Meta开源Llama3.3-70B-Instruct模型:大模型后训练的佳作,性能超越4050亿参数规模的Llama3.1-405B大模型!
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。

Llama3.3-70B-Instruct简介
Llama3.3-70B-Instruct是目前Llama3.3系列中唯一开源的模型,且没有基座大模型,仅开源了指令优化版本的模型。
根据官方的介绍,Llama3.3-70B-Instruct是经过预训练以及指令微调的模型,参数规模700亿,是一个纯文本的大语言模型,这意味着它不支持多模态的输入和输出,仅支持文本的输入和输出。不过Llama3.3-70B-Instruct是多语言大模型,支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语共8种语言,不支持中文(这里非常奇怪的是,汉语作为广泛使用的语言,一直不在Llama系列的支持范围,哪怕欧洲的Mistral都开始支持汉语了,这个模型也不支持,小扎这位同志觉悟有点问题啊~)。
Llama3.3-70B-Instruct在15万亿tokens上训练,支持128K上下文输入。知识日期是截止2023年12月份。
该模型效果的提升主要依赖于对齐训练技术和强化学习的进步。Meta官方简单提了是基于合成数据,做了在线偏好优化,可以在训练过程中,基于反馈结果实时优化模型。
此外,Llama3.3-70B-Instruct支持GQA,即Grouped-Query Attention,GQA 减少了注意力机制的计算复杂度,这对于像 Llama 3.3 这样的 700亿参数大模型尤为重要。在推理阶段,它使得模型能够以更高的速度生成文本。
Llama3.3-70B-Instruct的评测结果
Llama3.3-70B-Instruct在多项行业基准测试中超越了许多开源和闭源的聊天模型,展现了卓越的性能。
特别是Llama3.3-70B-Instruct的参数规模700亿左右,但是各项评测指标约等于4050亿参数规模的Llama3.1-405B模型!这意味着Llama3.3-70B-Instruct可以用更少的资源,更快地生成文本,但是性能与近6倍参数规模的大模型差不多!
下图展示了Llama3.3-70B-Instruct模型和业界其它模型的对比结果:
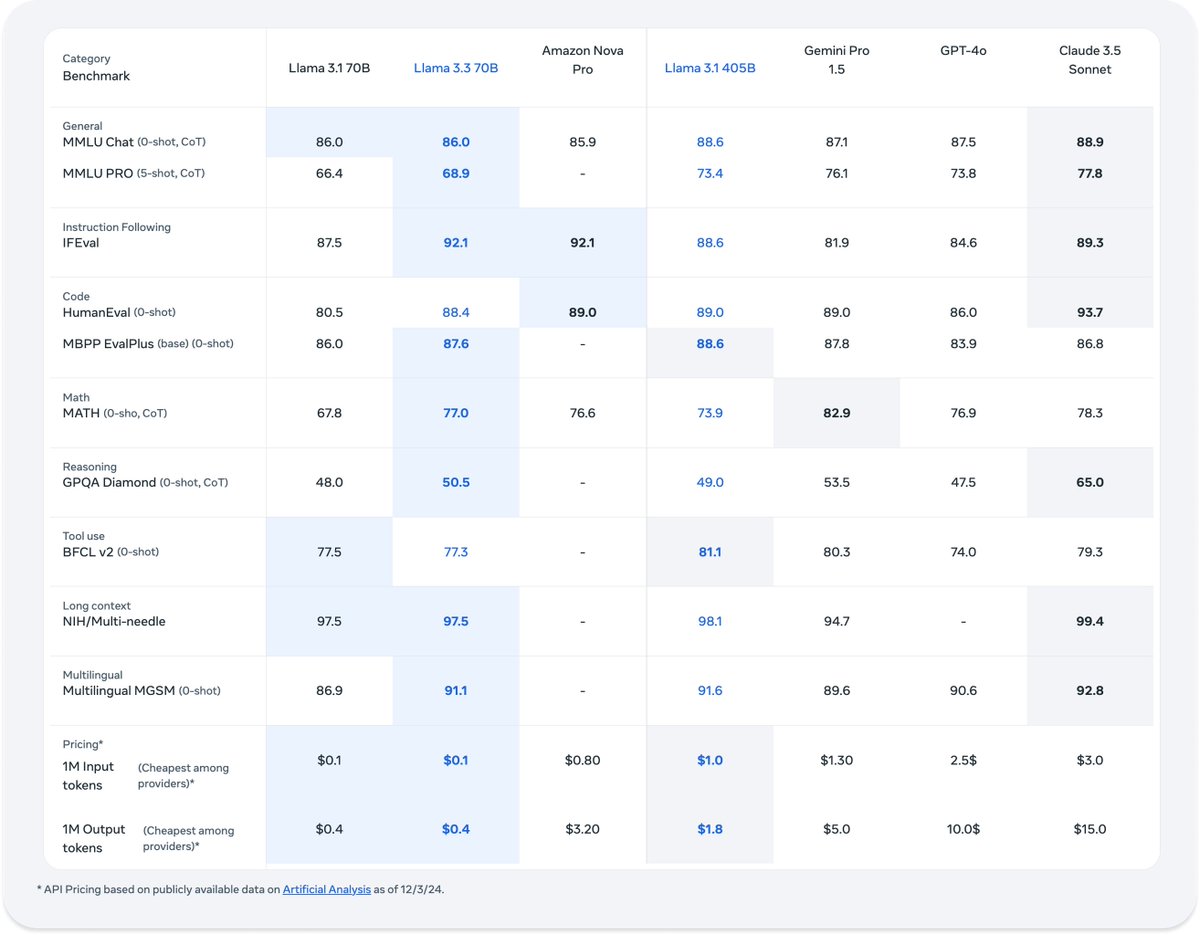
可以看到,该模型在多个测试中均取得了最优的结果,甚至不低于GPT-4o的水平。
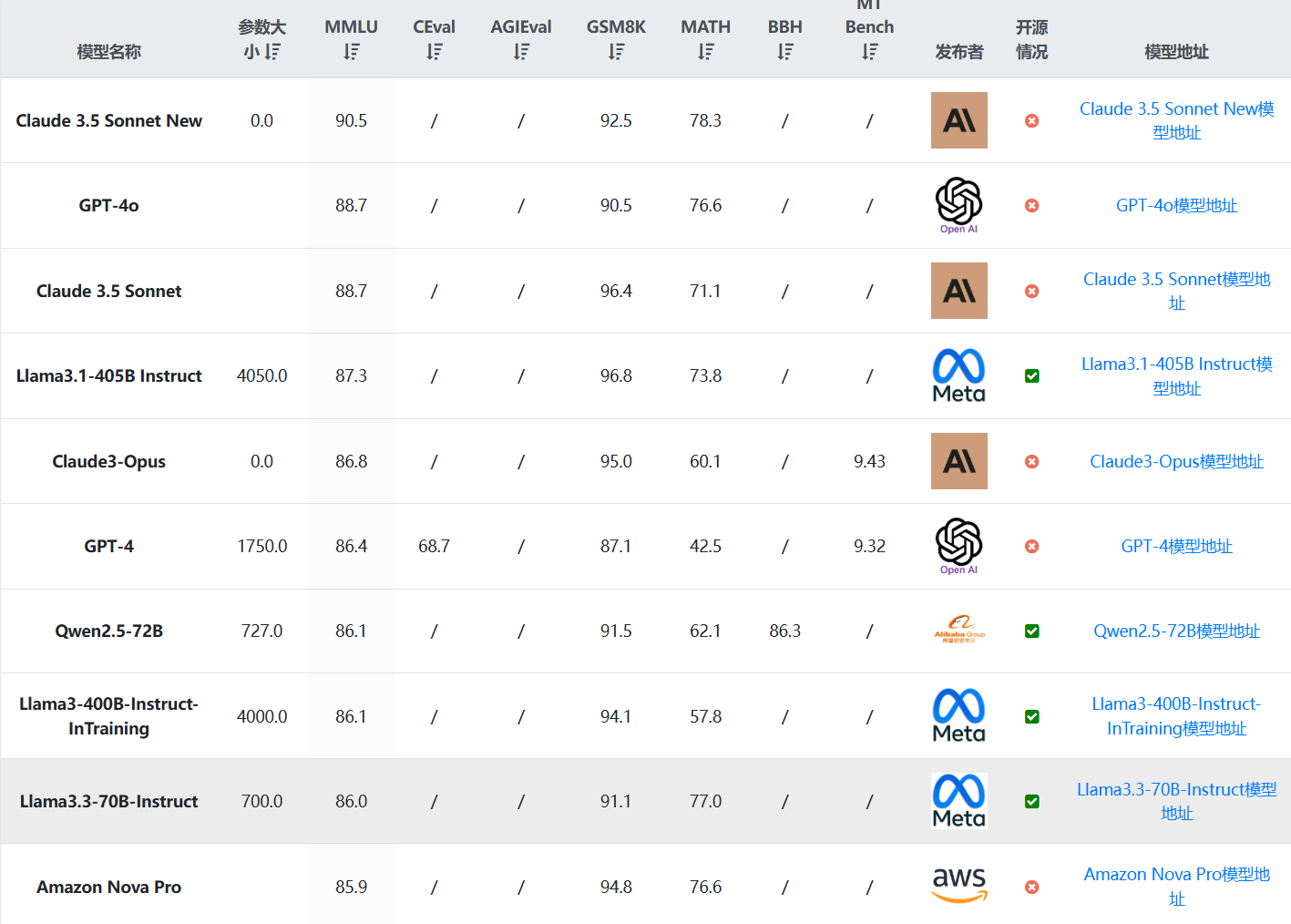
在DataLearnerAI收集的全球大模型排行榜中,按照MMLU排序,Llama3.3-70B-Instruct模型排名第九,超越了Amazon Nova Pro,略低于Qwen2.5-72B模型,但是在数学逻辑上它的得分77分,远超同类型模型,比Qwen2.5-72B模型也高很多。
Llama3.3和其它Llama3系列模型的关系
这里简单介绍一下Llama3系列的模型发布版本和节奏。大家就能理解Llama3.3-70B-Instruct在Llama系列的地位和目标。
目前,Llama3系列包含了4个不同的版本,分别是2024年4月份发布的Llama3系列、2024年7月份发布的Llama3.1系列、2024年9月份发布的Llama3.2系列以及2024年12月初发布的这个3.3系列。
但是,其实Llama3和Llama3.1算是比较正常的大版本节奏,因为这两个系列都包含了最小80亿参数,最大700亿以及4050亿参数规模的多个不同版本模型。
而Llama3.2系列其实只发布了1B和3B的小规模纯文本语言模型以及11B和90B的多模态版本,基本上算是Llama3.1的补充。
本次发布的Llama3.3-70B-Instruct官方也介绍说是后训练技术的迭代,这意味着其基座模型可能还是Llama3.1-70B,只是用不同的后训练或者指令微调技术迭代获得的。
Llama3.3-70B-Instruct的训练成本和开源情况
Meta公布的信息显示,Llama3.3-70B-Instruct模型训练花费了700万个GPU小时。主要是在H100-80G上训练,按照AWS的价格,这个成本大约430万美元了!
实话说,这不是一般人搞得起来的。不过好消息是Llama3.3-70B-Instruct开源,且支持免费商用。具体情况参考DataLearnerAI的模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/llama3_3_70B_instruct
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
