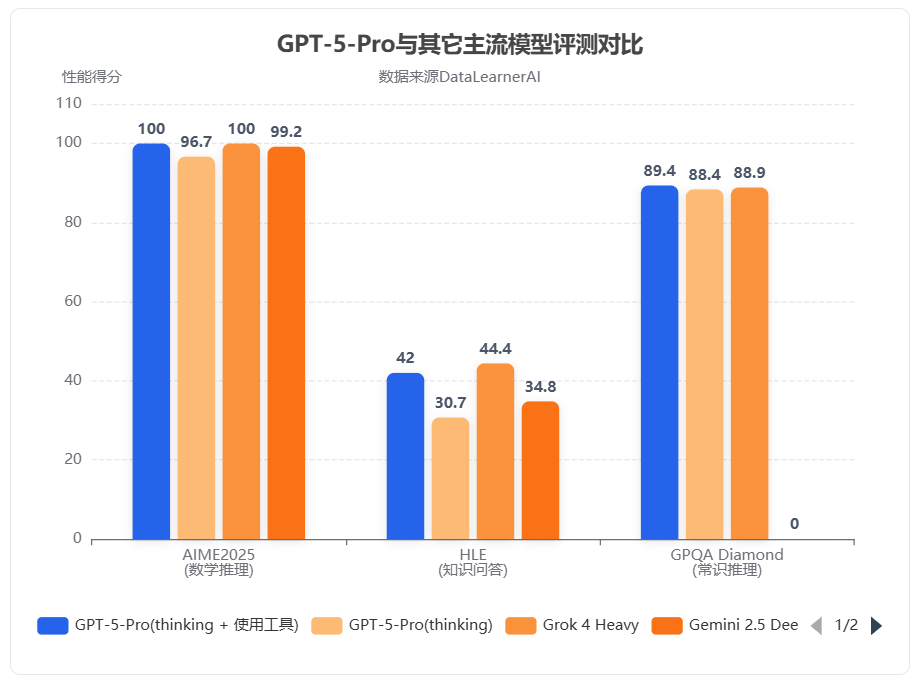
OpenAI 发布 GPT-5.5:代号"Spud",Agent 能力明显提升,API 因安全审查暂缓开放
OpenAI 于北京时间4月24日正式发布 GPT-5.5,内部代号"Spud"。距离 GPT-5.4 发布只有大约六周,这个节奏说明头部实验室现在基本上是滚动迭代而不是等大版本攒够了再发。GPT-5.5 即日起向 ChatGPT 的 Plus、Pro、Business 和 Enterprise 用户以及 Codex 用户开放,GPT-5.5 Pro 面向 Pro、Business 和 Enterprise。API 这边因为需要额外的网络安全防护验证,暂时没有同步上线,OpenAI 说"很快"会跟上。