jsoup是一款Java的HTML解析器,可以直接解析某个URL地址,也可以解析HTML内容。其主要的功能包括解析HTML页面,通过DOM或者CSS选择器来查找、提取数据,可以更改HTML内容。Jsoup的使用方式也很简单,使用Jsoup.parse(String str)方法将之前我们获取到的HTML内容进行解析得到一个Documend类,剩下的工作就是从Document中选择我们需要的数据了。举个例子,假设我们有个HTML页面的内容如下:
<html>
<div id="blog_list">
<div class="blog_title">
<a href="url1">第一篇博客</a>
</div>
<div class="blog_title">
<a href="url2">第二篇博客</a>
</div>
<div class="blog_title">
<a href="url3">第三篇博客</a>
</div>
</div>
</html>
通过Jsoup我们可以把上面的三篇博客的标题提取到一个List中。使用方法如下:
首先,我们通过maven把Jsoup引入进来
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
然后编写Java进行解析。
package org.hfutec.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
List<String> titles = new ArrayList<String>();
List<String> urls = new ArrayList<String>();
//假设我们获取的HTML的字符内容如下
String html = "<html><div id=\"blog_list\"><div class=\"blog_title\"><a href=\"url1\">第一篇博客</a></div><div class=\"blog_title\"><a href=\"url2\">第二篇博客</a></div><div class=\"blog_title\"><a href=\"url3\">第三篇博客</a></div></div></html>";
//第一步,将字符内容解析成一个Document类
Document doc = Jsoup.parse(html);
//第二步,根据我们需要得到的标签,选择提取相应标签的内容
Elements elements = doc.select("div[id=blog_list]").select("div[class=blog_title]");
for( Element element: elements ){
String title = element.text();
titles.add(title);
urls.add(element.select("a").attr("href"));
}
//输出测试
for( String title: titles ){
System.out.println(title);
}
for( String url: urls ){
System.out.println(url);
}
}
}
我们简单说明一下Jsoup的解析过程。首先第一步都是调用parse()方法将字符对象变成一个Document对象,然后我们对这个对象进行操作。一般提取数据就是根据标签选择数据,使用select()方法语法格式和 javascript/css 选择器都是一样的。一般都是提取某个标签,其属性值为指定内容。得到的结果是一个Element的集合,为Elements(因为符合条件的标签可能很多,所以结果是一个集合)。select()方法可以一直进行下去,直到选择到我们想要的标签集合为止(注意,我们并不一定要按照标签层级一级一级往下选,可以直接写select()方法到我们需要的标签的上一级,比如这里的示例代码可以直接写成 Elements elements = doc.select("div[class=blog_title]"); 其效果是一样的)。对于选择到的Elements的集合,我们可以通过循环的方式提取每一个需要的数据,比如,我们需要拿到标签的文本信息,就可以使用text()方法,如果我们需要拿到对应的HTML属性信息,我们可以使用attr()方法。我们可以看到上述方法的输出结果如下:
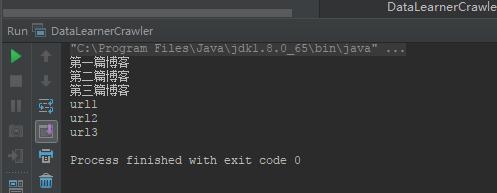
更多的Jsoup解析的操作可以参考如下: 1、https://www.ibm.com/developerworks/cn/java/j-lo-jsouphtml/index.html 2、https://jsoup.org/
一个实例
我们接着上一个爬取数据学习官方网站博客列表的例子讲解一个实例。我们已经知道可以使用Jsoup来解析爬取到的HTML页面内容。那么如何查看我们需要的内容对应的标签呢?以Chrome浏览器为例,我们需要爬取 http://www.datalearner.com/blog_list 这个页面的的博客,首先用Chrome浏览器打开这个网址,然后鼠标右键单击博客的标题,点击“检查”就可以得到HTML页面了。如下图所示。

图2 右键单击标题

图3 点击所在元素的父级元素边上的小三角,收起代码查看

通过上述操作之后,我们已经可以看到,所有的博客的标题等信息都存在class=card的div里面了。于是,我们只要关注这个标签里面的内容是如何组织的,就可以了。如下图所示,我们需要的信息所属的标签,通过点击小三角展开就能得到了。

因此,解析博客列表的代码可以写成如下形式了。
package org.hfutec.example;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
String url = "http://www.datalearner.com/blog_list";
String rawHTML = null;
try {
rawHTML = getHTMLContent(url);
} catch (IOException e) {
e.printStackTrace();
}
//将当前页面转换成Jsoup的Document对象
Document doc = Jsoup.parse(rawHTML);
//获取所有的博客列表集合
Elements blogList = doc.select("div[class=card]");
//针对每个博客内容进行解析,并输出
for( Element element: blogList ){
String title = element.select("h4[class=card-title]").text();
String introduction = element.select("p[class=card-text]").text();
String author = element.select("span[class=fa fa-user]").text();
System.out.println("Title:\t"+title);
System.out.println("introduction:\t"+introduction);
System.out.println("Author:\t"+author);
System.out.println("--------------------------");
}
}
//根据url地址获取对应页面的HTML内容,我们将上一节中的内容打包成了一个方法,方便调用
private static String getHTMLContent( String url ) throws IOException {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet(url);
//获取网址的返回结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity);
//关闭HttpEntity流
EntityUtils.consume(entity);
return content;
}
}
最终的输出结果如下图所示:

DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
