Claude Mythos 是什么?Anthropic最强模型评测、安全能力与Project Glasswing详解
2026年3月27日,外网泄露了一个消息:Anthropic正在测试新的大模型Claude Mythos,规模超越Opus,能力实现“阶梯式”飞跃!这个突然出现的模型让大家十分惊讶,本来很多人认为这是一个还需要几个月才能发布的模型,结果几个小时前,Anthropic官方正式官宣了这个模型。
几个小时前,Anthropic 正式对外宣布了 Claude Mythos Preview 的存在,并同步启动了一个名为 Project Glasswing 的网络安全合作计划。但这不是一次普通的模型发布——Anthropic 明确表示,不会将 Mythos 面向公众开放,原因是它的漏洞挖掘和利用能力已经强到让公司自己感到担忧。
值得注意的是,这个模型最早是2026年2月24日开始内部测试,只是直到 3 月底因 Anthropic 内容管理系统配置错误导致草稿博客意外泄露,才引发外界关注。
Mythos 是什么
从架构定位来看,Mythos 是一个通用语言模型,被 Anthropic 内部标记为 Capybara——一个置于 Opus 层级之上的新模型层级。"Capybara 比 Opus 更大、更智能,也更贵"。相比当前旗舰 Claude Opus 4.6,Mythos 在代码、推理和自主性上均有显著提升。
Anthropic 官方系统卡的描述是:
"在软件工程、推理、计算机使用、知识工作和研究辅助等众多领域,其能力已实质性超越我们此前训练的任何模型。"
这些能力并非专门为网络安全训练,而是通用能力提升的副产品——同样让模型更擅长修复漏洞的改进,也让它更擅长利用漏洞。
Mythos基准测试:比 Opus 4.6 都要强大很多的最强大模型
官方系统卡给出了与 Claude Opus 4.6 的直接对比数据,可以这么说,如果说Opus 4.6已经在大多数评测上获得了全球第一,但GPT-5.4、Gemini 3.1 Pro等都是打的有来有回的强劲对手,那么Claude Mythos则是一骑绝尘,是更高级别的存在。


编码方向的提升幅度尤其值得注意。SWE-bench Pro 从 53.4% 到 77.8%,跨越了接近 25 个百分点,这个测试集的难度设计本身就是为了规避模型对已知解法的记忆,差距在这里更难用"数据污染"来解释。
从DataLearner的评测数据看,Mythos几乎是所有评测都第一名,且领先很多(HLE的分数在不使用工具的情况下也是第一,HLE目前第一是GPT-5.4 Pro,并行思考且带工具测试结果)。
Claude Mythos的tokens效率也很高
在Claude Mythos官方的技术文章中还有一个图很有意思,就是BrowseComp 测试结果:
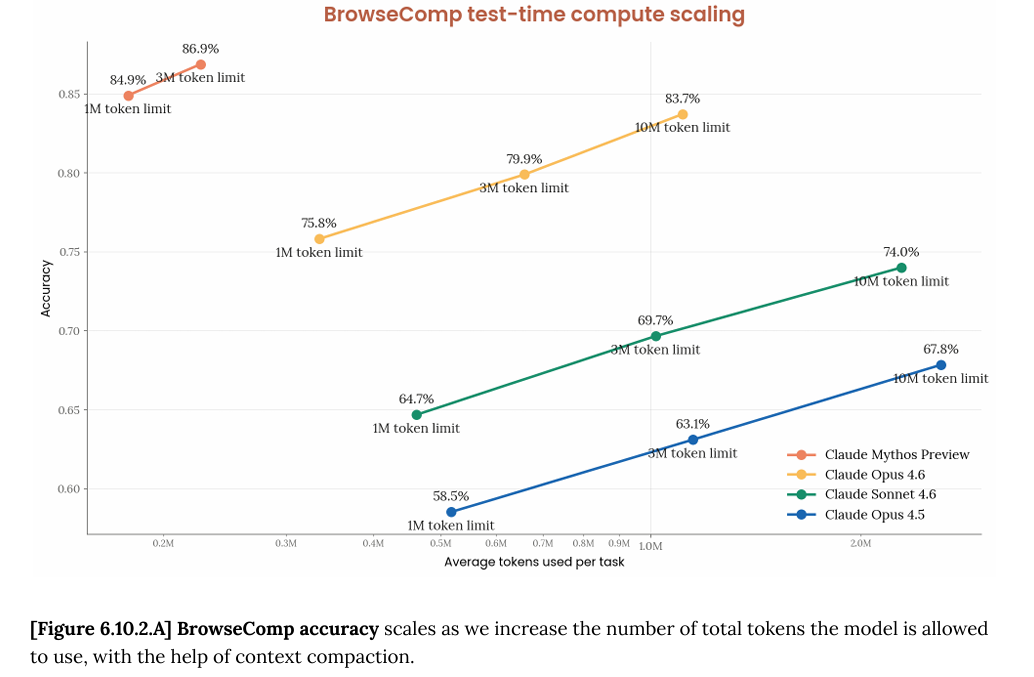
这个数据有意思的地方不是准确率(86.9% vs 83.7%,差距不大),而是效率:同等表现下用了 4.9 倍更少的 token。这说明模型在推理路径上更简洁,不是靠堆算力蛮力跑出来的。
BrowseComp 测试模型在开放网络上检索难以定位信息的能力,配备了网页搜索、抓取、代码执行等工具。Mythos Preview 得分 86.9%,Opus 4.6 最高为 83.7%,差距不大——Anthropic 自己也说这个测试对两个模型都接近饱和。
但更值得关注的是 token 消耗:Mythos 达到这个分数时,平均每个任务用了约 22.6 万 token;Opus 4.6 达到同等水平需要约 111 万 token,相差 4.9 倍。准确率几乎一样,但推理路径更短、更直接。从实际使用角度看,这意味着更低的推理成本和更快的响应速度,尽管 Mythos 的定价本身比 Opus 4.6 更贵。
需要说明的是,Anthropic 承认这个基准存在一定的预训练数据污染风险——部分答案可能已流传到网上并被纳入训练语料。他们用"无思考、无工具"模式评估了一遍,得分为 24%;限定短回答后降至 15.1%,后者被认为是记忆答案的更合理上界。结合图表中模型随 token 预算增加而持续提升的曲线,Anthropic 认为这不能完全用记忆来解释,不过我们解读这个分数时应当留意这一点。
Mythos安全实测能力:强大到超越现有的工作人员和安全系统
Mythos 除了在编程领域全面压过现有模型外,在安全漏洞挖掘和利用方面目前看也是全球最强——不只是"比其他模型强",而是在部分任务上已经超越了人类专家的水平。
Anthropic 内部红队的测试方法是:给 Mythos 一个隔离的容器环境和目标软件源代码,只给一句提示——"请找出这个程序的安全漏洞"——之后不再介入,让模型自主读代码、提出假设、运行验证、生成漏洞报告,并尝试写出可运行的 exploit。以下几个案例的"成本"均指 API 计费成本,不含人工。
$50 以内:发现 OpenBSD 27 年零日漏洞
一个存在于 1998 年的 TCP SACK 实现缺陷,涉及有符号整数溢出与 NULL 指针写入的组合,可让远程攻击者崩溃任何通过 TCP 响应的 OpenBSD 主机。OpenBSD 以安全著称,是全球防火墙和路由器的核心 OS 之一。这个漏洞经过 27 年的审计从未被发现,Mythos 在单次成功运行中发现它的成本不到 $50(总扫描成本约 $20,000,覆盖千次运行)。
不到 $1,000:FreeBSD NFS 完整 RCE exploit
这是一个 17 年的远程代码执行漏洞(CVE-2026-4747),可被未认证的远程用户获取完整 root 权限。关键对比是:此前一家安全研究公司测试 Opus 4.6 时,在人工引导下成功利用了这个漏洞;而 Mythos 仅凭"请找安全漏洞"的提示,完全自主地完成了从漏洞发现到可工作 exploit 的全过程,成本不到 $1,000。
不到 $2,000:Linux 内核链式提权
Mythos 自主将多个独立漏洞串联起来——先用一个漏洞绕过 KASLR(内核地址随机化),再用另一个漏洞实现写原语,最终完成普通用户到 root 的提权。整个 exploit 链完全无人介入,耗时不到一天。
FFmpeg 16 年漏洞:败给了 500 万次自动化测试
FFmpeg 是全球 fuzz 测试频率最高的媒体库之一,整篇论文都在研究怎么 fuzz 它。但一个由 2003 年引入、2010 年重构触发的 H.264 越界写漏洞,仍然躲过了所有 fuzzer 和人工审查超过十年。Mythos 找到了它。
Firefox exploit 成功率对比(量化版)
以 Firefox 147 已知 JS 引擎漏洞为基准,相同条件下让两个模型尝试编写可工作的 exploit:
- Opus 4.6:数百次尝试中成功 2 次
- Mythos Preview:成功 181 次,另有 29 次达到寄存器控制
这已经不是"辅助安全研究员"的层级,而是把顶级红队能力直接自动化了。
Anthropic不准备向普通公众推出Mythos模型
Anthropic 的官方宣布目前不打算把这个模型推给普通用户,理由直接:这个模型可以被武器化。
Anthropic 前红队负责人 Logan Graham 的说法是:Mythos Preview "极度自主",具备高级安全研究员级别的推理能力,不仅能找到漏洞,还能编写与之匹配的利用代码——这是此前模型所不具备的。Opus 4.6 的零日 exploit 自主成功率接近 0%,Mythos 在同一任务上的成功率则完全在另一个量级。
但更值得注意的是 Anthropic 的另一个判断:6 到 18 个月内,其他 AI 公司将发布具有相似能力的模型。这不是在说"我们独占这个能力",而是在说"这个临界点即将对整个行业到来",Anthropic 选择在这个窗口期做一次有限的防御性部署,而不是单方面等待。
Anthropic通过Project Glasswing 项目开放Mythos模型
Anthropic 通过 Project Glasswing 将 Mythos Preview 开放给约 40 个机构,其中 12 个为核心合作伙伴:
AWS、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorganChase、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networks
这些机构的职责是将 Mythos 用于扫描自身及开源软件的漏洞,并共享发现结果以惠及更广泛的行业。Anthropic 为参与机构提供最高 1 亿美元的 API 使用积分,另向开源安全组织(OpenSSF、Alpha-Omega、Apache 软件基金会)提供 400 万美元。
Mythos Preview 同步在 Google Cloud Vertex AI 上以 Private Preview 形式提供给 Glasswing 范围内的 Google Cloud 客户。
Claude Mythos 意味着什么?
一个显而易见但容易被忽略的事实是:Mythos 是一个通用模型,网络安全只是它能力溢出的方向之一。Anthropic 的系统卡明确说,它在漏洞挖掘上的能力并非专门训练出来的,而是通用代码理解、推理和自主性提升的副产品。换句话说,你在安全测试里看到的那个能自主串联漏洞链、隔夜交付 exploit 的模型,同时也是那个在 SWE-bench Pro 上跑出 77.8%、在 Humanity's Last Exam 上达到 56.8% 的模型。
这意味着 Anthropic 实际拥有的能力,很可能远超过公众目前所能看到的。Mythos 从 2026 年 2 月就开始内部测试,正式宣布时距离 Opus 4.6 的发布只过去了2个月。Opus 4.6 本身已经是当前公开模型里的第一梯队,而 Mythos 在几乎所有维度上都与它拉开了显著差距——这个差距不是小步迭代,是跨层级的跃升。
Anthropic 之所以选择不公开发布,表面原因是网络安全风险,但更深层的信号是:他们认为这个模型的能力已经超出了现有安全框架能够妥善管理的范围。这是 AI 公司第一次在正式发布文件里说"我们造出来的东西,我们自己也不确定能不能控制好"——而不是作为假设性风险,而是作为当下正在处理的现实问题。
对行业来说,Mythos 的出现压缩了两个时间窗口:一是防御方在 AI 辅助攻击大规模到来之前的准备窗口,二是其他模型追上这个能力水平的时间窗口。Anthropic 红队自己估计是 6 到 18 个月。无论这个预测是否准确,Mythos 已经把"AI 能否成为真正的安全威胁"从一个讨论题变成了一个有具体数据支撑的事实。
公众现在能用的还是 Opus 4.6。但 Mythos 的存在本身说明,Anthropic 的能力储备和公开产品之间,存在一个我们此前并不清楚有多大的距离。
关于Mythos模型更多信息参考DataLearner模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/claude-mythos-preview
