softmax作为输出层激活函数的反向传播推导
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的导数问题。
[toc]
一、一个简单的最后一层的例子
我们先看一个最后一层的例子,假设我们的标签有3类,那么最后一层一般定义成3个神经元,并先通过计算softmax得到最后一层激活函数的输出,然后将3个类别中概率最大的一类作为输出的预测结果。如下图所示:
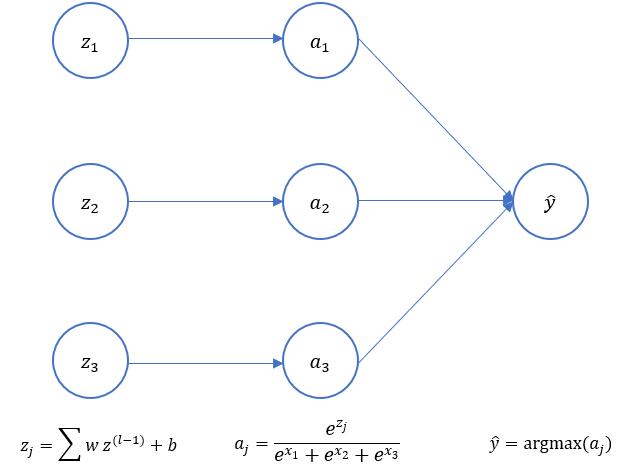
假设$z_1$、$z_2$和$z_3$是最后一层的非激活函数结果,它的值是通过前一层的输出来做线性变化得到,即$\sum wa^{l-1} +b$得到,这里的$a^{l-1}$是指前一层的激活函数的输出结果。那么这一层激活函数选择softmax之后得到的结果是:
a_j = \frac{e^{z_j}}{e^{z_1}+e^{z_2}+e^{z_3}}
假设预测的结果是$\hat{y}$,一般我们选择softmax最大的结果作为预测结果。这里提醒一下,我们一般输出的结果也是一个向量,也就是真实的标签中是一个one-hot编码,其中真实标签所在的维度为1,其他位置的结果为0。我们预测的也是这样一个向量,期望它和真实标签越接近越好。
二、交叉熵损失函数
在这里使用softmax作为激活函数的层通常都是最后一层,使用交叉熵作为损失函数(这里我们用$n_y$表示输出标签的数量,所以输出也就是一个$n_y$维度的向量):
J = - \sum_{j=1}^{n_y} y_{j} \log \hat{y}_{j}
三、交叉熵损失函数的偏导计算
接下来我们就要使用这个损失函数来进行反向传播的推导。那么,对于最后一层,我们的目标是求如下的偏导:
\frac{\partial J}{\partial z_i}
前面提到过,输出的是一个$n_y$维的向量,除了真实标签的位置是1,其它都是0。而我们预测的结果也是一个向量,由$\hat{y}=[a_1, a_2, a_3]$组成(注意,实际预测我们会取概率最大的作为预测结果,但实际我们计算的目标还是这个向量)。假设真实标签所在的维度就是$j$,那么求和的其他维度的结果都是0。
因此,损失函数可以简化掉求和结果变成:
J = - y_{j} \log a_{j}
那么:
\frac{\partial J}{\partial z_i} = \frac{\partial J}{\partial a_j} \cdot \frac{\partial a_j}{\partial z_i}
3.1、第一项的偏导
对于第1项的求偏导很简单:
\frac{\partial J}{\partial a_j} = - \frac{y_j}{a_j}
3.2、第二项的偏导
对于第二项,如前所述,它的公式为:
a_j = \frac{e^{z_i}}{\sum e^{z}}
对这个式子的求导其实是针对$z_1$、$z_2$和$z_3$求导,我们用$z_i$表示,要分成两种情况:当真实标签$j=i$的时候,分子$z_i=z_j$是未知数:
\begin{aligned}
\frac{\partial a_j}{\partial z_i} &= \frac{ (e^{z_i})'\sum e^{z} - e^{z_i}(\sum e^{z})' }{(\sum e^{z})^2} \\
& \\
&= \frac{(e^{z_i})'}{\sum e^{z}} - \frac{e^{z_i}}{\sum e^{z}} \cdot \frac{(e^{z})'}{\sum e^{z}}\\
& \\
&= \frac{e^{z_i}}{\sum e^{z}} - \frac{e^{z_i}}{\sum e^{z}} \cdot \frac{e^{z_j}}{\sum e^{z}}\\
& \\
&=a_i(1-a_j)
\end{aligned}
当$j\neq i$时候,分子$z_i$是常数,因此:
\begin{aligned}
\frac{\partial a_j}{\partial z_i} &= \frac{ (e^{z_i})'\sum e^{z} - e^{z_i}(\sum e^{z})' }{(\sum e^{z})^2} \\
& \\
&= \frac{ 0 \cdot \sum e^{z} - e^{z_i}\cdot e^{z_j}} {(\sum e^{z})^2} \\
&\\
&=- \frac{ e^{z_i}\cdot e^{z_j}} {(\sum e^{z})^2}\\
&\\
&=- \frac{e^{z_i}} {\sum e^{z}} \cdot \frac{e^{z_j}} {\sum e^{z}}\\
&\\
&=- a_i \cdot a_j
\end{aligned}
综上所述,对于$z_i$求偏导时候:
当$i$不是真实标签时候,即$i\neq j$:
\frac{\partial J}{\partial z_i} = - \frac{y_j}{a_j} \cdot (- a_i \cdot a_j) = a_i
当$i$是真实标签的时候,即$i=j$:
\begin{aligned}
\frac{\partial J}{\partial z_i} &= - \frac{y_j}{a_j} \cdot (a_i- a_i \cdot a_j) \\
&\\
&= - \frac{1}{a_j} \cdot (a_i- a_i \cdot a_j) \\
&\\
& = a_i - 1
\end{aligned}
四、更新参数
那么更新$z_i$也很简单,当$i\neq j$时候,更新只需要:
z_i = z_i - a_i
当$i= j$时候:
z_i = z_i -(a_i-1)
