华盛顿大学提出QLoRA及开源预训练模型Guanaco:将650亿参数规模的大模型微调的显存需求从780G降低到48G!单张显卡可用!
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,而根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
基于QLoRA方法微调的Guanaco 65B模型据称效果超越目前所有的开源模型,并且比ChatGPT更加强大(基于人类评测结果和GPT-4的评测结果),打败了Google Bard,并接近GPT-4。Guanaco包含4个版本,从70亿参数到650亿参数,都将开源!由于Guanaco是基于MetaAI的LLaMA微调,因此,尽管它是开源的,但是它不可以商用!
这篇论文和这项工作里面包含了非常多的与大模型相关的数据和结论,建议大家原文仔细阅读。里面包含了不同模型的显存占用、目前一些大模型评测基准的偏差等。本文将主要描述其QLoRA的核心思想和重要结论。
QLoRA方法提出的背景
随着大型语言模型(LLMs)在各种任务中展现出令人瞩目的表现,如何有效地微调这些模型以优化其性能已经成为了研究的重点。
尽管大模型的能力很强,但是对于特定领域的数据集来说,微调依然是不可避免的工作。主要原因有2个:
- 一个是很多企业或者个人都有自己特定的数据与知识,这是开源大模型或者通用大模型难以了解的知识,zero-shot的能力很难扩展到这种特定的专有领域中。
- 其次,很多特定领域知识的提问和回答有特定的逻辑,类似于instruction-tuning是十分必要的。
然而,微调非常大的模型具有高昂的成本,650亿参数规模的语言模型,如LLaMA,其16位浮点精度的模型文件大小约200多G,载入到显存中使用就需要260多G,而对其微调则需要高达780G的显存。显然,这样的成本难以接受。
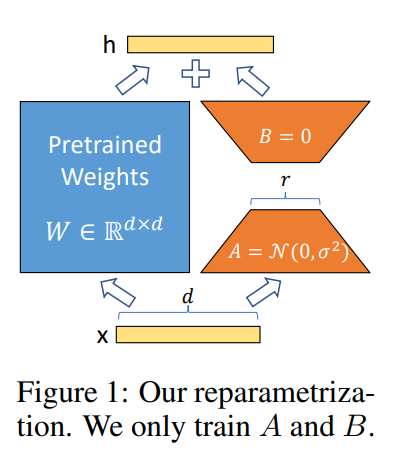
此前,对大模型进行压缩和微调已经有了很多成果。其中最著名的是微软在2021年提出的LoRA(Low-Rank Adaptation,低秩适应)方法(见上图)。这种方法的提出,是为了解决全模型微调的一些问题,全模型微调会重新训练所有模型参数,但随着我们预训练的模型越来越大,全模型微调变得越来越不可行。LoRA的工作原理是冻结预训练的模型权重,并在transformer架构的每一层注入可训练的秩分解矩阵,大大减少了下游任务的可训练参数的数量。相比使用Adam微调的GPT-3 175B,LoRA可以将可训练参数的数量减少10,000倍,GPU内存需求减少3倍。
但是,尽管如此,对于650亿参数规模的LLaMA模型来说,利用LoRA模型微调依然是成本很高。为此,华盛顿大学的NLP小组提出了QLoRA方法,即LoRA的量化版本。可以支持在单张消费级显卡上微调330亿参数的大模型,在单张专业级显卡上微调650亿参数规模大模型。
QLoRA方法简介、核心技术原理以及与LoRA等方法的区别
具体来说,QLoRA方法的实现主要用来3个方面的优化:
- ** 4位NormalFloat**:这是一种理论上最优的量化数据类型,用于处理正态分布的数据,其表现优于4位整数和4位浮点数。
- Double Quantization:这种方法可以通过对量化常数进行量化来减少平均内存占用,平均每个参数可以节省约0.37个bits(对于一个650亿参数的模型来说大约节省3GB)。
- Paged Optimizers:使用NVIDIA统一内存来避免在处理小批量的长序列时出现的梯度检查点内存峰值。
论文中也给出了QLoRA方法与全量微调和LoRA方法差异的示意图,简单明了:
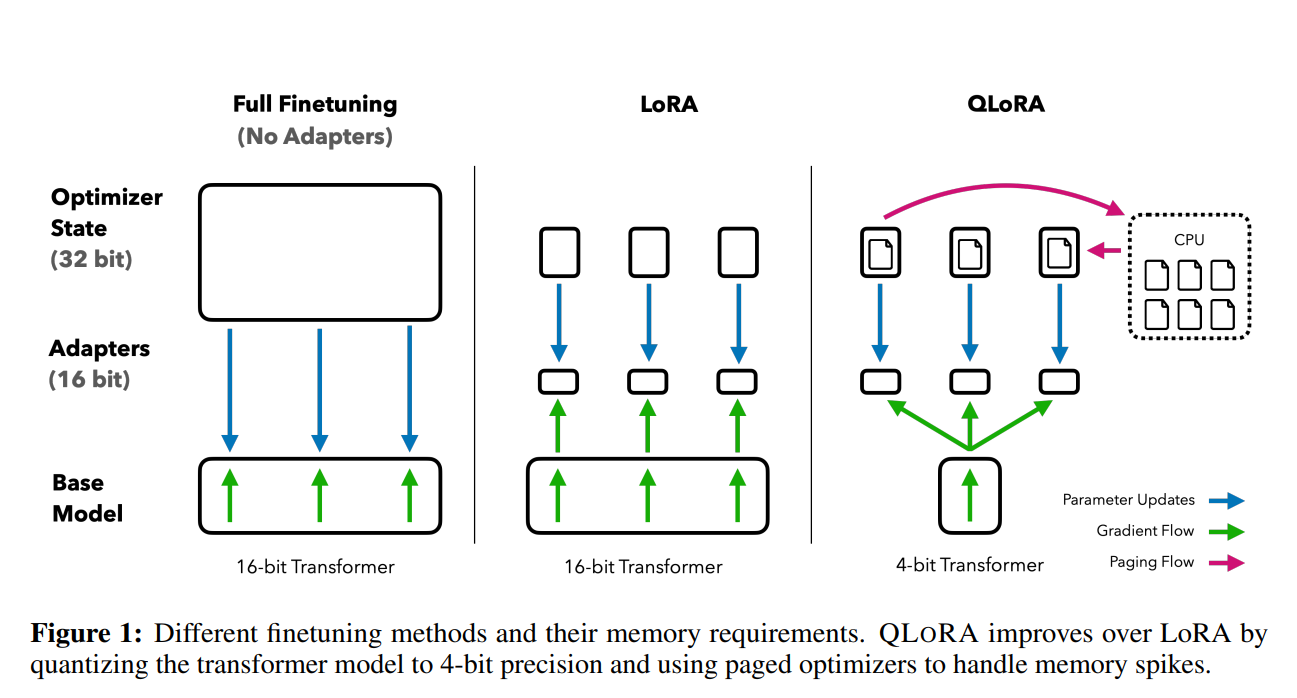
简单来说,相比较原始的LoRA,QLoRA将16-bit的transformer模型变成了4-bit的transformer模型(不过这里说的是4bit的NormalFloat,不是传统的4-bit),此外利用的NVIDIA的显存页优化器进行了优化,避免微调过程中出现显存的spikes。
其实,对于LoRA方法本身来说,它的内存占用非常小。因此,可以考虑使用多个Adapter来提高性能。换句话说,大模型微调的过程中,对显存的消耗主要是激活梯度,而不是其它的部分,其中,LoRA的Adapter参数规模只有模型权重的千分之二左右。那么,即使我们增加Adapter其实也不会提高显存的消耗。因此,将模型权重进行高强度的量化降低显存,再使用多个Adapter来减少模型量化带来的性能损失,就可以达到降低显存要求的同时保留原始模型的性能这2个目标的均衡了。
QLoRA方法的实际测试结果比较
UWNLP的研究人员用QLoRA方法训练了1000多个模型来测试这种方法的性能。模型参数从8000万到650亿之间多个,并在不同的质量数据集上做了微调。同时,他们还基于这种方法训练了一个chat的模型Guanaco。这里我们总结一下Guanaco相关模型的参数和测试结果。
基于QLoRA方法微调的Guanaco模型的显存占用
前面分析了,QLoRA方法的一个重要思想是对模型权重做量化,使用多个Adapter减少性能损失。因此,基于QLoRA方法微调的模型显存占用方面很有优势。根据论文的数据,有如下模型微调的显存要求:
上表将基于QLoRA方法微调的Guanaco模型与Vicuna模型(https://www.datalearner.com/ai-models/pretrained-models/Vicuna-13B )做了对比,Vicuna-13B是一个130亿规模的聊天机器人模型,基于MetaAI的LLaMA模型微调得到,也是目前开源领域最强大的大语言模型。但是,可以看到130亿参数规模的Vicuna模型的微调显存要求比330亿参数规模的Guanaco要求还高。而70亿参数规模的Guanaco只需要5GB显存即可微调,这极大地降低了成本!但是实际上让人惊喜的是,同等参数规模的Guanaco的性能比Vicuna模型还好!
基于QLoRA方法微调的Guanaco模型的性能
微调模型的显存降低固然很重要。但是,核心的问题还是看性能下降多少。根据论文提供的数据,基于QLoRA方法微调的Guanaco模型性能与原始模型相比几乎没有下降!
下表是基于人类评价基准获得的不同模型的性能:
可以看到,Guanaco 65B参数的模型表现已经与GPT-4差不多,比ChatGPT、Bard好很多。
当然,论文中也比较了在MMLU任务上的性能等。我们就不详细列举了。
QLoRA方法的总结
在这篇论文中的大量实验中,UWNLP的研究人员也有几个比较有意思的发现和结论,包括:
- 数据质量比数据规模更加重要:如9000条的OASST1样本数据比45万的FALN v2的数据集更好
- 多任务的语言理解评测(MMLU)与Vicuna的人类评估结果并不一致,并不能代表人类的态度
- GPT-4评估是一种廉价而合理的替代人类评估的方法
- FLAN v2对于指令微调来说很好,但是不适合chatbots
这里说一下第二条。MMLU是一种用于评估语言理解模型的方法。传统的语言理解模型评估通常使用自动评估指标,如准确率(accuracy)或BLEU分数。然而,这些指标无法准确衡量模型对于真实语言理解任务的表现。MMLU评测的目标是提供更有意义的度量,以更好地评估语言理解模型。它在业界使用很广泛。而Vicuna的人类评估则是让大家在一个系统中提问,然后给出匿名的2个模型的结果,然后提问者给出谁更好之后它再公布模型结果。基于这种方式来收集大家的评估。
QLoRA方法的提出对于大模型的压缩的应用来说十分有价值。我们可以持续关注它的演进。目前,官方已经承诺基于QLoRA模型微调的Guanaco将会开源(Guanaco在DataLearner上的模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/Guanaco )。而根据论文的解释,Guanaaco 65B的规模已经接近ChatGPT,超过Bard,那么可以期待一下。而且它的显存需求可能明显小于当前所有的模型。
总结一下QLoRA方法以及基于QLoRA方法发布的Guanaco模型:
- 基于QLoRA对大模型微调可以极大提升速度降低显存要求(33B/65B模型分别只需要24GB和48GB显存,微调训练时间分别是12个小时和24个小时)
- 基于QLoRA压缩的模型表现在所有场景下都能浮现16位浮点数模型的性能
- 基于QLoRA方法微调的Guanaco 65B的性能几乎打败了目前所有的开源模型
- 仅需12个小时在一张消费级显卡的微调,即可达到ChatGPT的97%的水准(这里应该是指Guanaco 33B模型)
- 在Vicuna的人类评估中,Guanaco 65B的结果超过ChatGPT!用GPT-4评估也是这个结论!
此外,UWNLP还认为目前的Vicuna评测基准规模太小,他们还提出了一个10倍规模的评测Open Assistant Data。
官方还提供了一个Google Colab,里面会根据提问由GPT-4和Guanaco 65B来生成答案,你可以自己比较结果,勾选较好的,然后它公布哪个答案由GPT-4生成,哪个是Guanaco 65B生成,亲自比较:https://colab.research.google.com/drive/1kK6xasHiav9nhiRUJjPMZb4fAED4qRHb?usp=sharing
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
