OpenAI开源GPT-2的子词标记化神器——tiktoken,一个超级快的(Byte Pair Encoder,BPE)字节对编码Python库
4,782 views
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。
BPE简介
字节编码对(Byte Pair Encoder,BPE)是一种子词处理的方法。其主要的目的是为了压缩文本数据。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。
关于BPE的详细介绍请参考:自然语言处理中常见的字节编码对(Byte-Pair Encoding,BPE)算法简介
其它一些流行的子词标记化算法包括WordPiece、Unigram和SentencePiece。而BPE用于GPT-2、RoBERTa、XLM、FlauBERT等语言模型中。这些模型中有几个使用空间标记化作为预标记化方法,而有几个使用Moses, spaCY, ftfy提供的更高级的预标记化方法。
tiktoken简介
前天,OpenAI开源了GPT-2中使用的BPE算法tiktoken,并以Python库的形式开源。官方宣称该库做BPE比HuggingFace的tokenizer快好几倍,其对比如下:
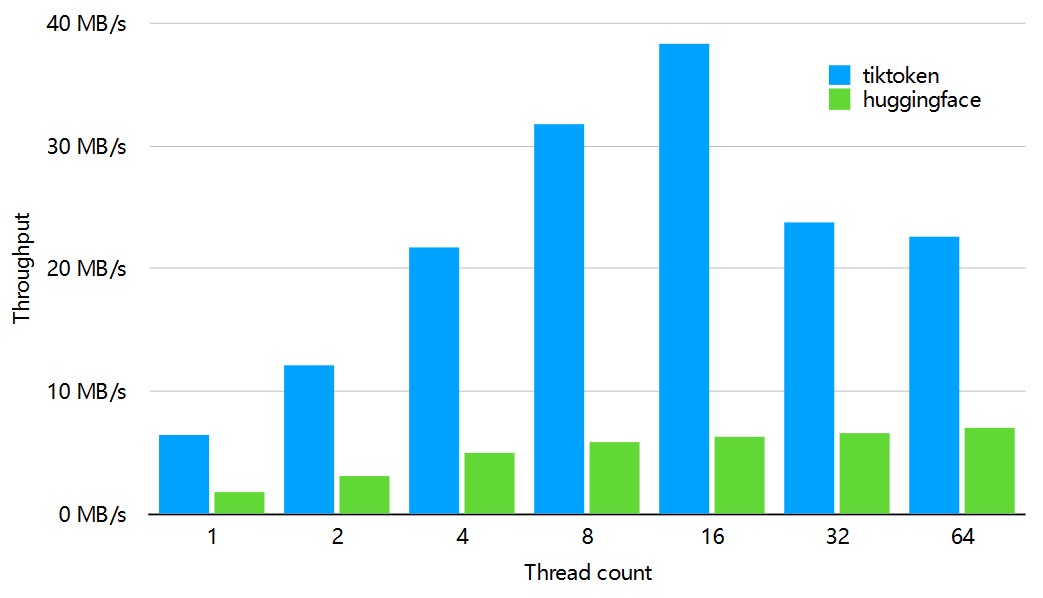
可以看到,在不同线程数下面,tiktoken处理速度都比HuggingFace快多了,各种条件下都比tokenizer快3-6倍。
上述对比是处理1GB数据的结果。
tiktoken使用
tiktoken使用方法也很简单。示例代码如下:
import tiktoken
enc = tiktoken.get_encoding("gpt2")
# 字节对编码过程,我的输出是[31373, 995]
encoding_res = enc.encode("hello world")
print(encoding_res)
# 字节对解码过程,解码结果:hello world
raw_text = enc.decode(encoding_res)
print(raw_text)
如下图所示:

tiktoken官方开源地址:https://github.com/openai/tiktoken
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
