提炼BERT——将BERT转成小模型(Distilling BERT — How to achieve BERT performance using Logistic Regression)
BERT是很好的模型,但是它的参数太大,网络结构太复杂。在很多没有GPU的环境下都无法部署。本文讲的是如何利用BERT构造更好的小的逻辑回归模型来代替原始BERT模型,可以放入生产环境中,以节约资源。
本文原文发表在Medium上,这是翻译。原文可参考末尾引用。
BERT太棒了,无处不在。看起来任何NLP任务都可以从利用BERT中受益。作者表明情况确实如此,根据我的经验,它就像魔术一样。它易于使用,可处理少量数据并支持多种不同语言。似乎没有任何理由不在任何地方使用它。但实际上,有。不幸的是,在实践中,它并非如此微不足道。 BERT是一个巨大的模型,超过1亿个参数。我们不仅需要GPU来微调它,而且在推理时,CPU(甚至其中很多)还不够。这意味着如果我们真的想在任何地方使用BERT,我们需要在任何地方安装GPU。在大多数情况下这是不切实际的。 2015年,Hinton等人介绍了一种方法,将一个非常大的神经网络的知识提炼成一个更小的神经网络。方法很简单。我们使用大的神经网络来训练小的网络。主要思想是使用原始预测特征,即在最终激活函数之前的输出(通常是softmax或sigmoid)(解释一下,就是把原始网络最后一层的输出给去掉,用前面生成的输出结果)。假设通过使用原始值,模型能够比使用“硬”预测更好地学习内部表示。 Sotmax将值归一化为1,同时保持最大值,并将其他值减小到非常接近零的值。零中的信息很少,因此通过使用原始预测,我们也可以从未预测的类中学习。作者在包括MNIST和语音识别在内的几个任务中表现出了良好的效果。
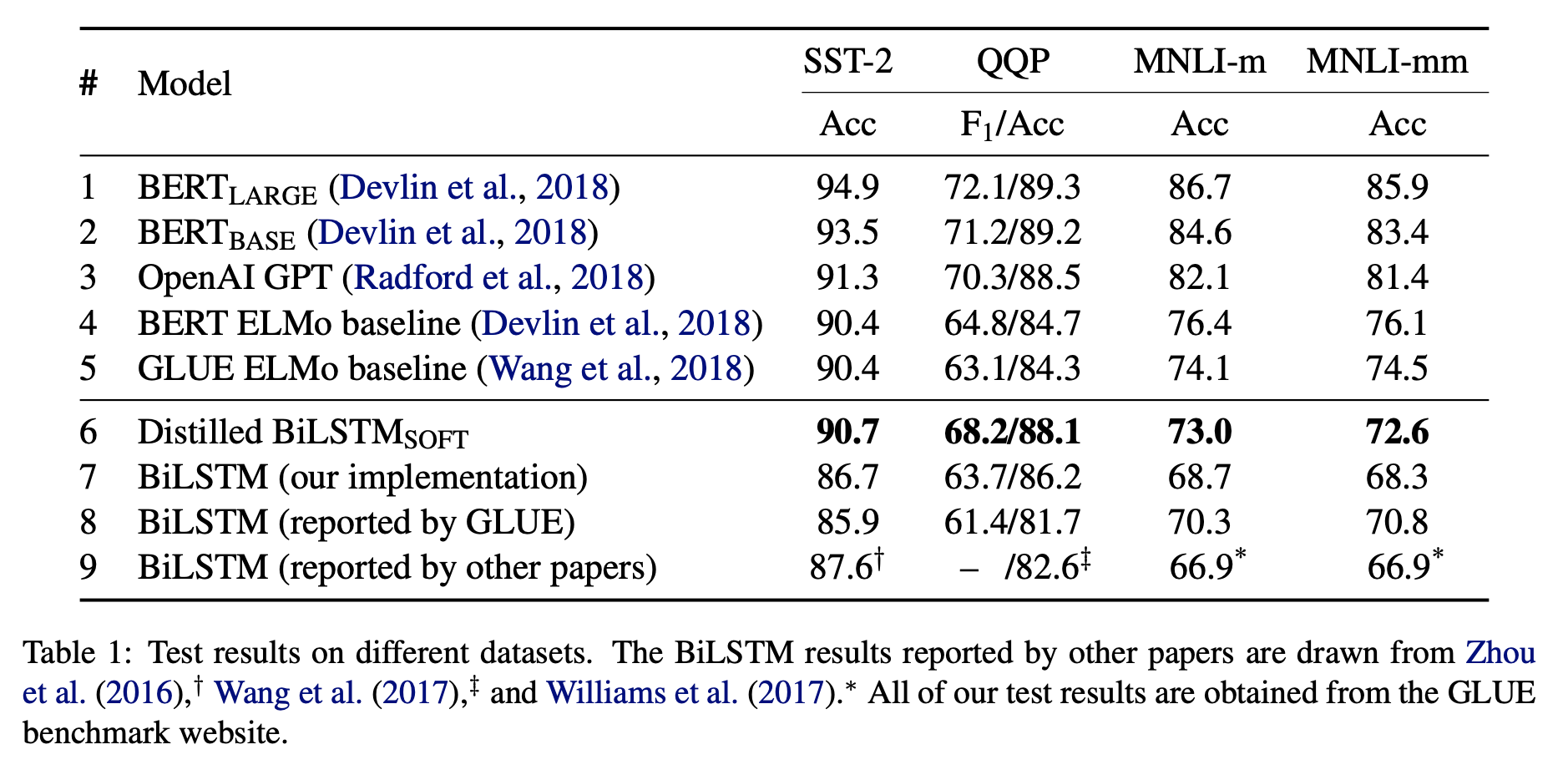
不久前,本文作者将同样的方法应用于...... BERT! 它们表明,通过将信息从BERT提取到更小的BiLSTM神经网络中,我们可以在特定任务上获得相同的性能(甚至更好)。 您可以在下表中看到他们的结果。 使用BiLSTM-Soft实现了最佳性能,这意味着“软预测”,即对原始logit进行训练而不是“硬”预测。 数据集是:SST-2是Stanford Sentiment Treebank 2,QQP是Quora Question Pairs,MNLI是多种类型的自然语言推断。
在这篇文章中,我想将BERT提炼成一个更简单的Logistic回归模型。 假设您有一个相对较小的标记数据集和一个更大的非标记数据集,构建模型的一般框架是:
- 在标记的数据集上创建一些基准模型
- 通过在标记集上微调BERT来构建一个大模型
- 如果您获得了良好的结果(优于基准模型),请使用大型模型计算未标记集的原始数据
- 在现在伪标记的集合上训练一个小得多的模型(Logistic回归)
- 如果您获得了良好的效果,请将小型模型部署
我想解决相同的任务(IMDB评论情感分类)但使用Logistic回归。 您可以在此笔记中找到所有代码。
和以前一样,我将使用torchnlp加载数据和PyTorch-Pretrained-BERT来构建模型。
训练集中有25,000条评论,我们将仅使用1000作为标记集,另外5,000作为未标记集(我还从测试集中仅选择1000条评论来加快速度):
train_data_full, test_data_full = imdb_dataset(train=True, test=True)
rn.shuffle(train_data_full)
rn.shuffle(test_data_full)
train_data = train_data_full[:1000]
test_data = test_data_full[:1000]
我们要做的第一件事是使用逻辑回归创建基准模型:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.metrics import classification_report
## Get the texts and the labels from data
######################################################
train_texts, train_labels = list(zip(*map(lambda d: (d['text'], d['sentiment']), train_data)))
test_texts, test_labels = list(zip(*map(lambda d: (d['text'], d['sentiment']), test_data)))
## Train model and predict
######################################################
baseline_model = make_pipeline(CountVectorizer(ngram_range=(1,3)), LogisticRegression())
baseline_model = baseline_model.fit(train_texts, train_labels)
baseline_predicted = baseline_model.predict(test_texts)
print(classification_report(test_labels, baseline_predicted))
我们得不到那么好的结果:
precision recall f1-score support
neg 0.80 0.80 0.80 522
pos 0.78 0.79 0.78 478
accuracy 0.79 1000
下一步,是微调BERT,我将跳过这里的代码,你可以在我之前的帖子中看到笔记本或更详细的教程。 结果是一个名为BertBinaryClassifier的训练模型,它使用BERT,然后使用线性层来提供pos / neg分类。 该模型的性能如下:
precision recall f1-score support
neg 0.88 0.91 0.89 522
pos 0.89 0.86 0.88 478
accuracy 0.89 1000
好多了! 正如我所说 - 魔术:)
现在到了有趣的部分,我们使用未标记的集合并使用我们的微调BERT模型“标记”它:
## We use another 5000 reviews as unlabeled data
################################################################
unlabeled_data = train_data_full[1000:6000]
unlabeled_texts, _ = list(zip(*map(lambda d: (d['text'], d['sentiment']), unlabeled_data)))
unlabeled_tokens = list(map(lambda t: ['[CLS]'] + tokenizer.tokenize(t)[:511], unlabeled_texts))
unlabeled_tokens_ids = list(map(tokenizer.convert_tokens_to_ids, unlabeled_tokens))
unlabeled_tokens_ids = pad_sequences(unlabeled_tokens_ids, maxlen=512, truncating="post", padding="post", dtype="int")
unlabeled_masks = [[float(i > 0) for i in ii] for ii in unlabeled_tokens_ids]
unlabeled_tokens_tensor = torch.tensor(unlabeled_tokens_ids)
unlabeled_masks_tensor = torch.tensor(unlabeled_masks)
## We "predict" the raw logits using the fine-tuned BERT model
####################################################################
unlabeled_dataset = TensorDataset(unlabeled_tokens_tensor, unlabeled_masks_tensor)
unlabeled_dataloader = DataLoader(unlabeled_dataset, batch_size=BATCH_SIZE)
bert_clf.eval()
unlabeled_logits = []
with torch.no_grad():
for step_num, batch_data in enumerate(unlabeled_dataloader):
token_ids, masks = tuple(t.to(device) for t in batch_data)
logits = bert_clf(token_ids, masks)
numpy_logits = logits.cpu().detach().numpy()
unlabeled_logits.append(numpy_logits)
unlabeled_logits = np.vstack(unlabeled_logits)
## Finally, we train the logistic regression model on the pseudo-labeled data
###############################################################################
unlabeled_model = make_pipeline(CountVectorizer(ngram_range=(1,3)), LinearRegression())
unlabeled_model = unlabeled_model.fit(unlabeled_texts, unlabeled_logits)
unlabele_predicted_logits = unlabeled_model.predict(test_texts)
print(classification_report(test_y, sigmoid(unlabele_predicted_logits[:, 0]) > 0.5))
我们得到:
precision recall f1-score support
neg 0.87 0.89 0.88 522
pos 0.87 0.85 0.86 478
accuracy 0.87 1000
没有原来经过微调的BERT那么好,但它比基线要好得多! 现在我们已经准备好将这个小型模型部署到生产中,并享受良好的质量和推理速度。
