6张示意图解释6种语言模型(Language Transformer)使用方式
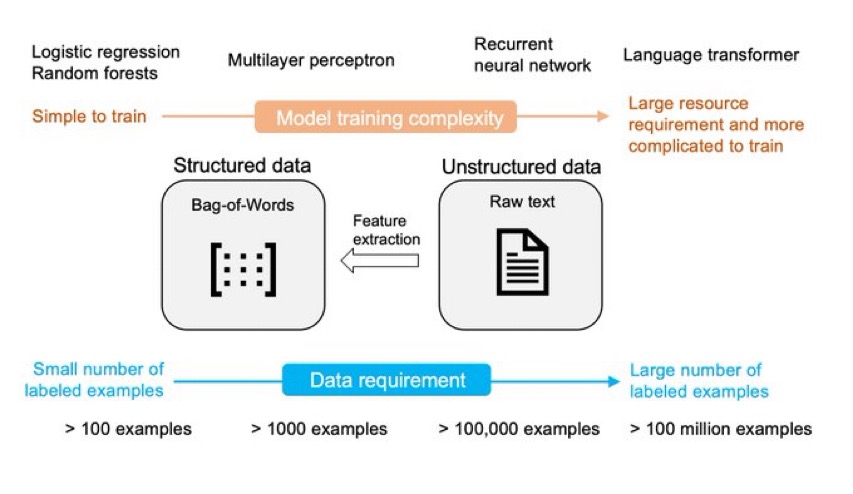
近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。
一、从头开始训练(Train from scratch)
从头训练一个transformer是最基本的使用方法,只是一般来说transformer模型需要大量的数据,实际场景很难获取这么多有标注的数据做训练。所以当前的transformer模型的训练都是使用unlabeleds数据做预训练,这与有监督学习的模型训练方式差别很大。
二、基于特征的方式:在embeddings的基础上训练新模型(Train new model on embeddings)
使用一个现成的transformer模型,将最后一层删除,然后使用推理的方式运行大语言模型,在embeddings上训练新的分类器。

三、微调Ⅰ(Finetuning Ⅰ)
这是近几年很流行的大模型使用方法。即将除了输出层以外的所有权重“冻结”(freeze)。然后随机初始化输出层参数,再以迁移学习的方式训练。仅仅更新全连接输出层,其它层的权重不变。

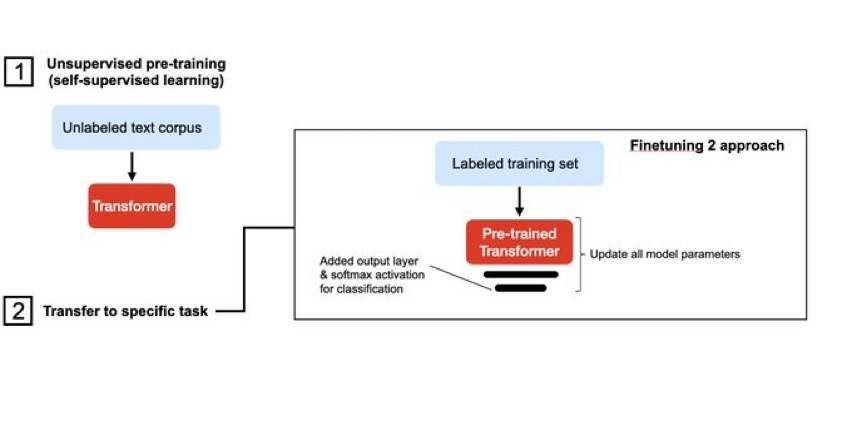
四、微调Ⅱ(Finetuning Ⅱ)
这种微调方式是更新所有的权重。随机初始化输出层的参数,然后用迁移学习的方式训练,但是与上一种训练方式不同的是这种微调会更新所有的参数。也就是说模型的结构不变,输出层重新随机初始化,其他层权重不变,训练的时候所有的权重都更新。
五、零样本学习(Zero-shot learning)
在没有训练数据的情况下进行预测。使用一个预训练的模型,然后通过model-prompt方式提供一种任务。这就是近几年的一种新的语言模型“训练”方法。微调依然需要我们构造标注数据,然后对模型进行重新训练,而这种方式则是采用构建一个模板+prompt方式,不训练模型,但是让模型知道我们要做什么。这意味着我们不需要训练模型,只需要想办法设计出模型要做的任务即可。现在的语言模型由于最开始就是从无标注数据中随机剔除某些单词训练,所以很擅长做完形填空类的任务。因此,我们只需要设计完形填空的任务,教模型认识这是做啥就可以了,相比较微调,它不需要关注标注数据,也不需要对模型的权重重新训练。

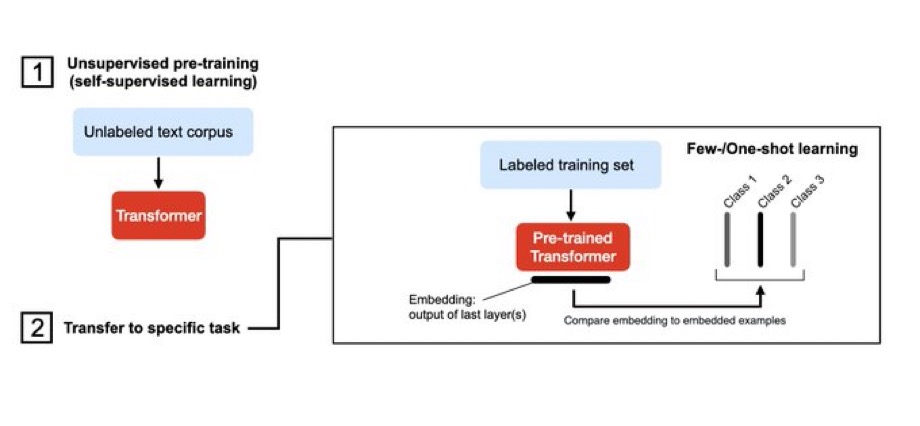
六、小样本学习(Few-shot learning)
从一小部分已标注的数据进行学习。可以作为零样本学习的扩展或者是embed一种。然后基于最近邻搜索选择最相似的例子。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
