关于算法的时间复杂度的简单理解
在程序设计和编程中,我们经常会看到关于时间复杂度的讨论。比如为什么A方法比B方法好?是因为A方法的时间复杂度低。那么,这里的时间复杂度如何去理解,又怎么计算呢?常见的O(n)的含义是什么?本文将简单的解释这个概念。本文参考了清华大学邓俊辉老师的数据结构课程,值得大家学习。
一、简介
在关于程序算法的介绍中,比较算法的效率是一个非常常见的行为。我们经常看到某些算法的介绍中,描述某个算法的时间复杂度是O(n)。这是大O符号表示的时间复杂度(Big O Notation)。它的含义就是说这个算法的最差情况下,其操作次数会随着数据数量级的增长会是线性增长的。这个说法看起来好像比较晦涩,我们来逐一解释一下这个问题。
二、关于算法的效率比较
在说明这个概念之前,我们先简单解释一下关于算法的比较问题。一般来说,算法的执行速度与软硬件都有很大的关系,不同的编程语言、不同的编程方式、不同的硬件平台会导致相同的方法在运行效率上出现很大的差异。显然,我们不能简单地用耗时多久来表示某个算法的运行速度。那么,为了屏蔽这些软硬件差异来对算法进行比较,一个可行的思路就是将算法的执行时间转成算法需要执行的步骤数量来比较。因为无论什么编程语言实现的什么算法,在当前的计算机系统中最后都会变成CPU执行某个指令。如果我们能把算法的运行过程用执行多少次指令来估算,那么这样的话不同算法之间的执行速度就有一个公平的比较了。 但是,仅仅做这样的转换显然还是不够的。因为,即便是同样的算法,同样的数据规模,针对不同数据分布,算法的运行时间也是不一样的。例如,以在列表中查找是否包含某个元素为例。假设我们有如下两个列表:
列表1:
[1,2,3,4,5]
列表2:
[5,4,3,2,1]
如果我们要查找列表是否包含元素1,然后从列表第一个元素开始比对。那么显然第一个列表比对一次就可以返回Yes,而第二个列表需要比对5次才能返回Yes。显然,不同的数据分布也会对算法的运行速度产生影响。那么,为了屏蔽这种差异,一般来说对于算法的运行效率我们有三种可以计算的指标:最好的情况,最差的情况和平均情况。
以下图为例,假设T(n)是某个方法关于输入规模的一个函数,纵轴表示当前输入规模下,算法的时间复杂度,可以看到,n一定情况下,不同输入的分布T(n)会有一个最优的情况,也就是时间复杂度最低,用$\Omega(n)$表示,也有一个最差的情况,用$O(n)$表示,意思是最坏的情况下,这个方法的效率。其它的情况都是介于二者之间。
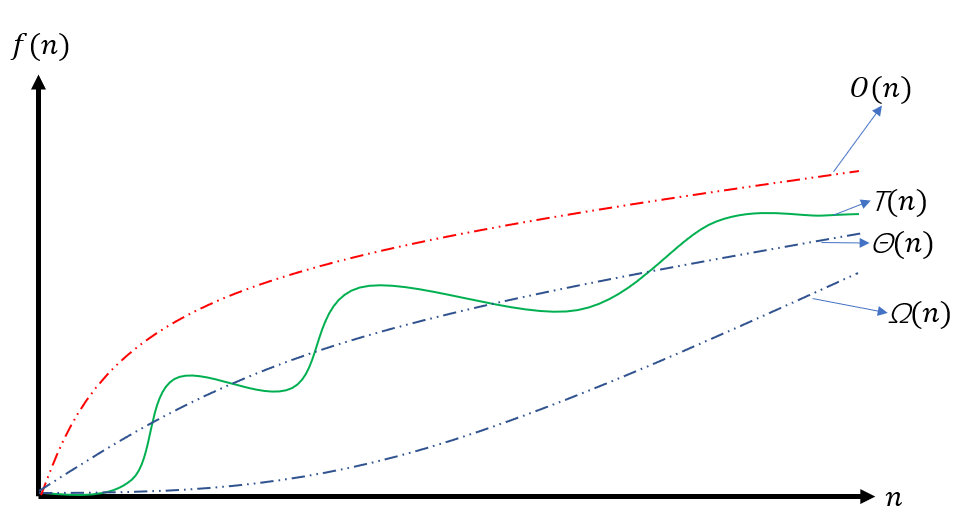
显然,大部分情况我们都关注算法在某个输入规模下最坏的时间效率问题。就像木桶效应,决定整个桶的装水多少取决于最短的那个木板。这里最坏的情况一般就是这个$O(n)$表示的时间复杂度曲线,也就是大O记号。
三、大O记号的时间复杂度
经过上面的介绍,我们明白了常见的大O记号主要是关注算法在悲观情况下的运行效率。这里还需要说明的是,我们关注的不仅是某种数据规模下,算法的时间复杂度。更重要的是当数据规模增长的时候,算法复杂度的增长情况。显然,即便在数据量一定的情况,如果某个算法耗时比较久,但是如果随着数据规模增长,其时间复杂度增长比较慢,那么其实也是可以很好的应用的。
因此,大O记号里面的参数就显得很重要了。但是我们可以看到,正常情况下,我们能见到的时间复杂度的大O记号都是如下几种:
O(1)
O(logn)
O(n)
O(n^2)
好像从来没有看到过n的系数或者多项式的情况。这是为什么呢?我们从简单的案例开始。
假设我们有如下的一个逻辑运算过程
int run(int[] inputList, int n){
int sum = 0;
for(int i=0; i<n; i++){
sum += inputList[i];
}
return sum;
}
这是一个Java方法示例,输入参数两个,一个是输入数组,另一个是n,表示计算列表种前n个数的和。我们看看这个方法的时间复杂度怎么计算。 首先,int sum=0是一个步骤,记作$O(1)$ for循环了n次,那么是$O(n)$次步骤,每次循环里面都只做了一次赋值操作,因此是$O(n*1)=O(n)$ 最后,返回一个结果,记$O(1)$。 那么这个方法的总的时间复杂度就是
T(n) = 1 + n*1 + 1 = n + 2 = O(n)
我们看到,虽然计算的是n+2次,但是最后的时间复杂度却是$O(n)$。原因是,当我们在估算算法的时间复杂度的时候,我们最关心的是算法随着数据规模增长之后,时间复杂度的增长趋势。可以看到,尽管这个方法的步骤是n+2,但是当n规模增长的时候,2是不会继续增长的。也就是说n规模较大的时候主要的时间复杂度的增长来源于前面的n,因此,使用大O计数法之后,这里可以看到的我们认为它的时间复杂度是n。
举另一个例子,假设我们某个算法的关于输入规模n的复杂度计算如下:
\sqrt{5n\cdot[3n\cdot(n+2)+4]+6}
化简之后我们得到的结果是:
(15n^3+30n^2+20n+6)^{1/2}
可以看到,虽然这个式子很复杂,但是最终我们发现当输入数据规模增长之后,这个时间复杂度增长最主要的来源其实是因为最高次项$15n^3$,剩下的虽然也会增长,但是最主要的还是最高次。同时,我们可以看到当n远大于2的时候,15那个系数也不重要了。因此,最后我们可以把这个复杂度记作是$O(n^{1.5})$,因为所有的低次项和系数都可以被省略。
当然,上述理解是从数据规模增长的角度来看的。正式的大O记号是由Paul Bachmann在1894年提出的。其定义如下:
T(n) = O(f(n))
当且仅当存在常数c,使得当$n>>2$后,有 $T(n) < c\cdot f(n)$ 。也就是说,当我们计算复杂度的时候,实际上是为上述复杂度函数$T(n)$找一个上界$O(f(n))$。这个上界就可以当作是我们复杂度的结果了。我们依然以上述函数为例,找它的上界:
\sqrt{5n\cdot[3n\cdot(n+2)+4]+6}
从最里面的$n+2$开始,我们可以把2扩大变成n,来合并,2变成了n,上述的函数肯定是要小于如下公式(n>>2):
\sqrt{5n\cdot[3n\cdot(n+n)+4]+6}=
\sqrt{5n\cdot(6n^2+4)+6}
显然,继续将4变成$n^2$,那么上述公式依然小于如下结果:
\sqrt{35n^3+6}<\sqrt{36n^3}=6n^{1.5}
由于这里的常数永远不会变化,在比较算法的时候,与输入规模没有关系,因此我们就不再关注这个常数(同时,如果c也考虑的话,那么两个算法也很难比较。由于大O记号主要目的是为了估算性能,不是精确计算,所以这里不会考虑与规模无关的系数了。)。最终,我们可以得到这个结果是$O(n^{1.5})$。和上面的估算是一致的。
那么,到了这里也就顺便说一下估算复杂度的时候,大O记号的2个重要忽略方法: 1、任何常系数都可以忽略 2、所有的低次项都可以忽略
四、大O记号的总结
常见的大O记号的复杂度包括如下几种: 常数复杂度$O(1)$:任何常数的操作,包括确定赋值、数值运算,只要算法中不包含任何显性、隐性的循环、判断等都算常数复杂度,也就是算法的运行效率与输入规模没有关系。 对数复杂度$O(logn)$:一般不写任何底数,因为底数都可以转换成系数,所以就忽略底数了。这种算法的时间复杂度虽然会随着规模增长而增加,但是增长很慢,是非常有效的方法,它比任何多项式复杂度都低。 线性复杂度$O(n)$:对于规模为n的问题,时间复杂度正好是n,也能接受的算法。 多项式复杂度$O(n^c)$:这里的c一般是大于1的。这种算法的时间复杂度也算是可以了。尽管c可能很大,但是相比较实际问题来说,还是可以接受的。 指数复杂度$O(a^n)$:多项式复杂度就算是次数很高,其实相比较指数复杂度来说都是可以接受的。看如下的结果:
n^{1000} = O(1.0000001^n)=O(2^n)
1.0000001^n=\Omega(n^{1000})
它的含义是,任何多项式复杂度,即便那个次数很高,都可以被$2^n$的指数复杂度覆盖。但是反过来,指数复杂度,就算底数很小,但是只要是严格大于1,那么也比多项式复杂度高。这里的意思就是多项式复杂度可以被认为是指数复杂度的下界。因此,指数复杂度的计算成本增长极快,正常情况是不能被我们接受。
大O记号是我们估算算法时间复杂度目前最为广发和通用的方法。希望在笔试的时候遇到会比较多。一般把常见的算法记一下也就OK了。主要还是能理解这个原理。
