【辟谣,该数据是预测】重磅!疑似GPT-5评测结果泄露,超过当前所有模型评分,人类最后难题得分56.6,比当前最好模型还要高27%,大幅超过Gemini 2.5 Pro,Grok 4 Heavy等
----------更正:数据已经辟谣,来源推友预测
就在刚才,X平台出现疑似GPT-5的评测结果。结果显示,在所涉及的四项评测中,GPT-5均排名第一。

尽管OpenAI官方尚未发布明确信息,但此前有传闻称GPT-5模型或将于2025年7月发布。而流传的评测数据显示,GPT-5在四项具有挑战性的评测中均获得第一,且得分大幅领先于现有其他模型。
根据泄露的信息,此次评测包含两个不同版本的GPT-5,分别是基础版GPT-5以及一个具备增强推理能力的GPT-5 Reasoning版本。具体评测结果如下图所示:
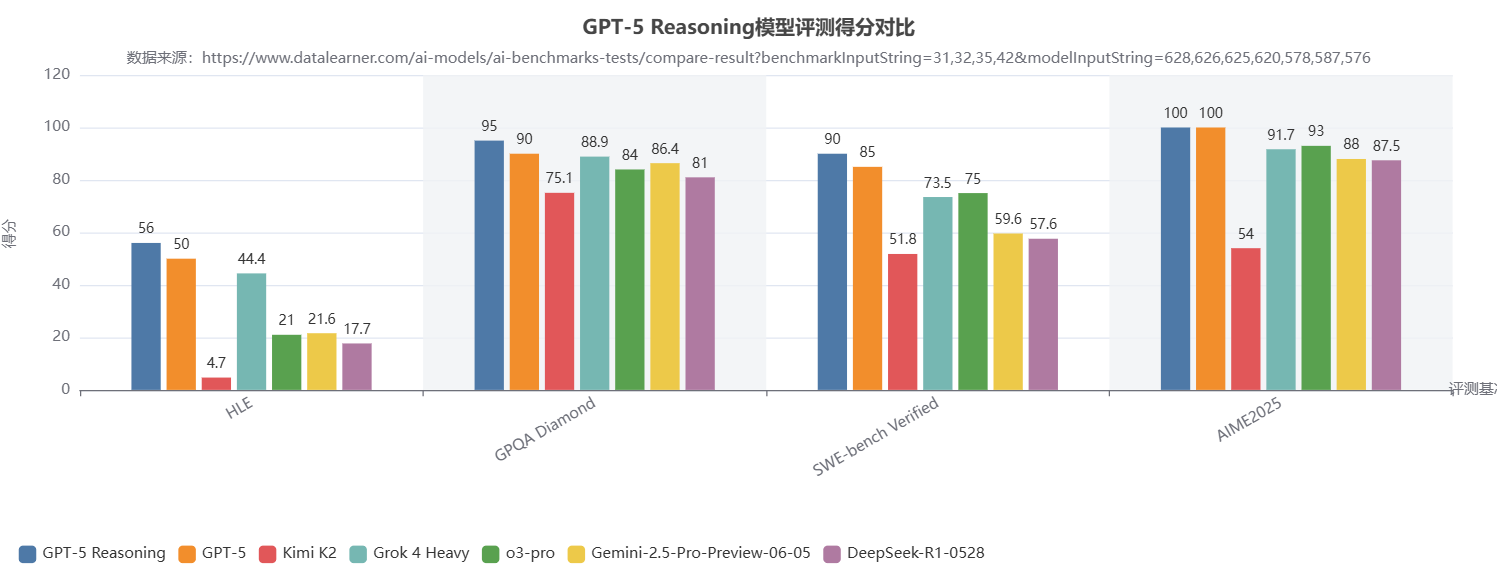
从图表数据来看,GPT-5的表现在多方面均超越了其他模型,主要体现在以下几点:
- 各版本全面领先:在所有四个评测基准上,GPT-5的两个版本(特别是"Reasoning"版)都显著优于图表中列出的其他所有模型,包括Grok 4 Heavy、Gemini-2.5-Pro等。
- "Reasoning"版本性能更优:与标准版"GPT-5"相比,"GPT-5 Reasoning"在知识问答(HLE)、常识推理(GPQA Diamond)和代码生成(SWE-bench)上均有明显优势,而在数学推理(AIME2025)上则与标准版持平,均为满分。
- 数学与代码能力实现突破:两个GPT-5版本在AIME2025(数学推理)上均取得了100分的满分,在SWE-bench(代码生成)上也取得了90分和85分的高分。这表明其在逻辑、推理和工程能力上可能取得了重大突破。
下面将对每个评测基准的表现进行逐一分析:
1. HLE (Humanity’s Last Exam) 知识问答
HLE是由Safety for AI和Scale AI的研究人员共同推出的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。其题目筛选流程十分严格:
- 自动过滤:使用GPT-4o、Claude 3.5等顶尖模型进行初步测试,只有所有模型均答错的问题才能进入下一轮。
- 同行评审:首轮由至少三名同领域专家进行评分,淘汰模糊或易于通过检索找到答案的问题。
- 终审委员会:由资深研究者组成的团队进行最终批准,重点关注问题的原创性和学科深度。
该评测因其高难度而被部分观点称为“人类最后的难题”,意指如果大模型能解决这些问题,其能力或可被认为超越了人类专家。在此项评测中,GPT-5的得分遥遥领先。
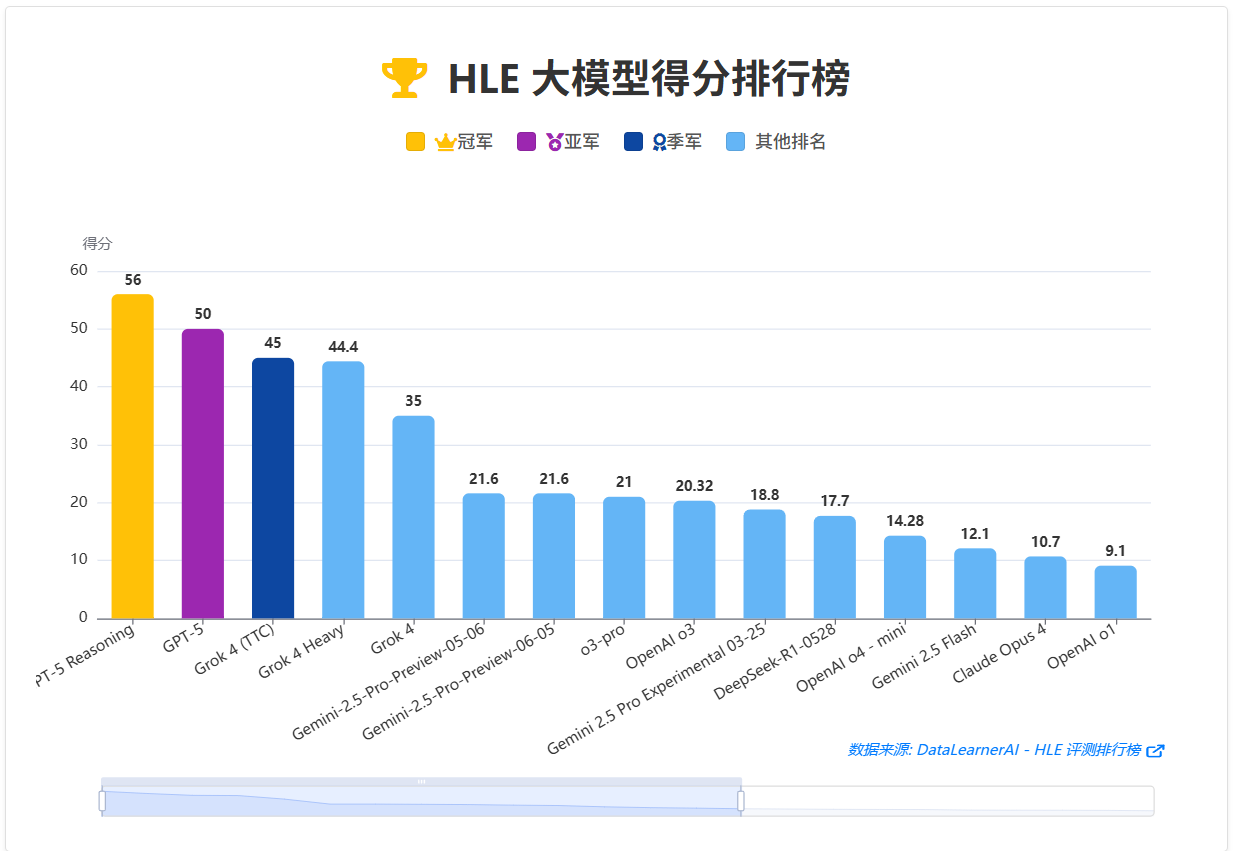
两个GPT-5版本在此项评测上得分领先。最接近的Grok 4 Heavy得分为44.40,而GPT-5 Reasoning的得分为56.6,高出约27%。即便是基础版的GPT-5,其得分也高出Grok 4 Heavy约12%。值得注意的是,Grok 4 Heavy的成绩是基于多智能体并行推理并择优得出的。
2. GPQA Diamond 常识推理
该基准旨在评估模型解决需要专家级别理解和推理能力的问题,其数据集主要来自公开的研究生级别或竞赛级别问题,覆盖物理、化学、生物学和经济学等STEM领域。
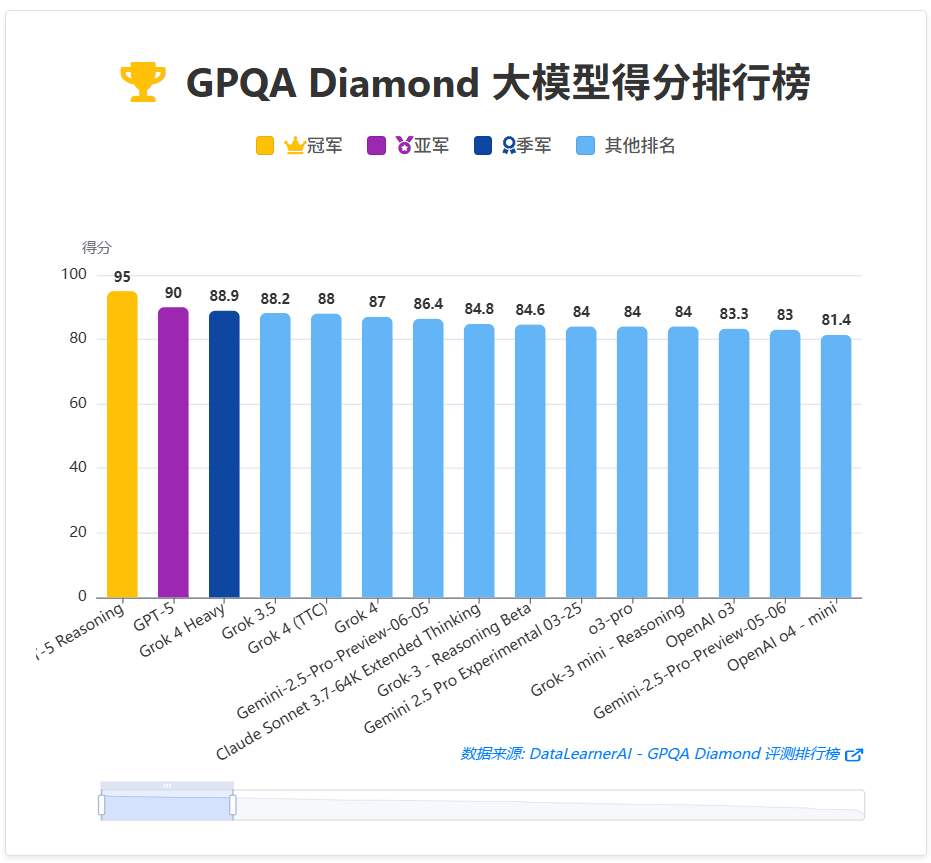
该基准用于衡量模型的常识和深度推理能力。在此项评测中,GPT-5的两个版本再次占据前两名,并且是图表中唯一得分超过90分的模型。
3. SWE-bench Verified 代码生成
SWE-bench旨在提供一个可靠、精确的评估工具,以全面了解AI模型在处理软件工程任务时的能力。它的问题来自GitHub知名项目的真实议题(issues),要求模型根据给定的代码库和问题描述生成修复补丁,并通过相关的单元测试来验证修复的有效性。
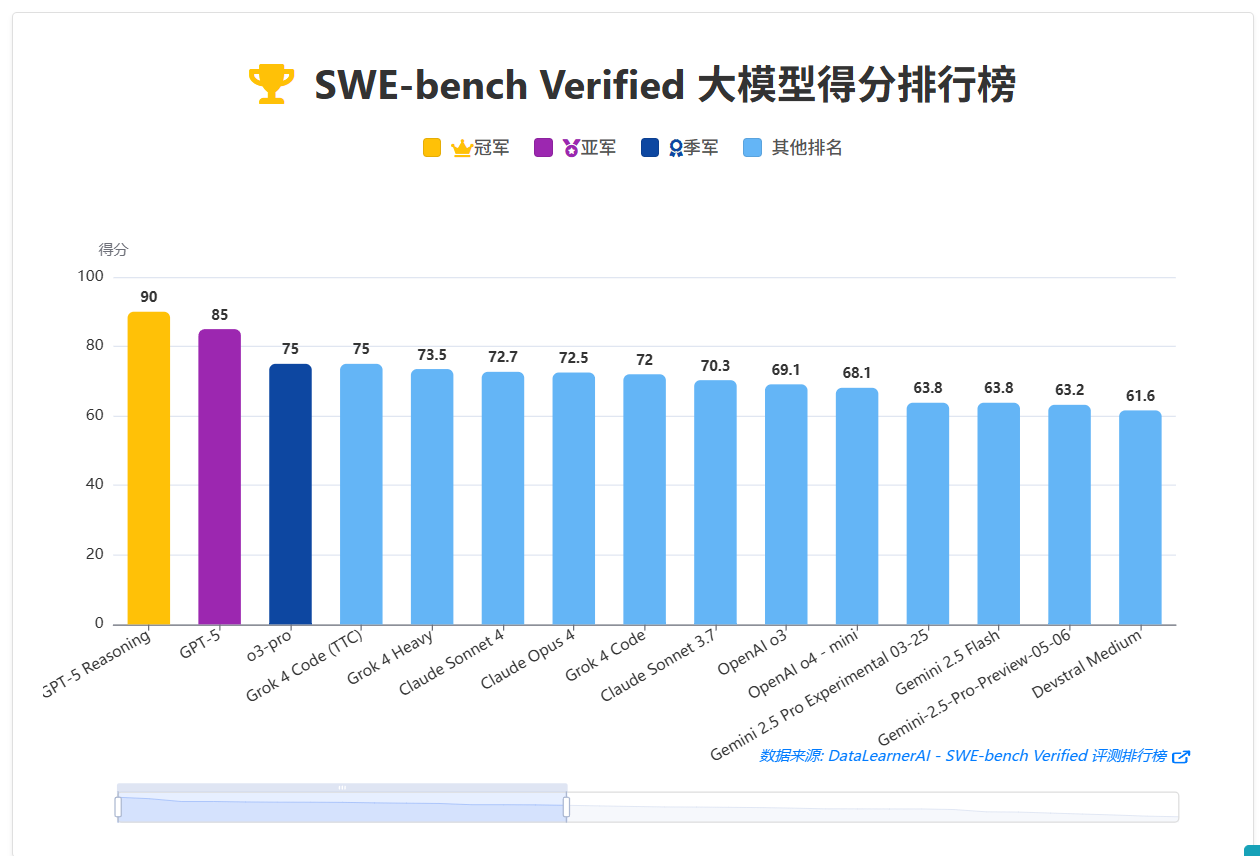
GPT-5 Reasoning在此项评测中取得了90分,这意味着模型有能力独立解决大量真实的软件工程任务和错误修复。在所有参与评测的模型中,GPT-5是唯一得分超过75分的模型,展现出显著的领先优势。
4. AIME2025 数学推理
在AIME2025(美国高中数学邀请赛)评测中,两个GPT-5版本均获得了满分。如果数据属实,这可能标志着AI在高等数学推理能力上达到了一个新的里程碑。
结论与展望
若此次泄露的数据可靠,则表明GPT-5相较于当前市面上的顶尖模型,可能代表着一次代际飞跃,尤其是在被视为AI核心能力的“推理”方面。
- "GPT-5 Reasoning" 可能是OpenAI计划推出的一个“专业版”或增强版模型,专为需要顶级智能的科学研究、软件开发和复杂问题求解等场景设计。
- 标准版"GPT-5" 则可能作为性能和成本更均衡的通用模型,面向更广泛的用户和应用。
重要提示:在OpenAI官方正式发布和提供独立第三方评测结果之前,当前流传的数据仅供参考。
关于GPT-5的后续官方信息,DataLearnerAI将持续关注并第一时间更新,相关信息可在其模型信息卡页面查看:https://www.datalearner.com/ai-models/pretrained-models/gpt-5
