pandas的get_dummies方法在机器学习中的应用及其陷阱
pandas.get_dummies是pandas中一种非常高效的方法。它最主要的作用是可以将分类变量转变成dummy变量,也就是虚拟变量。这篇博客将简要的介绍一下pandas.get_dummies()方法,并描述其在机器学习中的应用的一些注意事项。这篇博客我写了4000多字,本来我以为也很容易。但是写的过程就发现需要考虑的问题很多,看似简单的方法,其实实际应用有很多不一样的东西。我希望大家有时间可以看看,也希望能对文中我的疑问进行指导,那我觉得真的很值得了。如果大家本身对这个方法很熟悉,建议从第三节开始看,里面的实践我觉得可能与理论差别比较大。

一、概述
在做分类预测的问题的时候,对特征变量的处理是很重要的一个环节。像gender=["male", "female"]这种特征值是有限的离散值的变量一般称为分类变量,对分类变量的处理极其重要。尽管像LightGBM、XGBoost可以自动处理分类变量。但是很多时候我们也希望自己处理。大多数时候,分类变量都是由字符串表示的特征,很多算法都无法直接使用。处理方式一般有两种:一种是用数字为每一个特征值编码,例如前面说的male/female可以使用0和1表示。另一种是利用one hot encoding(独热编码)。也就是用一个长度为特征值数量的向量表示,每一位只有0和1两种取值。本文主要关注one hot encoding的处理。
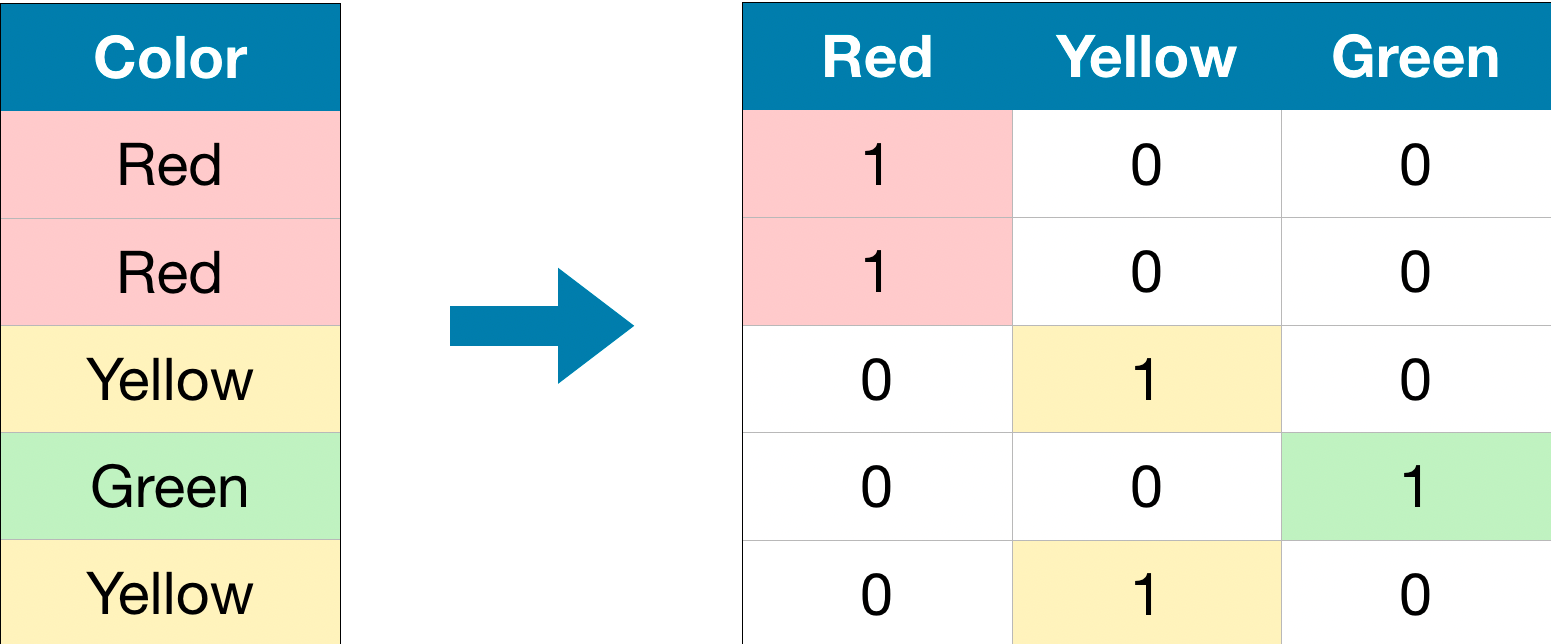
上图就是一个示例。本来我们有一个特征Color,取值有三种:Red,Yellow,Green。使用one hot encoding可以将这个特征拆分成三个特征,分别是Red,Yellow,Green。当某个样本的Color特征是一个具体的值的时候,在新的三个特征对应的列取值1,剩下的取值为0即可。
当类别变量下的不同特征值数量比较少的时候,采用one hot encoding是很有效的(特征值数量很多的处理一般不会采用这个方式,但不是本文讨论的重点,就不说了,有机会再聊)。在Python的数据处理和机器学习中,最常使用pandas.get_dummies和sklearn.preprocessing.OneHotEncoder来做分类变量的one hot encoding。本文将主要描述前者的使用方法及其注意事项。
二、pandas.get_dummies的使用简介
现在我们举一个,假设我们有如下三行数据:
id,gender,age
1000,male,23
1001,female,22
1002,male,69
那么,使用pandas对gender变量进行one hot encoding的处理方式如下:
import pandas as pd
df = pd.DataFrame(
[
[1000, "male", 23],
[1001, "female", 22],
[1002, "male", 69]
],
columns=['id', 'gender', 'age']
).set_index("id")
# step 1: using get_dummies to encode gender feature
dummy_df = pd.get_dummies(df[["gender"]])
# step 2: concat dummy_df with original df
df = pd.concat([df, dummy_df], axis=1)
# step 3: remove original feature
df.drop("gender", axis=1, inplace=True)
这里简单的解释一下这几个步骤。第一个步骤,就是对gender特征做one hot encoding,打印dummy_df的结果如下:
gender_female gender_male
id
1000 0 1
1001 1 0
1002 0 1
可以看到,原始的gender特征已经被拆分了。
第二个步骤是将dummy_df与原始的df进行关联得到新的数据。因为我们要使用这个新的特征,所以需要将这个结果与原数据关联。但是,注意这里关联之后的列是:
Index(['gender', 'age', 'gender_female', 'gender_male'], dtype='object')
可以看到,gender还在,但是其实我们不需要了。所以会有第三个步骤,把gender删除。当然,实际中我们会把步骤二和步骤三合在一起。这里为了说明就分开了。这里多说一句,pandas.get_dummies有一个参数是dummy_na。它是一个布尔型参数,如果你的特征值有NaN值,它可以决定是否需要这个玩意。当然,我个人认为NaN的处理应该在之前搞定,不要在这里用这么简单的方法,扩展性和可维护性都不太好。
但是,对于pandas.get_dummies的使用有几个陷阱需要注意。我们将在下面描述。
三、get_dummies的一个陷阱
准确来说,这不是pandas.get_dummies的问题,而是one hot encoding的问题。就是当我们使用回归这种方法的时候,一般来说希望自变量是相互独立的。如果特征变量之间有相关性,模型将很难说出某个变量对目标的影响有多大。在这种情况下,回归模型的系数将无法传达正确的信息。但是使用上面pandas.get_dummies来处理就会引入这个问题。我们可以看到,当gender特征变成gender_male和gender_female的时候,这两个特征之间其实是冗余的。因为我们如果gender_male=1,那么gender_female=0,反过来也一样。这个问题在数学中称为多重共线性 (Multicollinearity),在pandas处理的时候有人也叫它虚拟变量陷阱(Dummy Variable Trap)。
这个问题的一个解决方法是加入参数drop_first=True。这也是pandas.get_dummies的一个参数,它的作用是去除第一个虚拟变量,让转换后的虚拟变量个数从原来的k个变成k-1个。例如,前面的gender变成gender_male和gender_female,如果设置drop_first=True,那么会导致结果去除了gender_male,只剩下gender_female,这样剩下的变量就没有这个问题了。如下图所示:

对于2个变量以上的情况,依然一样:

因此,在应用pandas.get_dummies方法时候,千万要注意drop_first=True。
四、get_dummies的drop_first实践结果
第三个问题虽然从理论上看的确如此。不过实际中不完全一样。首先,像决策树这种模型可能会受益于多重共线性(可以参考:Is multicollinearity a problem in decision trees?)。因此,什么情况下要破坏掉这个特性需要根据模型来。
另外,我发现,实际中,这个变量的作用并没有那么简单。我使用kaggle的放假预测数据集做了如下测试:
# Feature:
# Created by DuFei at 19:17 2021/11/17
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
train_file = "F:/data/kaggle/house-prices-advanced-regression-techniques/train.csv"
numeric_features = ["MSSubClass", "LotFrontage", "YrSold", "MoSold", "MiscVal"]
# 这里的分类变量用到两个,一个是Neighborhood,另一种情形是MSZoning
category_features = ["Neighborhood"]
target_feature = ["SalePrice"]
all_features = numeric_features + category_features + target_feature
# read data
df = pd.read_csv(train_file, usecols=all_features).fillna(-1)
# transform data
dummies = pd.get_dummies(df[category_features])
train_df = pd.concat([df, dummies], axis=1).drop(category_features, axis=1)
y = np.log1p(train_df[target_feature].values)
# prepare data
X = train_df[train_df.columns[~train_df.columns.isin(target_feature)]].values
clf = LinearRegression()
scores = cross_val_score(clf, X, y, cv=5)
print(f"drop_first=False:{np.mean(scores)}")
dummies = pd.get_dummies(df[category_features], drop_first=True)
train_df = pd.concat([df, dummies], axis=1).drop(category_features, axis=1)
# prepare data
X = train_df[train_df.columns[~train_df.columns.isin(target_feature)]].values
scores = cross_val_score(clf, X, y, cv=5)
print(f"drop_first= True:{np.mean(scores)}")
这段代码使用原始数据集中的部分字段,一种字段是数值类的,一种是类别变量(分别是Neighborhood和MSZoning两种)。在测试的时候发现,drop_first=True并不会总是带来正向收益:两种变量的测试结果分别是:
# 使用MSZoning分类变量
drop_first=False:0.19066438516985346
drop_first=True:0.19066438516985357
# 使用Neighborhood分类变量
drop_first=False:0.5675644238257058
drop_first=True:0.5675644238257048
显然,drop_first=True的影响并不总是一致的。经过多次测试,有如下几个发现和结论:
- 在category变量个数比较少的时候,drop_first=True的影响很多时候不明显,差别微弱
- drop_first=True的影响对不同的category变量来说方向似乎不一样
- 当联合多个category变量一起使用drop_first=True时候,结果差异会放大,而且效果似乎更好
这里我无法找到一个合理的解释来证明这个现象。但可能的原因是变量之间的关系比较复杂,在使用drop_first=True的时候可能不仅会影响当前变量的多重共线性。那么结合前面的分析,在实际中我觉得最佳的实践是要关注drop_first这个参数带来的影响,而不能一味按照某些博客写的必须是True。
五、get_dummies在实践中的其它问题
最后一部分我们将描述一下get_dummies方法在实际应用中的其它需要考虑的问题。前面已经说到,对于分类变量中的NaN值需要考虑。实际中还有个问题类似,也需要考虑。通常,我们会将数据分成训练集和测试集。同时,线下训练与生成线上预测的时候数据集可能会有差异。
例如,将dataset分成train和test数据集的时候,有可能会出现test中有某些变量而train没有的情况。例如,刚好把上gender=unknown的情况放到了test中,那么train数据集转换后gender变成了2列,而test会变成3列。显然,这就有了很大的问题。在实践中,通常有如下几种解决方法:
1、将train和test放到一起先做get_dummies,然后再切分。这虽然可以避免一些问题。但是线上应用可能有问题,因为线上的数据集未必都是线下能遇到的。
2、test数据集做完get_dummies之后,获取test的列,然后统一二者,案例如下:
X_train_encoded = pd.get_dummies(X_train)
cols = X_train_encoded.columns.tolist()
X_test_encoded = pd.get_dummies(X_test)
X_test_encoded = X_test_encoded.reindex(columns=cols).fillna(0)
这个方法会在train中加入一列gender_unknown,它的值都是0。注意,如果是test中缺少train的列,那么代码需要反过来。
3、使用sklearn库的OneHotEncoder sklearn的OneHotEncoder有类似的效果,不过sklearn的思路更适合机器学习。它先使用OneHotEncoder来fit数据,之后获得的encoder可以使用相同的编码处理其它数据集,碰到没有的值可以自由处理。例子如下:
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False, handle_unknown='ignore')
ohe = ohe.fit(X_train)
train_enc = ohe.transform(X_train)
test_enc = ohe.transform(X_test)
显然,这种方法更加合理。
六、总结
虽然pandas.get_dummies很简单,对于它引起的多重共线性的理论似乎也很明确清晰。但是通过前面的分析和案例我们应该了解:再简单的理论在实践中可能都不一定是预期的结果。毕竟这些原理所需要的条件和现实可能不同。同时,在实践中,除了有简单的使用外,还需要面临很多复杂的工程问题。这些问题的处理不仅需要经验,也需要多学习。
