Cerebras GPT
基础大模型Cerebras GPT
Cerebras GPT 是由 Cerebras Systems 发布的 AI 模型,发布时间为 2023-03-28,定位为 基础大模型,参数规模约为 130亿,上下文长度为 2K,模型文件大小约 51.6GB,采用 Apache 2.0 许可。
数据优先来自官方发布(GitHub、Hugging Face、论文),其次为评测基准官方结果,最后为第三方评测机构数据。 了解数据收集方法
模型基本信息
开源和体验地址
官方介绍与博客
API接口信息
评测结果
和其他模型对比
暂时没有为该模型整理的相关对比页面。
想自定义其他组合?打开对比工具
发布机构
模型解读
Cerebras GPT是由Cerebras公司开源的自然语言处理领域的预训练大模型,其模型参数规模最小1.11亿,最大130亿,共7个模型。下图展示了模型参数规模与训练结果的关系。
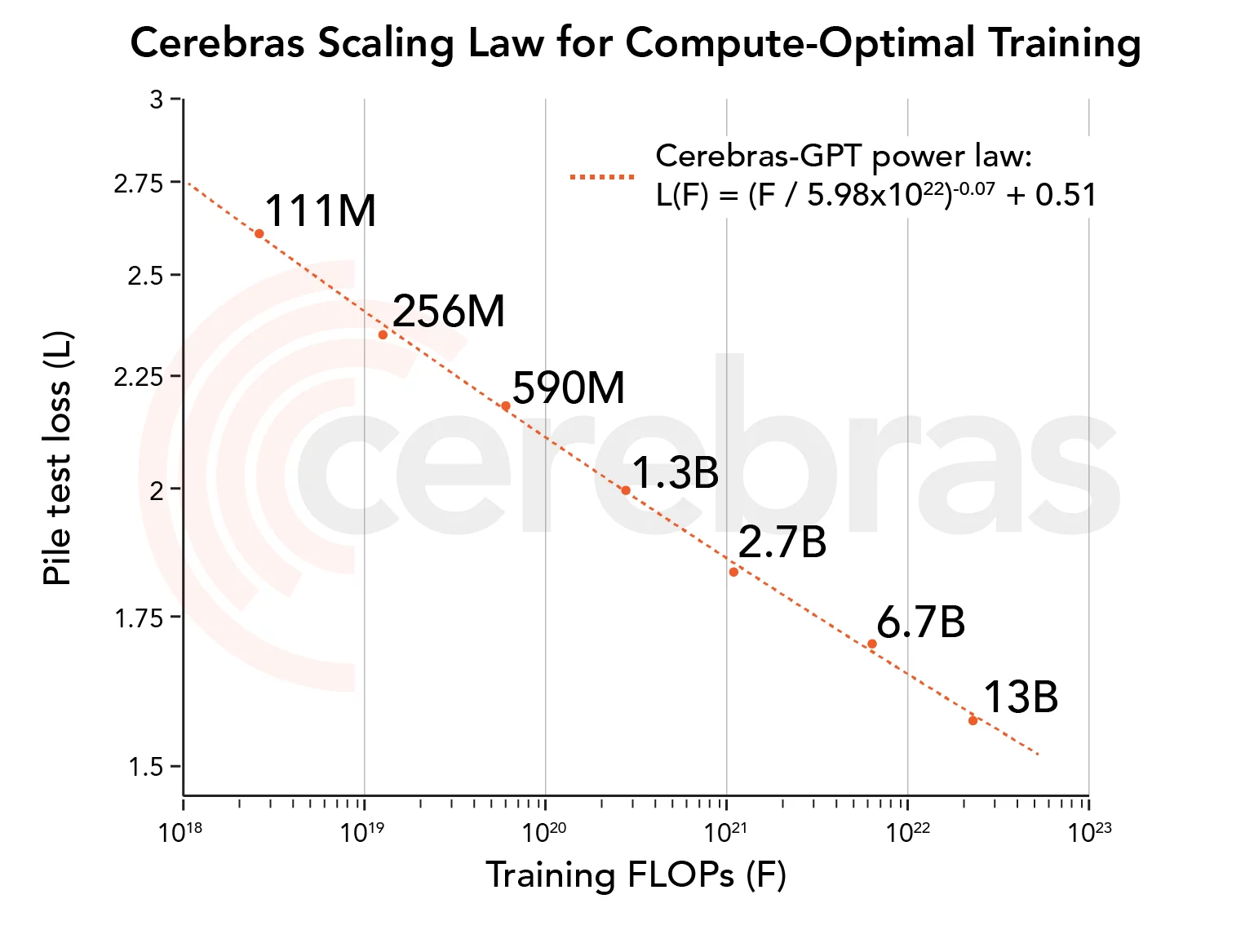
人工智能有改变世界经济的潜力,但它的访问越来越被限制。最新的大型语言模型——OpenAI的GPT4——发布时没有关于其模型架构、训练数据、训练硬件或超参数的信息。公司越来越多地使用封闭的数据集构建大型模型,并仅通过API访问提供模型输出。
要使LLM成为一种开放和可访问的技术,获得最先进的模型是很重要的,这些模型是开放的、可复制的,而且对研究和商业应用都是免费的。为此,Cerebras使用最新的技术和开放数据集训练了一系列transformer模型,称之为Cerbras-GPT。这些模型是第一个使用Chinchilla公式训练并通过Apache 2.0许可证发布的GPT模型系列。
下图是Cerebras-GPT与其它模型的对比结果:
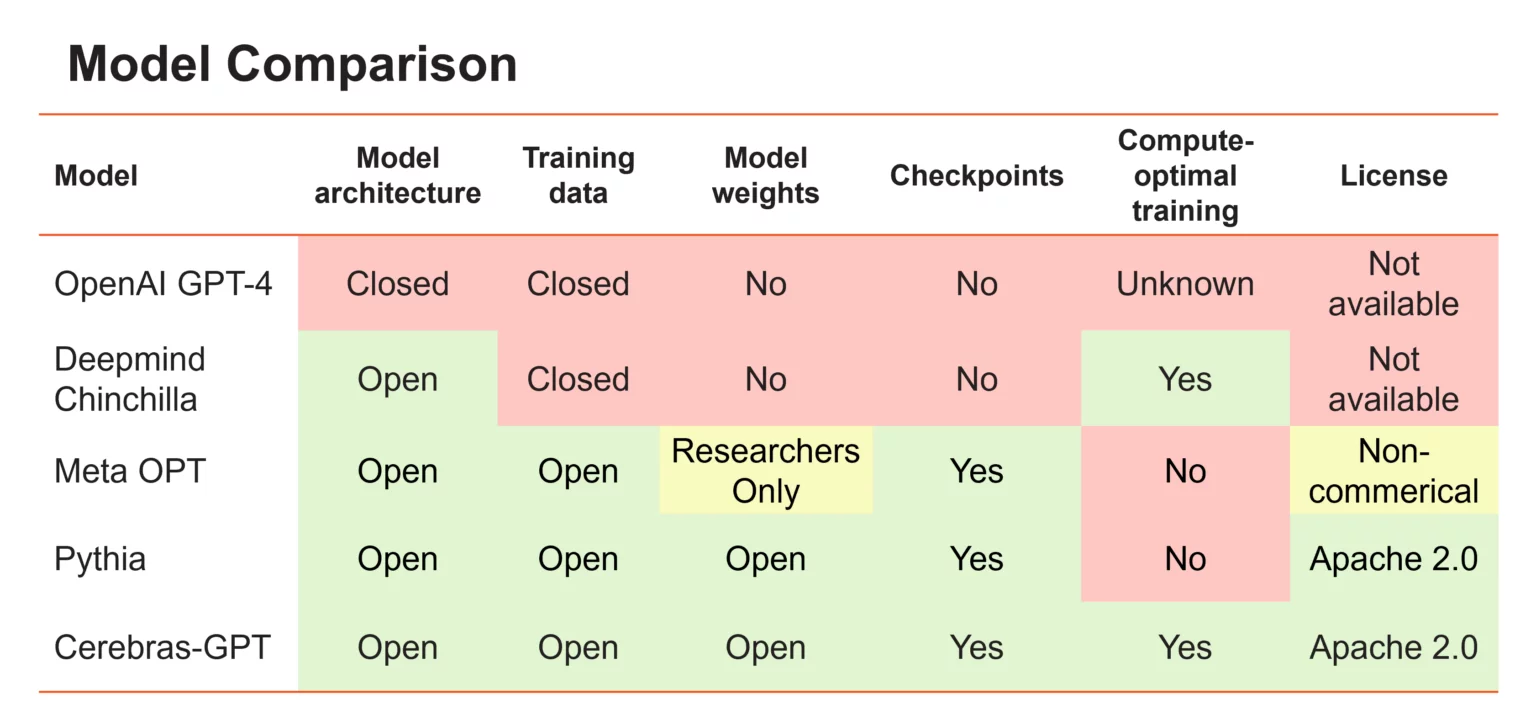
可以看到,与业界的模型相比,Cerebras-GPT几乎是各个方面完全公开,没有任何限制。不管是模型架构,还是预训练结果都是公开的。目前开源的模型结构和具体训练细节如下:
| Model | 参数(亿) | 层数 | 维度 | Heads | d_head | d_ffn | LR | BS (seq) | BS (tokens) |
|---|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT | 1.11 | 10 | 768 | 12 | 64 | 3072 | 6.0E-04 | 120 | 246K |
| Cerebras-GPT | 2.56 | 14 | 1088 | 17 | 64 | 4352 | 6.0E-04 | 264 | 541K |
| Cerebras-GPT | 5.90 | 18 | 1536 | 12 | 128 | 6144 | 2.0E-04 | 264 | 541K |
| Cerebras-GPT | 13 | 24 | 2048 | 16 | 128 | 8192 | 2.0E-04 | 528 | 1.08M |
| Cerebras-GPT | 27 | 32 | 2560 | 20 | 128 | 10240 | 2.0E-04 | 528 | 1.08M |
| Cerebras-GPT | 67 | 32 | 4096 | 32 | 128 | 16384 | 1.2E-04 | 1040 | 2.13M |
| Cerebras-GPT | 130 | 40 | 5120 | 40 | 128 | 20480 | 1.2E-04 | 720 → 1080 | 1.47M → 2.21M |
此外,他们还公布了Cerebras-GPT和其它模型的硬件资源消耗对比结果:
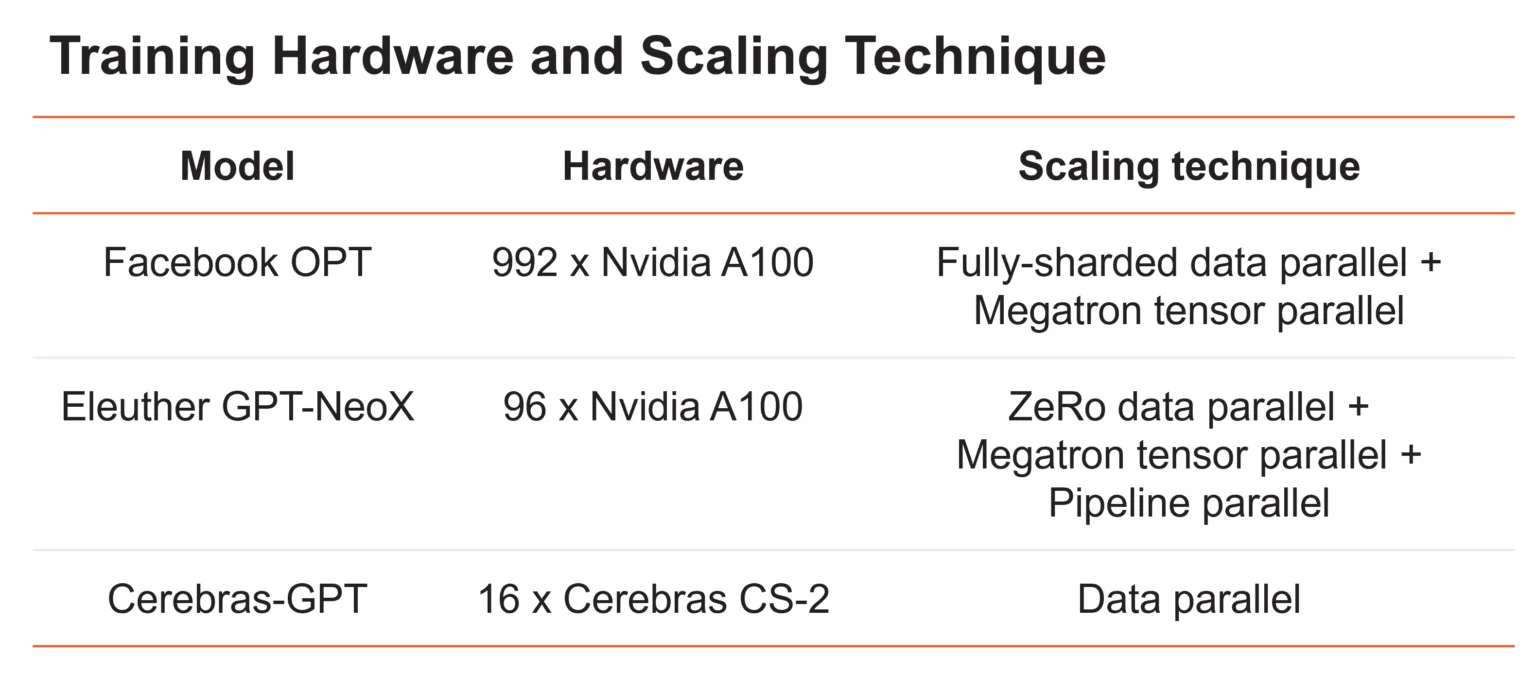
可以看到,Cerebras-GPT运行在他们公司专有硬件上,似乎消耗的算力很少!Meta的OPT模型,参数范围从125M到175B,在992个GPU上使用数据并行和张量并行的组合以及各种内存优化技术进行训练。Eleuther的20B参数的GPT-NeoX使用数据、张量和管道并行的组合来训练96个GPU上的模型。Cerebras GPT是在16个CS-2系统上使用标准数据并行进行训练的。因为Cerebras CS-2系统配备了足够的内存,即使是最大的模型也可以在单个设备上运行,而不需要拆分模型。然后,我们围绕CS-2设计了专门的Cerebras晶圆级集群,以实现轻松扩展。它采用了HW/SW共同设计的执行方式,称为权重流,能够独立扩展模型大小和集群大小,而不需要模型并行。
而Cerebras-GPT的使用非常简单,目前支持3种方式调用:
1、基于AutoModelForCausalLM函数
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("cerebras/Cerebras-GPT-13B")
model = AutoModelForCausalLM.from_pretrained("cerebras/Cerebras-GPT-13B")
text = "Generative AI is "
2、使用HuggingFace的Pipelines
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
generated_text = pipe(text, max_length=50, do_sample=False, no_repeat_ngram_size=2)[0]
print(generated_text['generated_text'])
3、使用model.generate()
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, num_beams=5,
max_new_tokens=50, early_stopping=True,
no_repeat_ngram_size=2)
text_output = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(text_output[0])
Cerebras-GPT完全开源,大家可以去官方的HuggingFace上下载代码与预训练结果: https://huggingface.co/cerebras/Cerebras-GPT-13B
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
