大规模中文开源数据集发布!2TB、几十亿条可商用的中文数据集书生·万卷 1.0开源~中文大模型能力可能要更上一层楼了!
随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个书生·万卷 1.0数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。

书生·万卷 1.0数据集概览
书生·万卷 1.0数据集整合了中文和英文数据,内容涵盖文本、图像文本和视频三种模态,数据总量超过2TB。文本数据中包含不同领域的6亿份文档;图像文本数据经处理后形成了超过2200万个文档;视频数据有1000多个文件。
在数据集的构建中,研究团队通过算法处理和人工审核相结合的方式,确保了数据的安全性、高质量以及价值取向。所有数据均采用统一的JSON格式组织,并提供了数据集下载工具及相关文档。
这个开源的大规模多语言多模态数据集已被用于InternLM模型的训练,相比同规模模型,InternLM在多维度评测中展现出明显优势。WanJuan的发布填补了公开源数据的空白,有助于自然语言处理、计算机视觉等领域的技术进步,特别是需要多模态理解生成的任务。
InternLM模型在各项评测中也十分优秀,看样子这份数据集功不可没!
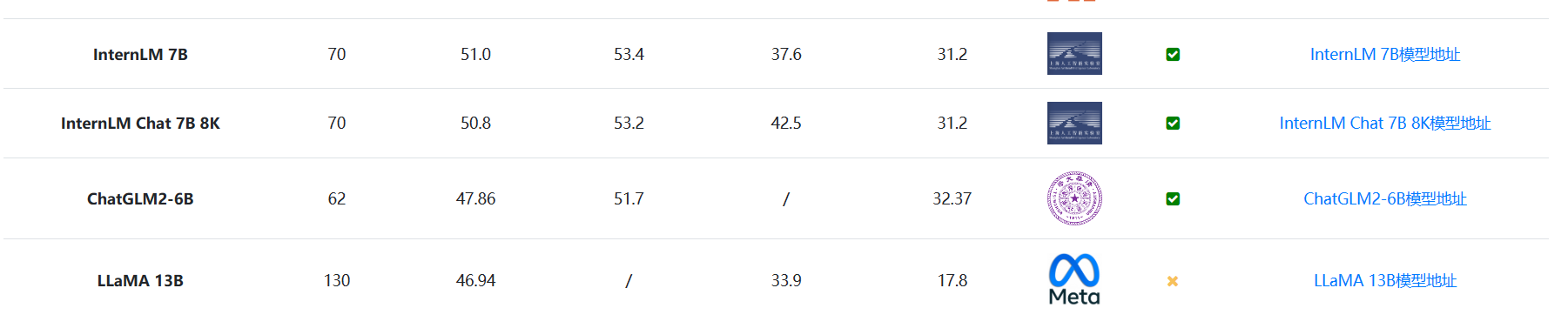
上图是InternLM在MMLU、C Eval和GSM8K等评测的得分,来源参考DataLearner大模型排行榜:https://www.datalearner.com/ai-models/llm-evaluation
书生·万卷 1.0文本数据集介绍
书生·万卷 1.0文本数据集包含6亿份文档,来源于网络和书籍等。具体来说,所包含的数据集领域如下:
可以看到,数据集十分丰富。根据介绍,书生·万卷 1.0文本数据集中中文数据占比35.1%,约2.2亿个文件,466.54GB。英文数据集占比61.4%,共3.83亿个文件,542.51GB。可以说应该是目前开源领域包含最多的中文数据集了!
书生·万卷 1.0文本-图像对数据集介绍
书生·万卷 1.0文本-图像对数据集包含2200多万个文本-图像对数据,数据量超过200GB(不含图像文件)。其中主要来源如下:
可以看到,这里的中文数据占比达到了62.3%!十分丰富!
书生·万卷 1.0视频数据集介绍
书生·万卷 1.0视频数据集式包含1000多个视频文件,来源中国媒体集团(CMG)和上海媒体集团(SMG)的节目。
书生·万卷 1.0数据集总结
文本数据包括超过6亿个文档,数据量超过1TB。图像文本数据经处理形成超过2200万个文档,数据量超过200GB。视频数据包含超过1000个视频,数据量超过900GB。它的一些其它信息补充如下:
- 数据收集和处理过程中,采用了算法和人工验证相结合的方式,确保数据安全、高质量以及价值取向。
- 提供了统一的JSON格式处理,数据集下载工具及支持文档,方便用户快速应用大模型训练。
- 该数据集中的预训练数据显著提升了训练模型的知识内涵、逻辑推理和泛化能力。
- 数据集的开放发布有助于自然语言处理和计算机视觉等领域的模型训练和算法研究,尤其是需要多模态理解和生成的任务。
- 本数据集填补了公开源大规模多模态预训练数据集的空白,有助于推动相关领域技术的进一步发展。
书生·万卷 1.0数据集的下载地址和其它资源
最后,书生·万卷 1.0数据集的开源协议是 CC BY 4.0,是知识共享组织制定的一个开源协议,它允许用户可以自由地共享、修改和商业使用受该协议保护的内容,只要遵守署名要求即可。
书生·万卷 1.0数据集的下载地址和其它资源请参考DataLearner数据集卡片末尾地址:https://www.datalearner.com/ai-dataset/wanjuan-1
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
