FrontierMath:AI大模型高级数学推理评测的新基准
FrontierMath是一个由Epoch AI开发的基准测试套件,包含数百个原创的数学问题。这些问题由专家数学家设计和审核,覆盖现代数学的主要分支,如数论、实分析、代数几何和范畴论。每个问题通常需要相关领域研究人员投入数小时至数天的努力来解决。基准采用未发表的问题和自动化验证机制,以减少数据污染风险并确保评估可靠性。当前最先进的AI模型在该基准上的解决率低于2%,这反映出AI在处理专家级数学推理时的局限性。该基准旨在为AI系统向研究级数学能力进步提供量化指标。
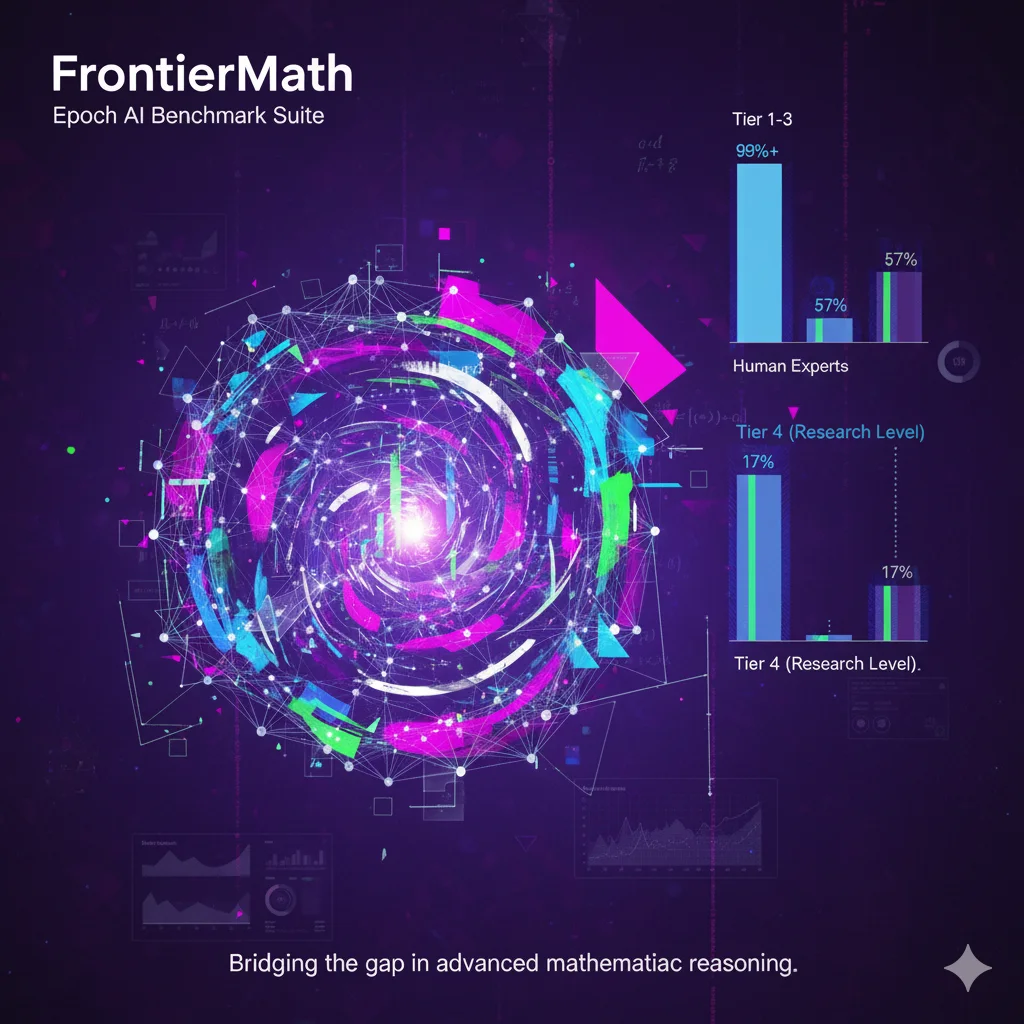
目前,FrontierMath分为2个不同版本的评测,Tier1-3是属于本科阶段的数学水平,具体排行数据参考DataLearnerAI的FrontierMath排行榜:https://www.datalearner.com/benchmarks/frontier-math FrontierMath Tier 4是研究生级别的数学问题,具体数据参考DataLearnerAI的FrontierMath - Tier4的排行榜:https://www.datalearner.com/benchmarks/frontier-math-tier-4
[toc]
当前数学AI评测的局限性
现有数学基准如GSM-8K和MATH已接近饱和状态,领先AI模型在这些测试上的准确率超过90%。这导致评估结果难以区分模型间的细微差异。同时,数据污染成为常见问题,许多模型通过训练数据间接接触到基准内容,从而夸大性能。此外,这些基准多聚焦于本科水平任务,缺少要求多步精确推理和领域专长的挑战性问题。数学作为严谨且可自动验证的领域,本应成为测试复杂科学推理的理想选择,但当前缺乏能反映专家级努力的测试套件。
FrontierMath基准概述
FrontierMath由Epoch AI于2024年11月7日首次发布于arXiv(论文ID: 2411.04872),最新版本更新至2025年8月28日。该基准得到OpenAI的支持,后者委托创建了300个问题(其中50个随机保留用于评估)。开发过程涉及超过60位数学家,包括教授、国际数学奥林匹克问题编写者和菲尔兹奖得主,如Terence Tao和Timothy Gowers。
基准的目标是评估AI在高级数学推理方面的能力,特别是那些需要扩展精确推理链的任务。它解决现有评测的饱和和污染问题,通过使用全新未发表问题和自动化验证,建立一个可靠的测试框架。该框架可跟踪AI从当前低性能向专家级能力的演进,同时最小化主观判断的影响。
基准设计与评估流程
FrontierMath包含数百个问题,按难度分为四个层级:Tier 1-3覆盖本科至早期研究生水平,Tier 4为研究级数学。问题设计注重“防猜测”特性,例如通过大型数值答案或复杂数学对象,确保随机猜测成功率低于1%。每个问题经历同行审核,以验证正确性、消除歧义并评估难度。审核显示,每20个问题中约有1个存在错误,与ImageNet等基准相当。
$s$
评估流程如下:
- 问题生成:专家数学家根据数学分类系统(MSC)创建问题,覆盖计算密集型(如数论)和抽象型(如范畴论)任务。
- 验证机制:采用自动化脚本,如SymPy确认解决方案或精确匹配答案。
- 模型测试:模型获得充足思考时间、迭代机会和Python环境支持,用于代码执行、假设测试和结果验证。评估包括单次运行准确率和pass@N(N次运行中至少解决一次的比例)。
- 问题数量:总计约300个,其中Tier 1-3有290个私有问题,Tier 4有48个非公开问题。
- 扩展计划:持续添加问题,同时保持领域和难度分布均衡,并通过错误赏金程序提升质量。
以下是基准中三个代表性问题的示例:
- 问题1(数论):
测试Artin的原根猜想。涉及定义如$v_p(n)$和$\text{ord}_p(a)$,计算$\lfloor 10^6 d_{\infty}\rfloor$,其中$d_{\infty}$为质数密度极限。答案:367707。
- 问题2(代数几何与群论)
构造单项式、奇次19次多项式$p(x) \in \mathbb{C}[x]$,实系数,线性系数-19,使得$X:= {{p(x) = p(y)}}$在$\mathbb{P}^1 \times \mathbb{P}^1$上有至少3个不可约分量(非全线性)。计算$p(19)$。答案:1876572071974094803391179。
- 问题3(数论)
给定递推序列$ a_n = (1.981 \times 10^{11})a_{n-1} + (3.549 \times 10^{11})a_{n-2} + (4.277 \times 10^{11})a_{n-3} + (3.706 \times 10^8)a_{n-4} $,初始$a_i = i ( 0 \leq i \leq 3 )$。找出最小质数$ p \equiv 4 \pmod{7} $,使$ n \mapsto a_n $在$ \mathbb{Z}_p $上连续扩展。答案:9811。
可以看到,这些问题都非常困难。
主流模型在FrontierMath上的表现
早期评估(2024年11月)显示,Claude 3.5 Sonnet、o1-preview、GPT-4o和Gemini 1.5 Pro等模型解决率均低于2%,远低于在GSM-8K和MATH上的90%以上准确率。到2025年,性能有所提升,但仍存在显著差距。Tier 1-3的聚合pass@the-kitchen-sink(跨模型所有运行)达到57%,表明约70%问题对当前模型不可及。Tier 4的解决率更低,最高为17%(pass@2)。
以下表格总结部分主流模型在Tier 1-3上的单次运行准确率和pass@N(基于2025年数据):
在Tier 4上,2025年评估显示:
分析表明,pass@N增长呈子对数形式,随运行次数加倍的增益递减(约1%)。这暗示当前模型在已解决问题的可靠性上仍有空间,但新问题解决依赖能力提升而非重复尝试。OpenAI o3模型在2024年底达到25.2%,为当时最高,但整体性能仍反映AI缺乏真正理解,仅依赖模式匹配。
总结与展望
FrontierMath通过数百个专家级问题和自动化验证,建立了一个标准化框架,用于监测AI数学推理的进步。它暴露了现有模型与人类专家间的差距,并为未来发展提供清晰指标。基准将持续扩展,包括定期模型评估和社区协作。预计到2026年上半年,性能可能接近70%,但达到85%以上需重大突破。该基准强调,AI向研究级能力的跃升要求在精确多步推理上的实质改进,而非简单规模扩张。
本科阶段的FrontierMath Tier1-3具体最新排行数据参考DataLearnerAI的FrontierMath排行榜:https://www.datalearner.com/benchmarks/frontier-math 研究生级别的FrontierMath Tier 4具体最新数据参考DataLearnerAI的FrontierMath - Tier4的排行榜:https://www.datalearner.com/benchmarks/frontier-math-tier-4
