HTML是AI输出的新标准吗?一个来自Anthropic工程师的挑衅性论断
Markdown是当前所有大模型生成内容的默认格式。这件事情如此理所当然,以至于大部分人从没想过为什么——其实原因很简单:大模型的全称是大语言模型,生成的就是文本(先不考虑多模态的情况),而Markdown只需要纯文本就能渲染出标题、列表、加粗、代码块等基本格式。成本低、兼容性好、工具链成熟,几乎是天然的最优选择。
但Anthropic Claude Code团队的工程师Thariq最近提出了一个不同的看法。2026年5月8日,他发了一篇文章,标题很直接:《Using Claude Code: The Unreasonable Effectiveness of HTML》,核心观点是——Markdown不够用了,HTML才应该是大模型输出的新标准。
这篇文章发布当天获得了超百万次浏览、近9000个赞和超过11000个书签。很多人表示赞同,比如Simon Willison(Django联合创始人、知名开发者博主)就公开说自己正在重新审视三年来默认使用Markdown的习惯,Hacker News相关讨论也迅速进入热门。当然,也有很多人公开表示怀疑。
但不管怎样,这不是一个玩笑式的观点。Thariq提供了完整的论证材料,值得认真对待——也值得认真质疑。
Thariq的逻辑:写文档的不是人类了,为什么还在用为人类设计的格式?
Thariq的出发点其实很好理解。Markdown这个格式是2004年由John Gruber设计的,当时的目标就一个:让人类能用纯文本快速写出HTML结构。换句话说,Markdown本质上是HTML的简化版——为了让人写得更快,牺牲了大量的表达能力。没有并排布局、没有交互、没有内嵌SVG图表、没有颜色标注、没有动画。
这个牺牲在人类写文档的时代完全合理。但Thariq的问题是:当写文档的主体变成了AI,"让人写得更快"这个设计假设还成立吗?AI不需要快速输入,它每秒可以输出几千个token。它需要的是一个能完整表达意图的格式——而HTML作为浏览器的原生语言,天然就支持Markdown做不到的那些东西。
为了证明这一点,Thariq不只是写了篇文章,还专门搭了一个展示站(thariqs.github.io/html-effectiveness),放了20个用AI生成的单文件HTML,覆盖9类工作场景:探索与规划、代码审查、设计系统、原型交互、图表插图、幻灯片、研究学习、报告、以及自定义编辑界面。基本上开发者和技术团队日常会碰到的文档类型,他都覆盖了。
这20个例子说明了什么?HTML胜出的其实只有三个原因
逐个看完这20个例子会发现,HTML赢在不同场景的原因其实可以归结为三类。理解这三类比记住20个具体例子有用得多,因为你可以直接判断自己日常的工作场景属于哪一类。
第一类:信息本身是二维的,Markdown强行压成一维就丢东西了。
比如Thariq展示的代码方案并排对比、diff注释、模块关系图、设计色板、周报和事故时间线,都属于这一类。这些内容的共同特点是需要横向比较或者全局扫视。Markdown只能从上到下串行排列,你看完方案A再翻回去对照方案B,得在脑子里自己做空间重建。HTML直接渲染成两列或三列,扫一眼就能完成对比。
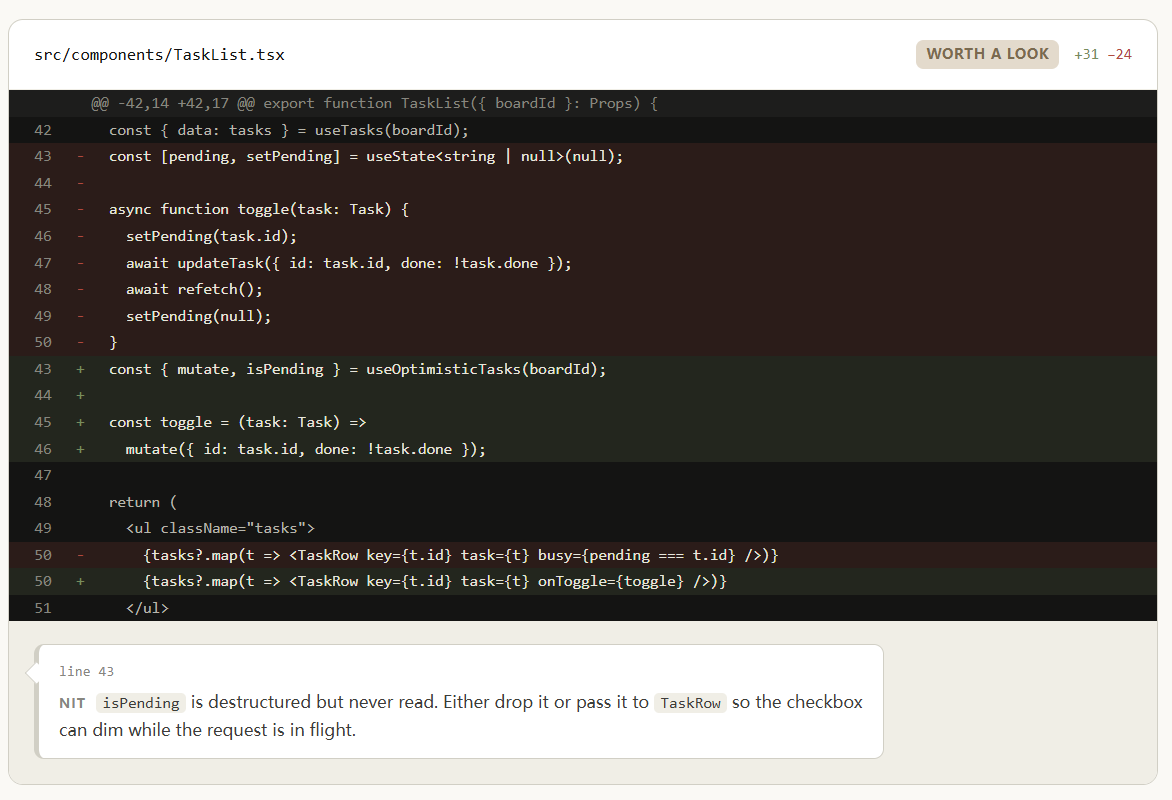
diff和调用图是更典型的例子。这些信息天然就是空间结构的,强行压成线性文本不是格式偏好的问题,是信息维度的丢失。
第二类:内容必须通过交互才能理解,静态文字描述无论写多好都差一个量级。
这类例子包括动画沙盒(可以拖滑块调缓动曲线)、可点击的多屏原型流程、一致性哈希环的实时增删节点演示、以及左边编辑Prompt模板右边实时预览的调试器。在这些场景里Markdown不是"弱一些"的问题——它根本做不了这件事。一个能动态调整的可视化,和一段描述这个可视化的文字,传达效率差的是数量级。
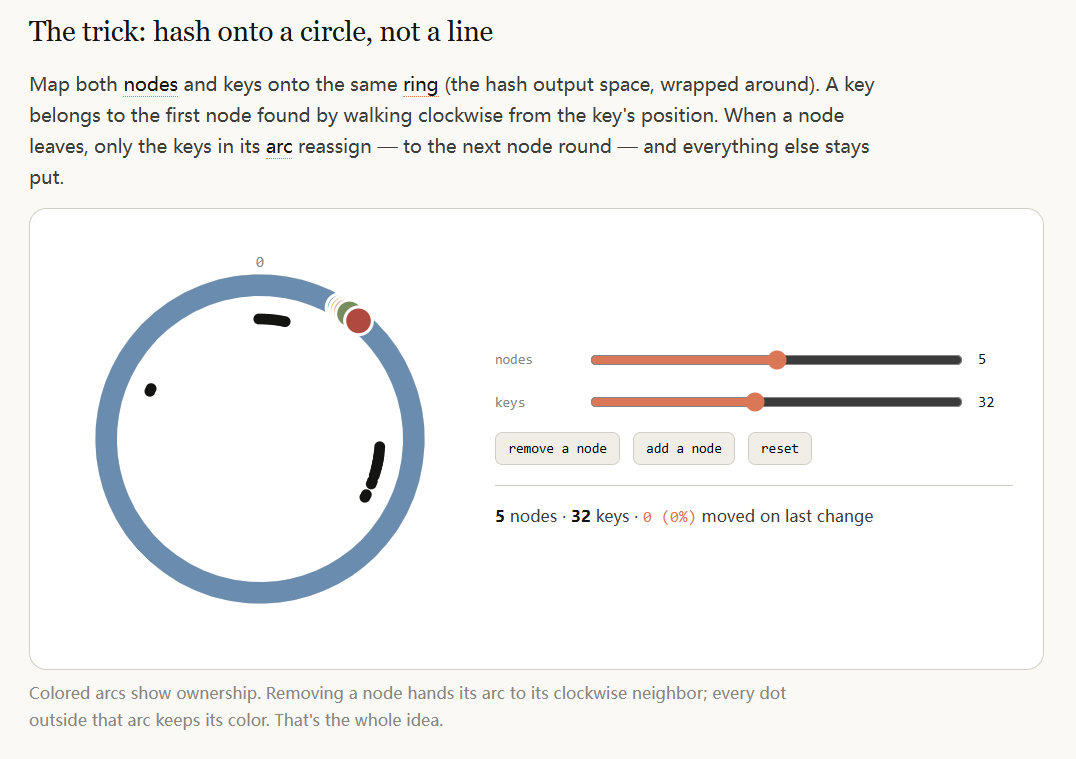
这也是Thariq的论点里说服力最强的部分:对于交互性需求,HTML和Markdown之间没有取舍空间,只有"能做"和"不能做"。
第三类:HTML本身就是内容的原生语言,用Markdown描述HTML是绕了一圈路。
设计系统的色板渲染、组件在不同状态下的展示、用几个HTML标签搭出来的可翻页幻灯片——这些场景下HTML不是"更好的格式",而是内容本身就活在HTML里。把设计token渲染成色块,远比列出一堆十六进制代码直观。组件状态直接展示出来,远比用文字描述"hover时颜色变深"有效。用Markdown先降维再让读者自己脑补还原,是一个不必要的弯路。
另外值得单独提一下他展示的自定义编辑界面(任务看板、Feature Flag编辑器),它们有一个有意思的设计模式:用户在HTML界面里通过拖拽完成操作,然后通过"Export"按钮把结果转回Markdown或JSON等可被Agent消费的格式。HTML在这里是交互层,不是终点。这个思路后面讨论"最终解"的时候会再提到。
不过,Thariq的论断还是太绝对了
先说清楚一件事:Thariq讨论的其实是一个比较窄的场景——"AI生成、供人类阅读的最终产物",比如PR说明、技术报告、概念讲解、设计审查文档。他不是在说Agent之间传递中间结果应该用HTML,也不是在说版本控制的文档应该用HTML。这些场景里Markdown甚至纯文本仍然是更合理的选择,因为机器不需要渲染丰富性,要的是可解析和轻量。
理解这个边界之后,我们能更准确地评价他的观点。在他定义的场景内,HTML的表达能力确实有结构性优势。但"HTML is the new markdown"作为一个实际的操作建议,在当下有两个绕不过去的问题。
第一个是成本。 一个完整的富格式HTML文件,包含内联CSS、JavaScript和SVG,token量可能是等效Markdown的5到10倍。在当前的API定价下,这不是可以忽略的差异,尤其对于高频调用的场景。
第二个是速度。 更多的token意味着更长的生成时间。在需要即时反馈的交互场景里,等AI把一整个带CSS和JS的HTML文件吐完,体验上和Markdown的差距是肉眼可见的。
Thariq本人其实有应对这个问题的工程实践——他之前专门写过一篇关于prompt caching的文章。Claude Code的运行框架建在高cache命中率上,HTML文件中固定不变的CSS和JS部分可以被cache住,模型只需要生成变化的内容。这样实际的token成本比直觉上低不少。但问题是,这依赖于对运行框架的精细设计,不是一个普通用户或开发者开箱即用就能得到的效果。
当然,这两个约束有一个重要的特征:它们都是时限性的,不是结构性的。token成本和生成速度的下降趋势非常清楚,每隔半年就是一个量级的变化。"HTML太贵太慢"这个反驳今天成立,但一两年后可能就不成立了。
一个有用的类比:Excel为什么没有被Google Sheets取代?
聊到这里可以引入一个类比来帮助思考。Excel在"网页时代"活下来了,不是因为它功能比Google Sheets更强,而是因为它在受约束的环境下更稳定:本地计算不依赖网络、大数据集处理延迟低、VBA宏生态完整、和本地文件系统无缝集成。Google Sheets在协作和分发上更好,但在性能敏感的场景里一直赢不了原生应用。
如果做映射的话,Markdown更像Excel——功能有限但高效、轻量、可离线、版本控制友好、工具链成熟;HTML更像Google Sheets——表达能力更强,但有性能开销和环境依赖。
这个类比有两层含义。第一层是:Excel没有因为Google Sheets的出现而消失,两者在不同场景下共存。Markdown和HTML大概率也会是这样——不是替代,而是场景分化。
第二层更值得注意:Excel之所以能活下来,依赖的核心优势是性能,而性能优势的来源是硬件和网络的约束。一旦这些约束消失,网页应用会逐步侵蚀它的领地(事实上这件事已经在发生了)。同理,Markdown的核心优势是token效率和生成速度,如果这些约束继续快速消解,"Markdown更高效"的论据也会随之弱化。
那大模型生成结果最终解到底是什么?可能不是HTML,也不是Markdown
Thariq指出了正确的方向,但HTML本身可能也不是终点。毕竟HTML是一个"为人类浏览器设计"的格式,规范里装着三十年的历史包袱——跨浏览器兼容、向后兼容、复杂的渲染模型。AI生成文档完全不需要这些东西。
一个更合理的预期是:最终会出现一种"AI-native"的输出格式,既有HTML级别的表达丰富度,又有接近Markdown的生成效率。目前已经有几个方向在往这个方向收敛:
第一种是结构化数据加前端渲染分离。模型只输出语义结构(比如JSON),渲染逻辑固定在客户端模板里。模型实际生成的内容量很小,但最终呈现的效果可以和完整HTML一样丰富。Claude Artifacts和ChatGPT Canvas本质上都在走这条路——模型维护一个状态化的文档对象,不是每次从头生成全量HTML。这个架构的token效率远高于直接生成HTML。
第二种是模板填充模式。AI在预定义的HTML模板里填写变量槽位,而不是从空白开始生成完整文件。成本结构接近Markdown,输出质量接近手写HTML。在当前的成本约束下,这可能是最现实的中间路径。
第三种可能性更远一些:一个全新的语义格式标准。类似XML当年试图做但没做成的事——既有语义结构又有渲染指令,同时比HTML轻量得多。如果Agent间协作的规模继续扩大,对这种格式的需求会越来越强,有人会造出来的。
前面提到的那个"HTML作为交互层、Export按钮转回机器可读格式"的设计模式,其实已经在暗示这个方向:输入输出用轻量格式,呈现层用富格式,两者通过一个明确的转换接口连接。未来的"最终解"很可能就是把这个模式标准化。
总结
Thariq的核心观察是对的:Markdown的设计假设来自"人类需要快速书写",在AI生成文档的场景下这个假设不再成立,HTML在表达能力上有结构性优势。他用20个实例证明了这一点,覆盖了大部分开发者日常的文档场景,论据是扎实的。
但"HTML is the new markdown"作为一个当下就能执行的建议,在token成本和生成速度的约束完全消解之前还是太绝对了。更准确的说法可能是:HTML展示了AI文档输出应该走的方向,但当前的最优实践是按场景选择——需要交互和视觉丰富度的最终产物用HTML,需要轻量和可解析的中间格式继续用Markdown。两者是分工关系,不是替代关系。
往更远看,Markdown和HTML可能都不是终点。真正的"最终解"应该从AI文档的第一性原理出发——优化目标既不是"人类写得快",也不是"浏览器渲染得好",而是"AI生成高效、呈现丰富、人类直接可读"。这个格式今天还不存在,但从Claude Artifacts、ChatGPT Canvas这些产品的演进方向来看,它的轮廓已经开始显现了。
