OpenAI发布GPT-5:这是一个包含实时路由的AI系统,而不仅仅是一个模型
几个小时前,OpenAI发布了全新一代大模型GPT-5系列。本次发布的是一个全新的AI系统,而非一个单独的模型系列。GPT-5背后包含了5个不同的模型系列或者版本,分别是GPT-5-Pro、GPT-5、GPT-5-mini、GPT-5-nano和GPT-5-Chat。
其中GPT-5-Pro使用更多算力并行推理完成非常复杂的任务。
GPT-5是一个统一的AI系统
GPT-5最引人注目的创新之一是其“统一系统”架构。这意味着它不再是单一的模式,而是一个集成了多个模型的智能系统。系统内部包含一个能够快速响应大多数问题的标准模型,以及一个用于处理复杂、高难度问题的深度“思考模型”(GPT-5 thinking)。
简单来说,GPT-5的模型是一个模型支持思考推理模式和非思考推理模式。
此外,GPT-5还有一个实时的智能路由器会根据用户提问的类型、复杂程度以及是否需要使用工具等因素,在毫秒之间决定调用哪个模型。比如,当用户发出“请深入思考这个问题”之类的指令时,系统会自动启用深度思考模型。这种设计确保了用户总能以最高效的方式获得最优质的答案。这个看起来并不是一个大模型的任务,似乎有点像正则?
GPT-5包含3个不同的模型,还有2个特殊的版本
其实GPT-5包含了3个不同版本的模型,介绍如下:
同时,OpenAI还有2个不同模式的GPT-5,分别是GPT-5 Chat和GPT-5-Pro。前者是ChatGPT中的GPT-5模型,后者则是使用多个推理并行执行的GPT-5专业版本。其中,GPT-5-Pro仅通过ChatGPT网页版提供,面向Pro付费用户。
同时,官网还给出了GPT-5模型的替代关系:
可以看到,OpenAI是将原有的不同的模型系列,整合到了一个模型中,然后GPT-5支持不同的模式后来替代这些旧模型。
GPT-5系列模型的核心特点
GPT-5在多个领域展现了卓越的性能,尤其在以下三个方面取得了显著进步:
-
编程与开发:GPT-5是迄今为止OpenAI最强大的编程模型。 它在处理复杂的前端代码生成、大型代码库调试等方面表现尤为出色。测试者发现,GPT-5仅通过单个提示就能创建出界面美观、响应迅速的网站、应用甚至迷你游戏,并对UI设计中的空间感、排版和留白有更好的理解。
-
创意写作与表达:作为一名写作协作者,GPT-5的能力达到了新的高度。它能够更好地处理具有结构模糊性的写作任务,例如创作无韵律的五音步诗或自然的自由诗,将文学形式与清晰的表达力融为一体。 这使得它在起草和编辑报告、邮件等日常写作任务时也更加得心应手。
-
健康领域:在处理健康相关问题时,GPT-5展现了更高的准确性和可靠性。 它在权威的HealthBench评估中得分远超以往所有模型。 新模型更像一个主动的“思想伙伴”,会主动标记潜在问题并提问,以提供更有帮助的回答。 当然,OpenAI也强调,GPT-5不能取代专业的医疗人员,而是作为帮助用户理解信息、做好准备的辅助工具。
GPT-5的评测结果
GPT-5的评测数据很多,官方给的数据也不是很全面。我们先挑选几个可以对比的模式进行对比。
首先是非推理模式下,GPT-5和GPT-4o的对比结果:

可以看到,如果不使用思考模式和工具,那么GPQA Diamond这种困难的科学问题上,GPT-5提升10%左右(70.1 -> 77.8),而在人类最后难题HLE上提升18.8%左右(5.3->6.3)。如果允许GPT-5使用推理模式和工具,那么提升更明显了,两个评测的提升分别可以达到24.5%和564%!
在都可以使用工具的情况下,我们找到了AIME 2025的测试(美国高中数学竞赛邀请赛):

提升也是十分明显的。
最后,我们看一下使用并行推理的GPT-5-Pro和之前最强的类似模式的Grok 4 Heavy和Gemini 2.5 Pro Deeper Thinking的对比。Grok 4是马斯克旗下xAI公司发布的一个并行推理且使用工具解决问题的一个Agent系统,而Gemini 2.5 Pro Deeper Thinking也是类似,三者都是针对复杂问题使用多个并行推理任务完成的模式。

可以看到,没有使用工具的GPT-5-Pro与其它两个模型的对比都不太好。而使用工具之后GPT-5-Pro似乎与其它模型的差距也不大。
GPT-5的安全性与可靠性的升级
为了构建一个更稳健、可靠和有益的模型,OpenAI在GPT-5的安全性方面投入了大量精力:
- 大幅减少幻觉:GPT-5产生事实性错误的频率显著低于以往模型。在一项测试中,其包含事实错误的回答比GPT-4o少了约45%。
- 回应更诚实:当面对无法完成或信息不足的任务时,GPT-5能更诚实地承认其局限性,而不是像旧模型那样编造答案。
- 全新的“安全完成”训练:GPT-5引入了一种新的安全训练范式。它不再是简单地拒绝敏感问题,而是学会在安全边界内尽可能提供有帮助的、高层次的回答,从而更好地处理那些具有两用性的问题(如生物学)。
- 减少“谄媚”行为:新模型减少了不必要的附和、过度的表情符号和奉承,使其交流风格更像一个有帮助且具备博士级智力的朋友。
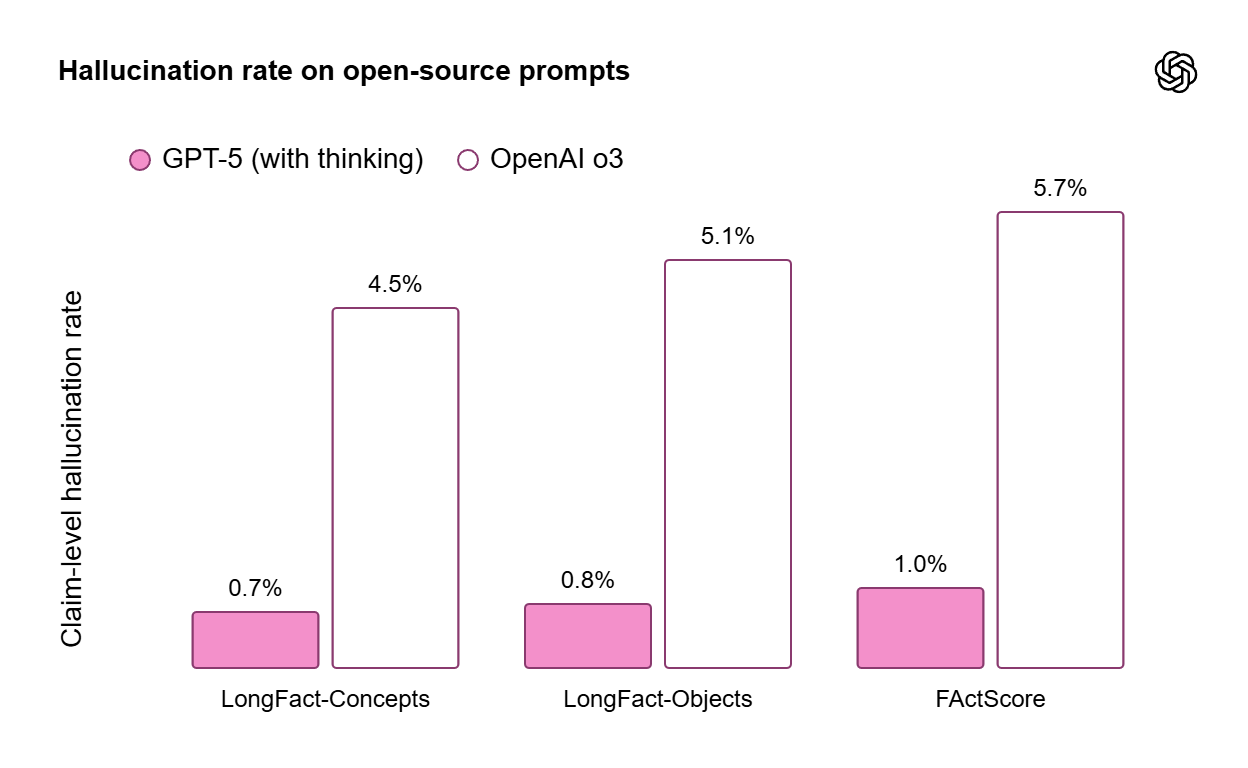
这些虽然归属安全和可靠性,但是在实际解决问题中对用户的体验来说非常有价值。特别是幻觉方面,与OpenAI o3模型相比,大幅下降:
GPT-5总结
GPT-5 通过统一路由、深度推理分级、安全补全机制,将 GPT-4o 时代的速度与多模态体验进一步推向高可靠、高专业度场景。对开发者而言,更大的上下文、更灵活的控制、以及显著降低的幻觉与阿谀,意味着从应用到 Agent 架构都能获得直接红利。现在就可以:
- 在 ChatGPT 体验默认模型并观察思考路径差异;
- 在 API 将
model=gpt-5替换到现有工作流,或按需切换mini / nano; - 参考 Cookbook 的新提示模式,验证输出一致性与成本;
- 关注 System Card 提到的安全最佳实践,将“安全补全”理念融入产品设计。
关于GPT-5更多信息可以参考DataLearnerAI模型信息卡: https://www.datalearner.com/ai-models/pretrained-models/gpt-5 https://www.datalearner.com/ai-models/pretrained-models/gpt-5-pro
