Grok-4未发布评测结果已泄露:2个版本,支持长推理输出,但是最高上下文仅132K,泄露的评测数据显示Grok4是迄今为止得分最高的大模型,甚至大幅超越Gemini 2.5 Pro!
Grok4是马斯克旗下大模型初创企业xAI的第四代大模型,在五月份的时候,马斯克就透露他们马上要发布Grok 3.5模型,六月份的时候说这个模型效果很好,版本号就直接改为4,这中间经过多次波折,最终马斯克说Grok 4将在7月4日之后发布。截止目前,虽然xAI官方没有正式宣布Grok 4,但是目前Grok 4已经透露了很多的消息。本文将对这些信息做总结和分析。

Grok 4分为2个版本,分别是常规的通用大模型和编程大模型
首先确认的是,Grok4至少包含2个版本,分别是通用大模型Grok 4和针对编程优化的Grok 4 Code。
不过最新的截图也显示,Grok4模型最高仅支持132K上下文长度,这个相比较对手的100万、200K来说都是有点低的。而Grok 3对外宣传100万上下文长度,很多人测试也表示长了之后Grok 3的效果也会下降。也许本次只是回归真正的能力。
目前官方后台的数据显示这两个模型的版本是0629版本,即grok-4-0629和grok-4-code-0629。
此外,官方的接口显示,这两个模型支持Test Time Compute,也就是在推理过程增加推理时间(或者说增加推理过程的思维链tokens的数量)来获得更好的效果。
Grok的这个模式称为TTC(Test Time Compute),而OpenAI官方则使用 low、medium和high来表示。Google的官方使用但是deeper thinking模式,叫法不同,但是都是一个意思。
Grok-4的评测超过Gemini 2.5 Pro,全球第一
尽管xAI还没有正式发布Grok4,但是大家已经从接口中发现了Grok 4模型的评测数据了。透露评测数据看,Grok 4模型在各个方面都超越了当前模型的效果。甚至在很高难度的HLE评测上,大幅领先市面上的模型,是第二名得分的2倍以上!
如下图所示,是Grok 4和其它模型的对比结果(感兴趣的童鞋可以去下面链接有更详细的表格数据对比):
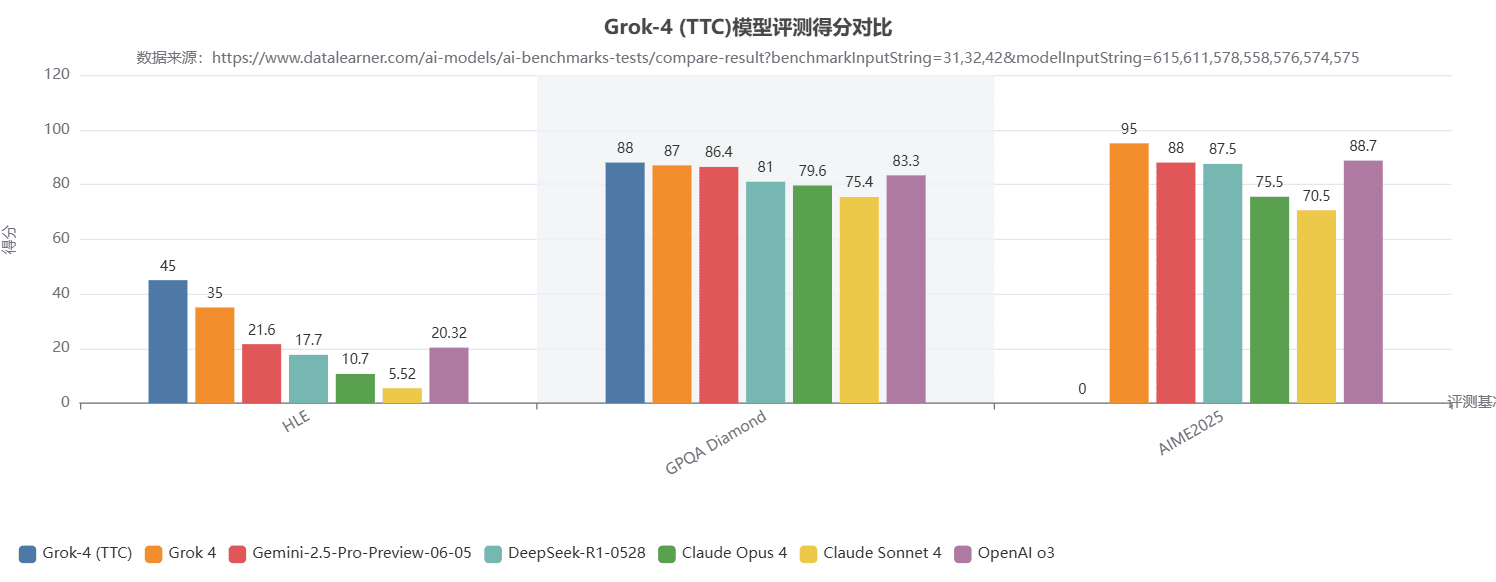
这三个评测都是难度非常高的评测结果,其中HLE是2-3000个非常难的跨学科问题,GPQA Diamond则是高难度的涵盖生物、物理、化学三个 STEM 领域的多选题,而AIME 2025是一项难度仅次于美国数学奥林匹克(USAMO)的高中数学竞赛,强调技巧与多步推理。
从这个结果,我们可以看出Grok4模型的强大:
- 在高难度知识领域的绝对领先优势: HLE(知识问答)并非普通问答,而是一个由专家筛选、难度极高的评测集。从所有模型的得分普遍偏低可以看出这一点。在此背景下,Grok-4 (TTC)的45.00分和Grok 4的35.00分不仅不是弱项,反而是绝对的强项。Grok-4 (TTC)的分数是第三名(Gemini-2.5-Pro)的两倍多,而Grok 4也大幅领先。
- 无可匹敌的数学推理能力:在AIME2025(数学推理)这项评测中,Grok 4的95.00分是其最耀眼的表现,可谓一骑绝尘。这个分数不仅远超所有其他顶级模型,也是目前唯一超过90分的模型。
这里,我们提供一个HLE的排行榜截图,大家可以更加清晰感受到Grok 4的强大!
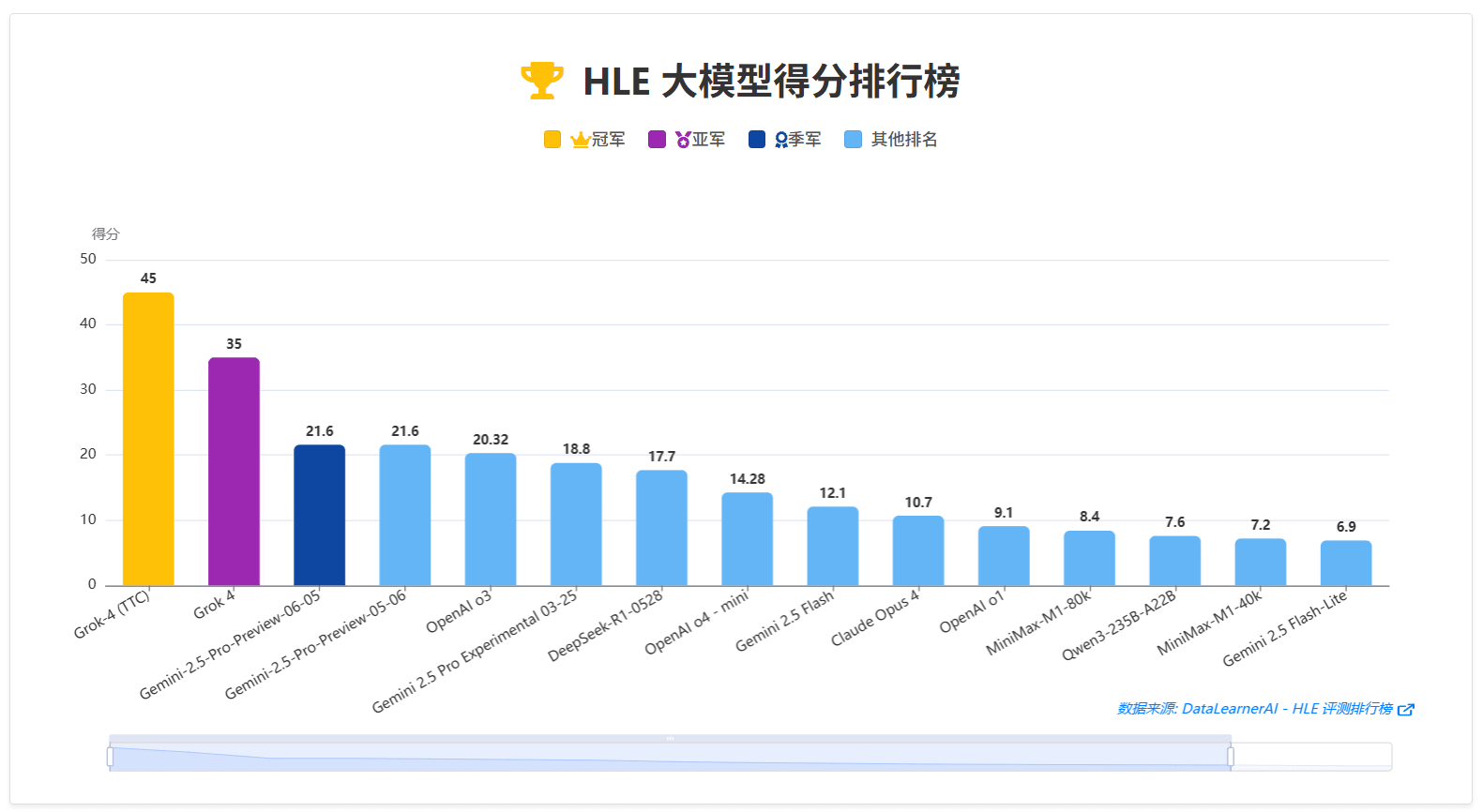
此前,在这些评测霸榜的是Gemini 2.5 Pro模型,当前看,也是敌不过Grok 4的。如果加上更多的推理(TTC)能力,Grok 4的表现更加惊人!
Grok 4 Code模型的表现也十分优秀
Grok 4还有一个针对编程领域优化的大模型Grok 4 Code,这个模型的也支持长推理模式(TTC),不过,当前官网泄露的数据仅仅包含SWE Bench Verified结果。
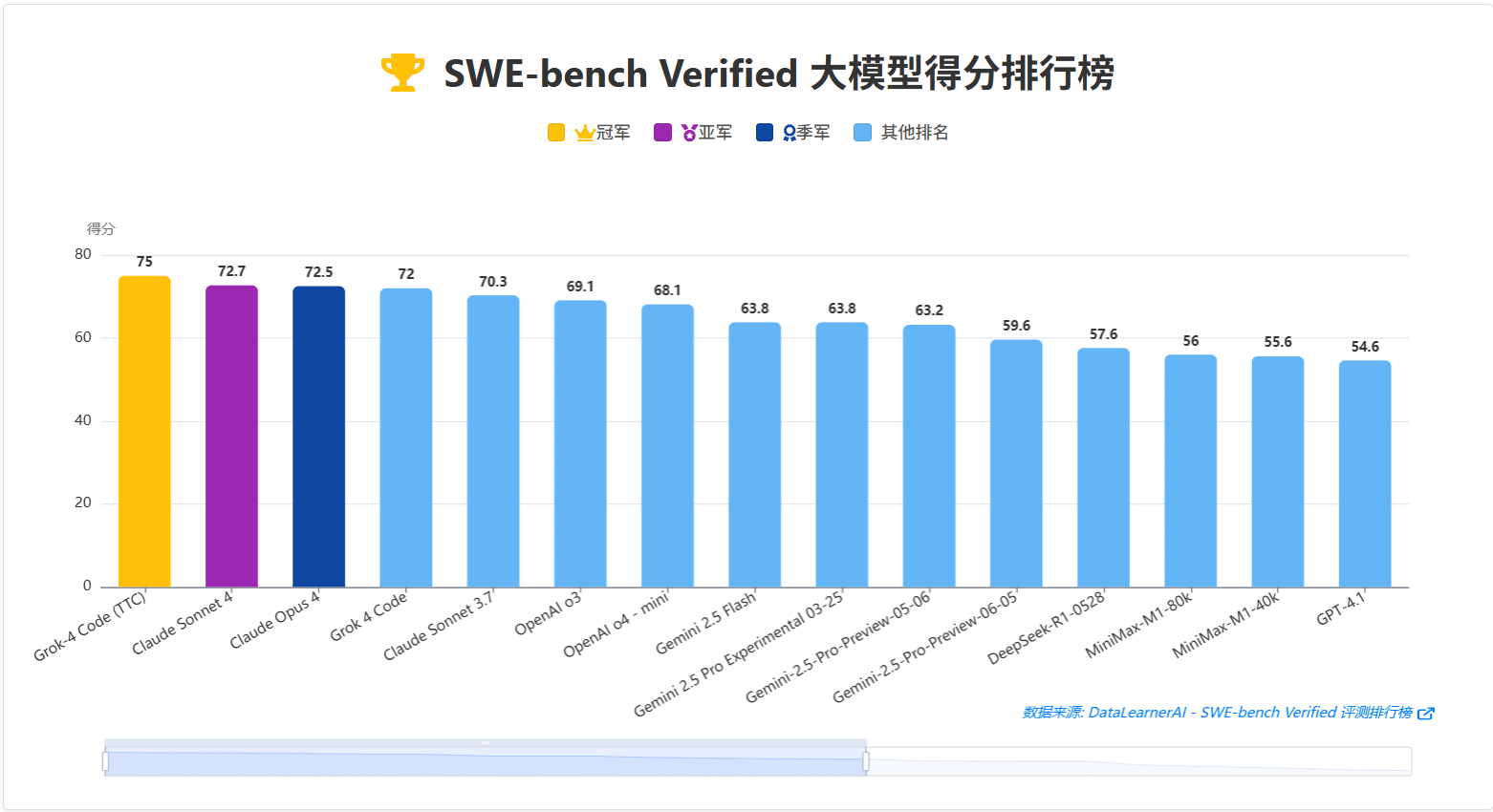
从这个图看,Grok 4 Code在SWE Bench Verified得分72,和Gemini 2.5 Pro差不多。如果加上TTC之后,得分达到75,第一名。
围绕Grok4发展的新的应用:Games和云端IDE
从xAI的截图显示,xAI随着Grok 4发布的还有一些新的应用,目前看到的包括2个,一个是Game,一个是云端存储。


从这些截图看,Grok4强大的能力也促使xAI开始提供更加复杂的应用服务,如开发游戏、个人数据的问答等。
期待Grok 4的发布,大家也可以关注DataLearnerAI的Grok4模型信息卡来获取最新的信息和评测结果。
Grok 4模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/grok-4 Grok 4 Code模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/grok-4-code
