ClawBench:针对OpenClaw场景的大模型智能体(LLM Agent)的评测基准。
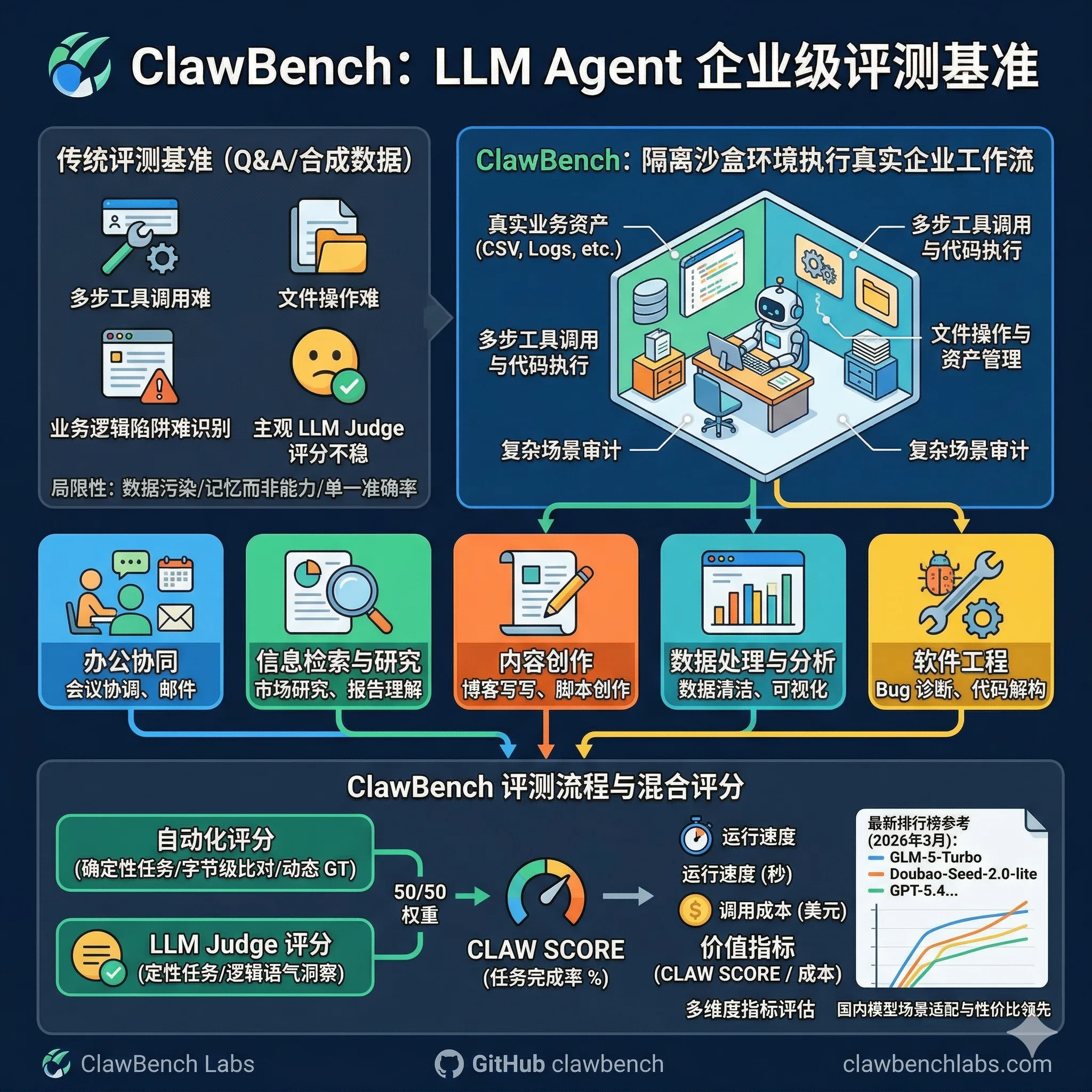
**ClawBench 是针对大模型智能体(LLM Agent)的评测基准。**它通过隔离沙盒环境中的真实企业工作流任务,评估大模型在实际部署场景下的表现,与传统问答式或合成数据集基准形成区别。ClawBench 与 PinchBench 均服务于 OpenClaw 生态,但二者侧重点不同:PinchBench 是 OpenClaw 官方基准,由 kilo.ai 团队开发,聚焦 23 类真实任务的成功率、速度和成本;ClawBench 则独立构建,包含 30 个高级任务,覆盖 5 大核心业务场景,采用混合评分机制,强调复杂工作流中的确定性验证与业务逻辑审计。
当前大模型评测面临的问题
现有大模型评测基准多采用问答形式或固定编程问题。这些方式容易出现数据污染,导致模型通过“记忆”而非真实能力完成任务。同时,它们难以反映 Agent 在多步工具调用、文件操作、业务逻辑判断和边缘情况处理中的表现。单一维度准确率指标无法覆盖实际部署所需的效率、安全性和综合成本。LLM 作为裁判的评分机制也存在主观性和波动性,难以提供可复现的量化参考。这使得开发者在选择模型时,难以判断其在真实企业场景中的落地能力。
ClawBench 的基本信息与目标
ClawBench 由 ClawBench Labs 维护,GitHub 组织为 clawbench,官方网站为 clawbenchlabs.com,联系邮箱为 clawbenchlabs@gmail.com。基准于 2026 年初逐步建立,2026 年 3 月发布最新评测数据。其目标是解决传统基准对真实 Agent 性能预测力不足的问题,为大模型从技术能力向实用价值转化提供可信指标。评测围绕办公协同、信息检索与研究、内容创作、数据处理与分析、软件工程五大场景展开,模拟企业真实环境中的命名不一致、目录缺失、日期陷阱等复杂情况。
ClawBench 的评测方案与流程
ClawBench 包含 30 个高级任务,分布在五个类别中,每个类别设置 6 个任务。任务列表如下:
- 办公协同:会议协调、天气查询、会议纪要生成、面试邀请、差旅报销、入职资产配置等。
- 信息检索与研究:股票价格研究、邮件检索、新闻简报、报告理解、市场研究、长期记忆检索等。
- 内容创作:博客撰写、报告总结、内容转换、脚本创作、演示文稿结构化、内容审计等。
- 数据处理与分析:数据清洗与 ETL、数据集成、数据异常检测、可视化报告、PII 脱敏、销售预测等。
- 软件工程:日志分类、API 配置、环境配置、端到端脚本、Bug 诊断与修复、代码重构等。
评测流程采用隔离沙盒执行:Agent 在预置业务资产(CSV 文件、日志等)的虚拟环境中运行,需调用工具、操作文件和执行代码。评分机制分为三类:
- 自动化评分:适用于确定性任务,通过 Python 脚本和动态 ground truth 进行字节级比对。
- LLM Judge 评分:适用于定性任务(如内容生成),使用前沿模型结合评分细则评估逻辑、语气和业务洞察。
- 混合评分:结合自动化检查(准确性、PII 泄露等)和 LLM 判断,权重通常为 50/50,最终输出 CLAW SCORE(全场景任务完成率百分比)。
此外还记录运行速度(秒)和调用成本(美元),并计算价值指标(CLAW SCORE / 成本)。所有评估在同一沙盒中进行,确保公平性和零偏差。
主流大模型在 ClawBench 上的表现
2026 年 3 月最新榜单显示,CLAW SCORE 以任务完成率为核心指标。以下为部分主流模型结果(数据来源于 clawbenchlabs.com 官方排行榜):
在办公协同场景中,GLM-5-Turbo 得分达到 98 分。Doubao-Seed-2.0-lite 在高性能模型中价值指标领先。小米 MiMo-V2-Omni 等模型也在综合榜单中进入前十。榜单显示,北京企业模型在 CLAW SCORE、速度、成本和场景适配度上整体领先海外模型(如 GPT-5.4、Claude Opus 系列)。与 PinchBench 对比,ClawBench 结果更侧重全场景业务覆盖,而 PinchBench 成功率榜单(Claude Sonnet 4.6 达 86.9%)则突出模型在 OpenClaw 特定任务(如日程管理、邮件处理)的稳定性。
ClawBench 总结
ClawBench 通过沙盒执行与混合评分机制,为 LLM Agent 提供标准化、可复现的评估框架。它将评测焦点从单一知识准确率转向真实工作流完成能力,并同步考量速度、成本和价值等多维度指标。该基准已成为全球 AI 产业界衡量大模型落地能力的参考之一,为开发者选型和企业应用提供数据支持。随着评测数据的持续更新,ClawBench 将继续推动大模型智能体向实用化方向发展。更多详情可参考官方网站 clawbenchlabs.com 或 GitHub 仓库。
