大模型ARC-AGI-3评测基准:首个交互式推理基准
ARC-AIG-3最新完整的评测结果可以访问DataLearnerAI的ARC-AGI-3数据:https://www.datalearner.com/benchmarks/arc-agi-3
ARC-AGI 系列基准由 ARC Prize Foundation 维护,长期被主要 AI 实验室和学术研究者作为衡量 AI 推理能力的参照。
从形式上看,ARC-AGI 可以理解为一类“从示例中归纳规则”的任务集合。系统接收到若干组输入/输出示例,每个示例由小尺寸二维网格构成,网格中的每个单元为离散取值(通常表示颜色编号)。模型需要从这些示例中推断潜在的变换规则,并将该规则应用到新的输入上生成正确输出。
需要强调的是,这里的“图像”并非自然图片,而是抽象网格结构(可视为二维数组),任务不涉及现实语义理解,而是聚焦于结构归纳、模式组合与规则外推能力。
例如,一个典型任务可能如下:
输入:
0 0 0
0 2 0
0 0 0
输出:
0 0 0
0 3 0
0 0 0
在多个类似示例中,模型需要归纳出规则(如“将颜色 2 替换为颜色 3”),并将该规则应用到新的输入上。这类任务本质上属于从有限样本中进行程序归纳(program induction)。
2026年3月25日,该系列第三代版本 ARC-AGI-3 在旧金山 Y Combinator 正式发布,这是自2019年该系列初次推出以来,格式层面改动最大的一次迭代。
一、前两代基准的进展与饱和
要理解 ARC-AGI-3 为何出现,需要先了解前两代基准的走向。
ARC-AGI-1 和 ARC-AGI-2 都是图像输入、图像输出的评测——但这里的“图像”指的是离散网格表示的抽象图形,而非自然图像。给出一组输入/输出网格对,系统需推断变换规则并对新实例生成正确输出。
这些规则可能涉及颜色替换、几何变换、对象计数或结构重组,本质上属于从有限样本中进行程序归纳的问题。
到2025年,前沿模型在第一版上的得分已突破90%,这促使团队构建了第二版,引入更复杂的组合谜题。
到2026年2月,Gemini 3.1 Pro 在 ARC-AGI-2 上得分达到77.1%,Gemini 3 Deep Think 达到84.6%,接近该基准的实际上限。ARC-AGI-1 则基本宣告解决,Gemini 3.1 Pro 已达到98%。
两代基准快速饱和的背后,除模型能力提升外,还存在一个结构性问题:Gemini 3 的推理过程中曾正确引用 ARC-AGI 任务使用的整数-颜色映射,而这一信息从未明确告知模型——有力地表明该基准数据已被充分纳入训练。当前前沿 AI 推理能力从根本上受限于知识覆盖范围,由此产生了新形式的基准污染。
这些问题推动了第三代版本的诞生。
二、ARC-AGI-3 基本信息
奖金结构上,ARC-AGI-3 赛道总奖金85万美元,其中大奖70万美元授予首个在评测集上达到100%的团队;另有保底奖金奖励排名前五;两个里程碑奖在6月30日与9月30日设置阶段奖励。ARC-AGI-2 赛道则延续约100万美元的大奖,面向达到85%的开源方案,该奖项在2024年和2025年均未被认领。
三、评测设计与评分机制
从静态谜题到交互环境
ARC-AGI-3 彻底改变了评测格式。
与前两代一次性给定输入并要求直接输出结果不同,ARC-AGI-3 采用交互式评测流程。对于每一个任务环境,模型并非一次性生成答案,而是以 agent 的形式循环执行以下过程:
- 观察当前环境状态(以网格或视觉形式呈现)
- 输出一个离散动作(如移动、选择或操作对象)
- 接收环境反馈(状态更新或终止信号)
- 基于历史轨迹更新内部推断并继续行动
这一过程持续进行,直到任务完成或达到步数上限。
每个环境是一个具有独立内在逻辑的回合制系统,没有任何指令、描述,也没有明确的胜利条件。这意味着模型需要在交互过程中同时推断“环境规则”和“任务目标”,而非仅在已知目标下执行规划。
共135个环境经过测试,所有环境均被无先验知识、无任何指令的人类参与者顺利通过。每个环境包含8至10个关卡,关卡难度递增,逐步引入新机制。
人类基线数据来自预览阶段的大规模测试:研究团队从1200多名人类玩家在3900多场游戏中收集了数据。每个环境至少经过10名参与者的受控测试,以第二好的人类玩家行动数作为正式基线——去掉最优者以避免异常值影响。
评分指标:RHAE
核心评分指标名为 RHAE(Relative Human Action Efficiency,相对人类行动效率)。它衡量 AI 完成每个关卡所用行动数与人类基线的比率,在每个环境内归一化后跨所有环境取平均。
该指标惩罚蛮力搜索——仅依赖大规模试错(brute-force exploration)而未形成有效环境模型的策略,会在该指标下显著受罚;同时兼顾数据效率与风险效率,并允许直接进行人机比较。
具体的惩罚机制采用平方计算:若人类需10步完成,AI需100步,则该关卡得分为1%。单关卡得分上限为人类基线的1.0倍,AI 每关行动数上限设为人类平均的5倍,超出则视为未完成。
官方排行榜仅接受通过 API 调用、使用统一系统提示的模型结果,不接受针对特定任务定制的 harness 方案——原因是评测目标是衡量模型自身的通用智能,而非人类工程师在特定任务系统搭建上投入的智能。
四、主流模型当前表现
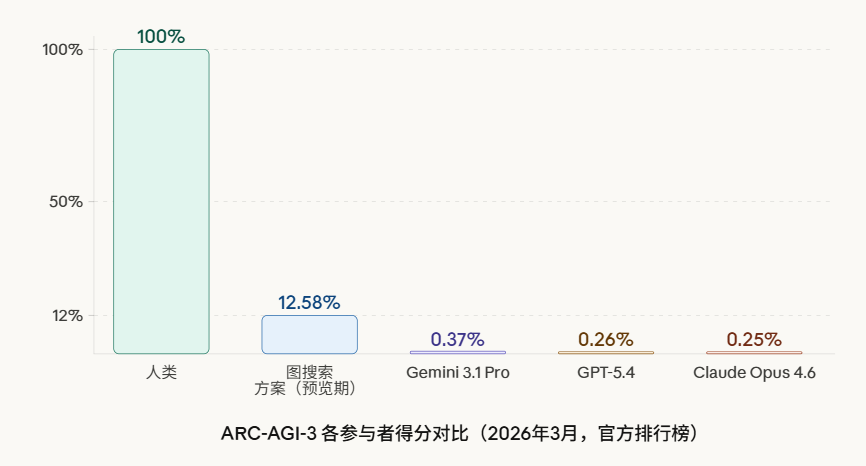
Gemini 3.1 Pro Preview 得分0.37%,GPT-5.4得分0.26%,Claude Opus 4.6得分0.25%,Grok-4.20得分0.00%。
与此同时,所有人类测试者100%通过了全部环境,且未接受任何训练或指令。预览阶段(2025年7月至8月)得分最高的方案值得单独说明:12.58%来自非 LLM 的图搜索方案(CNN + 图结构状态探索),而非任何大型语言模型。
另一个说明问题的实验来自与杜克大学的合作测试:Claude Opus 4.6 在已知环境中使用定制 harness 得分97.1%,但在从未见过的环境中得分归零。这表明,感知游戏环境和 API 格式本身并不是瓶颈——定制策略根本无法迁移到未见过的环境。
五、关于评测设计的讨论
ARC-AGI 系列在历史上对 AI 能力拐点的指示相对准确:ARC-AGI-1 大概率是第一个精确识别出 o3 等前沿推理系统突破的基准;ARC-AGI-2 随后捕捉到了现代推理模型的快速进步和 scaffolding 技术的兴起,这些技术如今已被部署在 Claude Code 和 Codex 等生产工具中。
不过,ARC-AGI-3 的评测设计本身也引发了一些讨论。批评者指出,平方效率惩罚机制本身就倾向于产生低分结果;此外,官方评测排除了扩展思考模式的模型。
对此,Foundation 的回应是:官方榜之外单设社区排行榜接受 harness 驱动的结果,但采用自报告机制,并明确警告不应将社区榜上的任何得分视为 AGI 进展的证据。Foundation 的判断是,足够通用的 harness 技术最终会被模型本身吸纳——正如 chain-of-thought 从外部技术变成 o1 内置特性的过程。
竞赛层面也有一个值得注意的约束:Kaggle 评测过程中不允许访问互联网,这意味着评测阶段不能调用任何外部推理 API。希望认真参赛的团队,要么在本地运行开放权重模型,要么构建类似预览期获胜者那样的非 LLM 系统。
六、小结
从评测形式上看,ARC-AGI 系列经历了从“静态规则归纳任务”到“动态环境中的在线学习与决策问题”的转变。
ARC-AGI-3 与前两代基准在形式上存在根本差异:从一次性基于示例推断规则并输出结果,转向在无指令环境中通过交互逐步建立模型并完成任务;评分标准也从正确率转向与人类基线对齐的行动效率。
该基准的核心主张是:只要 AI 与人类之间存在学习效率的差距,AGI 就尚未达成。ARC-AGI-3 通过跨时间测试智能来使这一差距可量化,捕捉规划视野、记忆压缩以及随新证据更新信念的能力。
从目前数据来看,前沿大模型在这一维度的表现与人类之间存在量级上的差距,且这种差距不能简单归因于工程层面的优化缺失。ARC-AGI-3 将在2026年全年持续运行,可以将其作为观察 AI Agent 自主适应能力发展的参照之一。技术报告与工具包均已开源,ARC-AIG-3最新完整的评测结果可以访问DataLearnerAI的ARC-AGI-3数据:https://www.datalearner.com/benchmarks/arc-agi-3
