Stable Diffusion的Tensorflow/Keras实现及使用
最近一段时间Text-to-Image模型十分火热。OpenAI的DALL·E2模型的效果十分惊艳。不过,由于Open AI现在的不Open策略,大家还无法使用这个模型,业界只开放了一个小版本的DALL·E mini。不过,前段时间,Stability AI发布的Stable Diffusion其效果明显好于现有模型,且免费开放使用,让大家都开心了一把。不过原有模型是Torch实现的,而现在,基于Tensorflow/Keras实现的Stable Diffusion已经开源。
相比较原有的模型,该模型的运行速度要快4倍(基于8GB的M1 MacBook Air的笔记本测试)。
下图是测试的结果:
输入: A epic and beautiful rococo werewolf drinking coffee, in a burning coffee shop. ultra-detailed. anime, pixiv, uhd 8k cryengine, octane render
输出:

这个版本的Stable Diffusion是由Meta的研究人员 Divam Gupta开发,其主要的特点:
- 转换后的预训练模型
- 很容易理解代码
- 代码量尽量少
使用方法
从项目地址将项目下载:https://github.com/divamgupta/stable-diffusion-tensorflow
然后将zip包解压到某个目录。
注意,这个项目需要依赖几个包:
pillow
tensorflow
tensorflow_addons
tqdm
ftfy
regex
但是这些包都很容易安装,问题不大。注意,第一个pillow一定要安装,否则迭代结束会报错,浪费很久。接下来直接进入解压后的目录运行如下命令:
python text2image.py --prompt="An astronaut riding a horse"
运行过程如下:
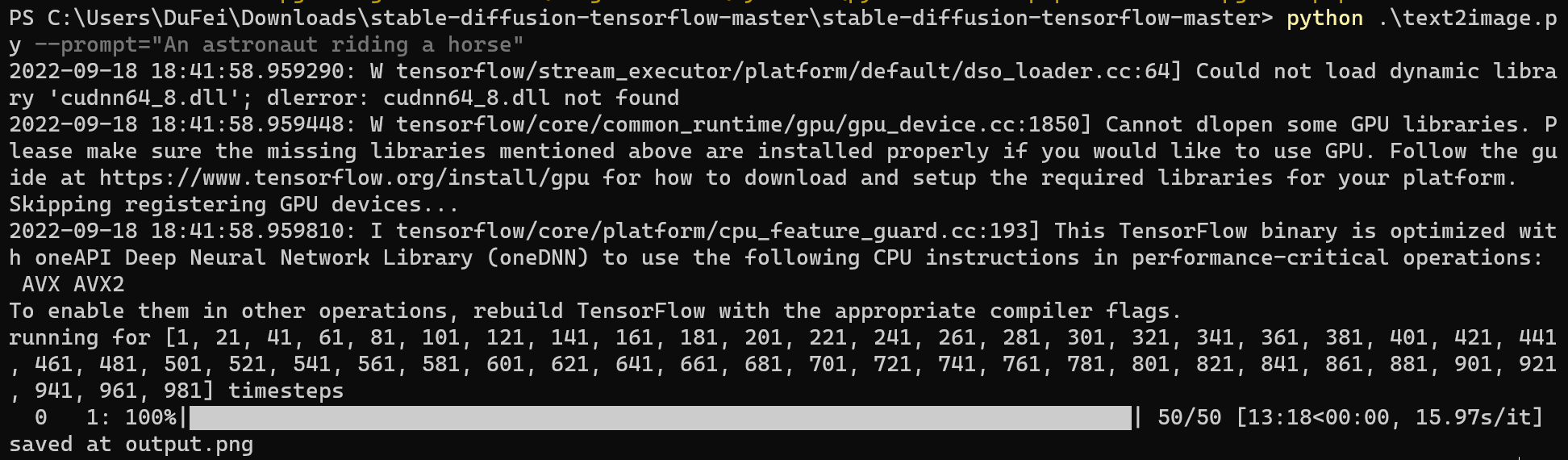
可以看到,会运行50代,一代约16秒,有点慢。不过我这是CPU版本的tensorflow。
需要注意的是,这个第一次运行会从hugging face上下载模型文件,总共有3个,总大小约4GB。建议上梯子。

这是我跑的结果。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
