AI系统中(机器学习算法)导致偏差的原因总结
基于算法的业务或者说AI的应用在这几年发展得很快。但是,在实际应用的场景中,我们经常会遇到一些非常奇怪的偏差现象。例如,Facebook将黑人标记为灵长类动物、城市图像识别系统将公交车上的董明珠形象广告识别为闯红灯的人等。算法系统出现偏差的原因有很多。本篇博客将总结在数据获取相关方面可能导致模型出现偏差的原因。
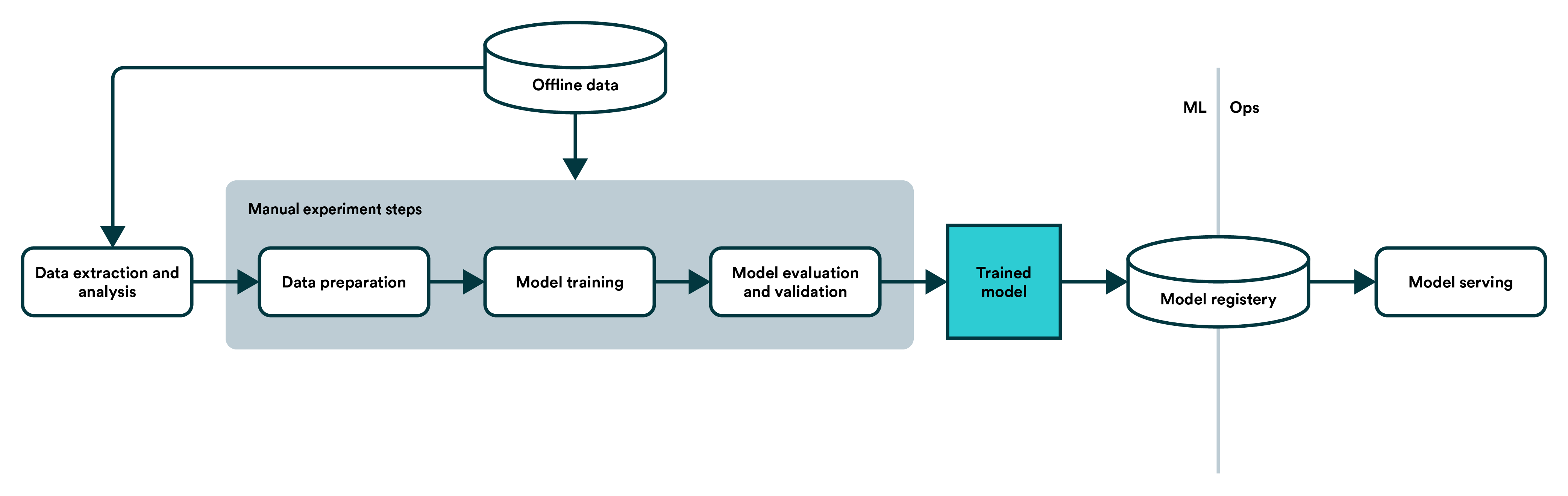
一个典型的AI系统(本文不区分算法和AI,虽然实际中二者的确不一样)的工作过程包括:
- 收集数据
- 标记数据
- 数据预处理
- 模型训练和测试
- 模型上线
因此,这些步骤中都可能会出现一些问题导致最终的应用出现偏差。本文将主要聚焦前三种情况。
数据创造的偏差是最常见的问题,这里也包括几种情况:数据收集阶段产生的偏差、数据标记过程产生的偏差和数据预处理过程中产生的偏差。
一、数据收集产生的偏差
一般来说,这是由于数据收集过程中由于一些错误的认知或者忽视,导致一开始就是从一个“特别的”地方收集了数据。最后导致了问题的产生。前几年,AICon北京站中,小米的工程师分享了一个案例就是这个原因。大意是小米相机想推出一个“魔法换天”的功能。于是从数据收集开始准备训练模型。但是数据收集的过程中忽略了大多数用户并不是专业的摄影师,拍照的角度五花八门,也不规则。但是收集的数据确是比较准确的摄影师的作品。这最终导致模型只认识质量很高的照片,最终实际应用效果非常差。这就是典型的数据收集导致的偏差问题。在实际应用中,我们需要尽可能针对应用场景收集符合实际业务的数据,避免产生意想不到的结果。

此外,除了一开始收集产生的偏差。有时候抽样选择也会导致偏差。抽样选择是数据收集的一个重要的过程。很多时候并不是所有的原始数据都会被使用,数据抽样是一个重要的步骤。但是,抽样一般容易产生偏差。例如,在一个浅色皮肤较多的照片中,如果抽样对深色皮肤的图像不够重视,很容易出现最终的结果都是浅色人的图像,进而可能会产生Facebook那样的错误。
二、标记数据过程产生的偏差
收集完数据之后,大多数的应用需要对数据进行标注。尤其是在分类预测的任务中,需要对数据进行正确的划分,才能有效地训练模型。在这个过程也是很容易出错的。当前,在工业界,除了寻找公开的高质量数据集进行模型训练外,也会有很多企业尝试自己标注数据来适应业务的发展。然而这个时候出现偏差的可能也很高。依然是小米的例子,在换天这样的应用中,一个很重要的步骤是需要将背景中天空的轮廓识别出来。最开始标注数据的时候选择的标注工具和标注人员都是很粗略的。导致天空轮廓标记很粗糙。尤其是在有树叶这种场景下,边缘的模糊导致标记结果非常粗糙。在实际训练中也就产生了很大的问题。因此,数据标注如果要自己完成,一定需要注意质量的问题。

数据标记可能的偏差原因:
- 标签的差异(例如男性和男人,其实是一种标签,但是给了两种单词)
- 标注者思想的差异:包括标注者自身的文化、认知、信仰等导致的差异
- 标注者记忆的差异:这种情况主要发生在一些需要标注者记忆的情况中,例如一些问卷或者是认知识别的标注,可能标注者会出现前后不一致的情况
三、数据预处理产生的偏差
数据预处理过程产生的偏差有一点类似数据抽样选择过程。很多时候,数据预处理包括空值处理、异常值处理等步骤。在这些步骤中,对于一些错误或者偏差较大的数据,很多人习惯选择用均值填补甚至是删除的操作来对待错误和异常数据,但这是很容易出现偏差的地方。例如,假设我们在处理一份关于流量历史的数据。这种数据在一些突发时间或者特殊节点会出现很高的异常值的情况。大多数人愿意选择删除这些数据节点。当然,在比赛中,这种操作通常会带来总体性能的提升。但是在实际业务中却可能会造成很大的错误。例如,如果流量估计忽略了节假日因素,那么很多时候会让我们的广告投放或者是资源调度出现很大的问题。
四、总结
模型出现偏差,数据可能是最重要的原因。从数据收集开始,就有很多地方值得我们注意。避免使用错误的数据和错误的处理方式来产生坏结果。不仅浪费时间,也浪费感情。所以大家平时一定要注意。
