预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning和prompt-tuning
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型(BERT在DataLearner官方模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/BERT )的时候,大家还没有意识到本轮AI浪潮会发展到如此火热的地步。但是,BERT出现之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
当然,这三种技术并不是有完全隔离的界线,目前很多研究也并没有明显区分,本文的内容结合部分研究提供一种视角。欢迎理性讨论~
一、fine-tuning技术
Fine-tuning是一种在自然语言处理(NLP)中使用的技术,用于将预训练的语言模型适应于特定任务或领域。Fine-tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
Fine-tuning的概念已经存在很多年,并在各种背景下被使用。Fine-tuning在NLP中最早的已知应用是在神经机器翻译(NMT)的背景下,其中研究人员使用预训练的神经网络来初始化一个更小的网络的权重,然后对其进行了特定的翻译任务的微调。
经典的fine-tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的fine-tuning。如果两者不相似,则可能需要更多的fine-tuning。
在NLP中,fine-tuning最著名的例子之一是由OpenAI开发的OpenAI GPT(生成式预训练变压器)模型。GPT模型在大量文本上进行了预训练,然后在各种任务上进行了微调,例如语言建模,问答和摘要。经过微调的模型在这些任务上取得了最先进的性能。
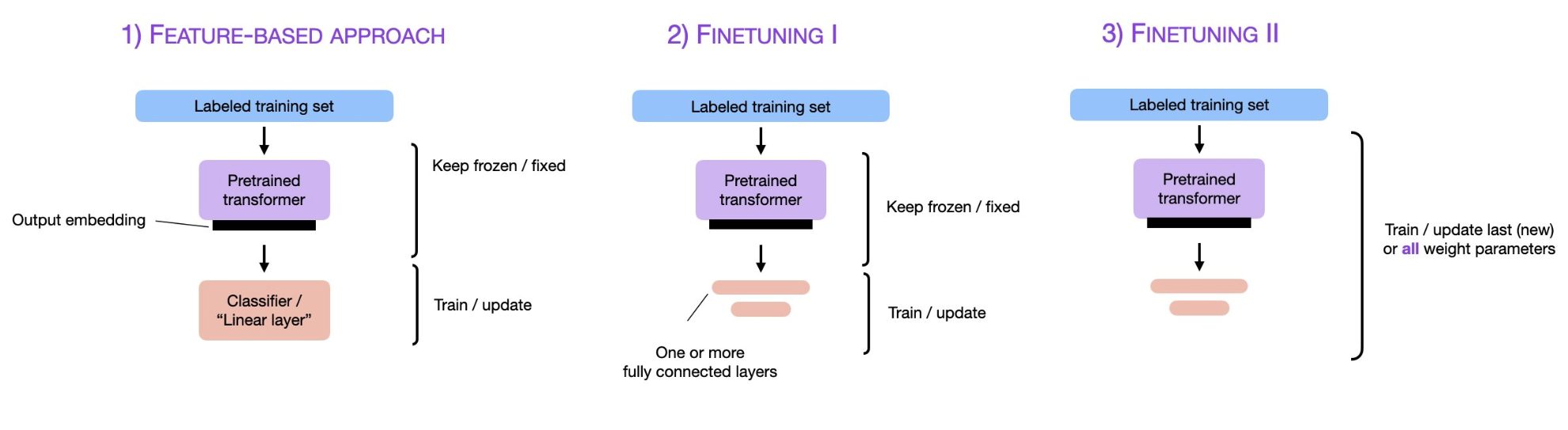
下图来自威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka的总结。

这是近几年很流行的大模型使用方法。即将除了输出层以外的所有权重“冻结”(freeze)。然后随机初始化输出层参数,再以迁移学习的方式训练。仅仅更新全连接输出层,其它层的权重不变。
二、parameter-efficient fine-tuning技术
参数高效的fine-tuning,简称PEFT,旨在在尽可能减少所需的参数和计算资源的情况下,实现对预训练语言模型的有效微调。它是自然语言处理(NLP)中一组用于将预训练语言模型适应特定任务的方法,其所需参数和计算资源比传统的fine-tuning方法更少。
换个角度说,parameter-efficient fine-tuning技术在通过仅训练一小组参数来解决传统微调技术需要大量资源的问题,这些参数可能是现有模型参数的子集或新添加的一组参数。这些方法在参数效率、内存效率、训练速度、模型的最终质量和附加推理成本(如果有的话)方面存在差异。
这些技术对于研究人员和开发人员非常重要,因为他们可能无法使用强大的硬件或需要在低资源设备上进行模型微调。
其中一种参数高效的fine-tuning技术称为蒸馏(distillation),它由Hinton等人于2015年引入。该方法涉及训练一个较小的模型来模仿一个较大的预训练模型的行为。预训练模型生成“教师”预测结果,然后用于训练较小的“学生”模型。通过这样做,学生模型可以从较大模型的知识中学习,而无需存储所有参数。
另一种技术称为适配器训练(adapter training),它由Houlsby等人于2019年引入。适配器是添加到预训练模型中的小型神经网络,用于特定任务的微调。这些适配器只占原始模型大小的一小部分,这使得训练更快,内存需求更低。适配器可以针对多种任务进行训练,然后插入到预训练模型中以执行新任务。
第三种技术称为渐进收缩(progressive shrinking),它由Kaplan等人于2020年引入。这种技术涉及在fine-tuning期间逐渐减小预训练模型的大小。从一个大模型开始,逐渐减少参数的数量,直到达到所需的性能。这种方法可以产生比从头开始训练的模型性能更好的小型模型。
UMass Lowell大学的教授在3月份发布了一篇parameter-efficient fine-tuning的综述,大家可以去学习一下:Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
三、prompt-tuning技术
prompt-tuning是一种更近期的精调预训练语言模型的方法,重点是调整输入提示(input prompt)而非修改模型参数。这意味着预训练模型保持不变,只有输入提示被修改以适应下游的任务。通过设计和优化一组提示,可以使预训练模型执行特定任务。
prompt-tuning和传统的fine-tuning的主要区别在于预训练模型被修改的程度。fine-tuning修改模型的权重,而提示调整只修改模型的输入。因此,prompt-tuning调整比精调的计算成本低,需要的资源和训练时间也更少。此外,prompt-tuning比精调更灵活,因为它允许创建特定任务的提示,可以适应各种任务。
对于像GPT-3这样的大规模模型,整体精调可能需要大量计算资源。
一些值得注意的prompt-tuning技术包括:
Prefix tuning(前缀调整):由Li和Liang在论文“Prefix-Tuning: Optimizing Continuous Prompts for Generation”(2021)中提出。前缀调整涉及学习特定任务的连续提示,在推理过程中将其添加到输入之前。通过优化这个连续提示,模型可以适应特定任务而不修改底层模型参数,这节省了计算资源并实现了高效的精调。
下图是论文中给出的fine-tuning与Prefix tuning的差异示意图:
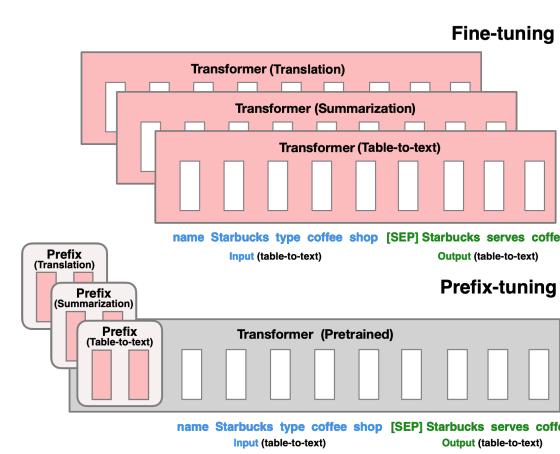
P-Tuning:由Liu等人在论文“P-Tuning: GPT Understands, Learns, and Generates Any Language”(2021)中提出。P-Tuning涉及训练可学习的称为“提示记号”的参数,这些参数与输入序列连接。这些提示记号是特定于任务的,在精调过程中进行优化,使得模型可以在保持原始模型参数不变的情况下在新任务上表现良好。
经典的prompt-tuning方式不涉及对底层模型的任何参数更新。相反,它侧重于精心制作可以指导预训练模型生成所需输出的输入提示或模板。这通常是一个手动的试错过程,从中选择最适合特定任务的提示。然而,随着前缀调整和P-Tuning等提示调整技术的出现,它们提供了更系统化和高效的方式来适应输入提示,从而提高大型预训练模型在特定任务上的性能。
四、总结
其实,从上述的总结中大家可以看到,微调技术的发展似乎与模型的发展规模息息相关。最早出现fine-tuning也是模型变大之后,使用原有模型的架构在新数据上训练成本过高且丢失了原有模型的能力,后来也是因为模型发展的规模增长远远超过硬件性能的发展,导致更加高效的微调技术出现。而当前最火热的prompt-tuning其实也就是几乎根本无法微调大模型而产生的一种替代方式。当然,模型本身能力的强大也使得该方法变得有效。其实,从这个思路下去,大家也可以看到,当大模型开始涉及更加复杂和现实的问题时候,如果可以出现自动prompt-tuning技术而非手工调整可能是未来很重要的方向。毕竟在文本摘要、代码debug等需要大量的输入来让模型认识问题的场景,如何有效的将过长的输入prompt给模型是一个很重要的问题,现在的大模型在长输入方面成本推理成本很高也有很大限制,因此这种技术也是未来很重要的一个方向!
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
