SlimPajama:CerebrasAI开源最新可商用的高质量大语言模型训练数据集,含6270亿个tokens!
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。
除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。
Cerebras为什么要发布SlimPajama数据集
SlimPajama数据集来自RedPajama的清洗和去重结果。
MetaAI发布的LLaMA模型中详细描述了他们是如何收集数据集的。而LLaMA的效果也证明了在高质量数据集上训练的重要性。尽管LLaMA开源了他们的预训练结果(不可商用),也在论文中详细描述了LLaMA如何训练。但是,LLaMA的训练数据集却从未公开。为此,TOGETHER联合多家公司发起了RedPajama项目。
RedPajama是一个开源大模型项目,由TOGETHER联合多家公司发起。目前包括一个开源的数据集,有1.2万亿tokens,严格按照LLaMA模型论文中的方法收集。
尽管RedPajama声称严格按照LLaMA论文描述来收集数据。但是Cerebras发现该数据集有2个问题,一个是有些语料中缺少了数据文件,另一个问题是里面包含了大量的重复数据。RedPajama采用的是LLaMA的不严格数据去重策略,不同语料之间也没有考虑去重。
重复的数据集对于大模型来说有很多不利的影响,包括重复训练的浪费、过拟合等。
为此,Cerebras决定亲自上场,基于RedPajama做进一步数据的处理,以提高数据集的质量。最终他们发布了SlimPajama数据集。
SlimPajama数据集简介
TOGETHER发布的RedPajama数据集包含1.21万亿的tokens。通过过滤重复数据和低质量数据集之后,SlimPajama去除了原始RedPajama的49.6的字节数,将1.21万亿的tokens降低到6270亿的tokens。
SlimPajama数据产生的过程如下,首先从RedPajama中去除短的、低质量的文档。在去除标点符号、空白符号、换行符和制表符之后,将短于200个字符的文档去除。这些文档大多数只包含meta数据,没有啥有用的信息。这个策略被用于所有语料,但不包含Books和GitHub数据集。因为他们发现这两个数据集中的短文本也有很大的价值。这样就去除了RedPajama的1.86%的文档,去除的主要部分包括:
经过上述步骤之后,Cerebras使用MinHashLSH去重工具进行了去重,这是Cerebras基于2014年Leskovec等人的论文实现的去重工具,本次也开源了。最后,计算的各个数据集的重复率如下:
最终得到了SlimPajama数据集。这是一个高质量广泛去重的数据集。基于这个数据集训练大模型,官方认为将会提高训练效率,甚至获得比原始模型更好的效果。
SlimPajama数据集完整的处理流程如下图所示:
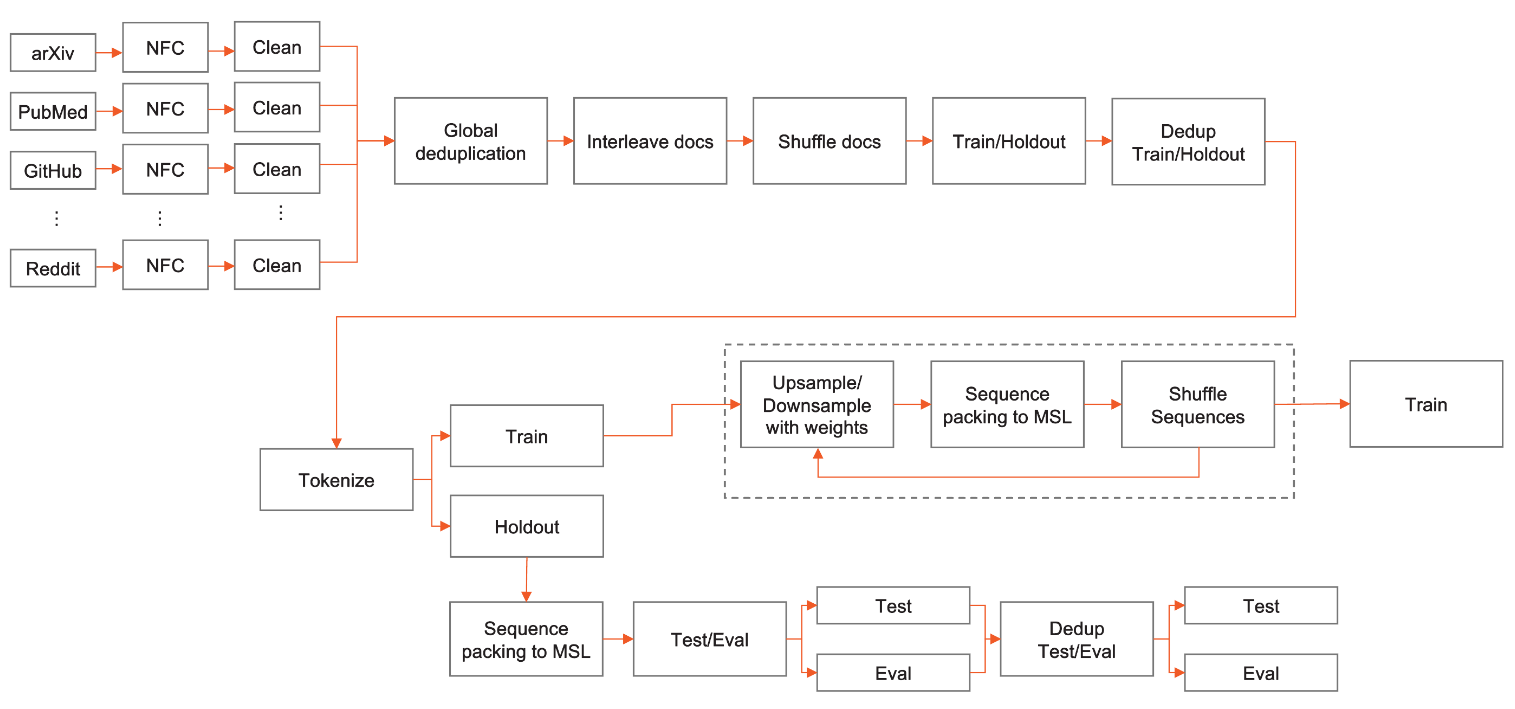
SlimPajama数据集与其它数据集的对比
当前大语言模型都是在大规模数据集上训练的。而这些数据集通常来自于互联网上开放的数据集,包括维基百科、GitHub等。大多数大规模数据集来源都差不多,但是比例和处理方法不一样。
SlimPajama数据集成分和其它数据集对比如下:
可以看到,与RedPajama、LLaMA、RefinedWeb数据集相比,SlimPajama数据集不那么集中,且网络数据占比更低。Books、arXiv、Wikipedia数据集占比更高,这三类都是质量较高的数据集。
此外,SlimPajama还是基于Apache 2.0开源的数据集,这意味着更开放,对商用更加友好。与其它数据集相比如下:
显然,从规模、质量和开源协议友好程度来说,SlimPajama都是最均衡最好的一个数据集。
注意,SlimPajama数据集以英文为主,也包含了一些非英文的语料。具体比例多少,官方没有公布。
SlimPajama相关资源以及下载链接
SlimPajama数据集压缩之后大小895GB左右,包含59166个jsonl文件。
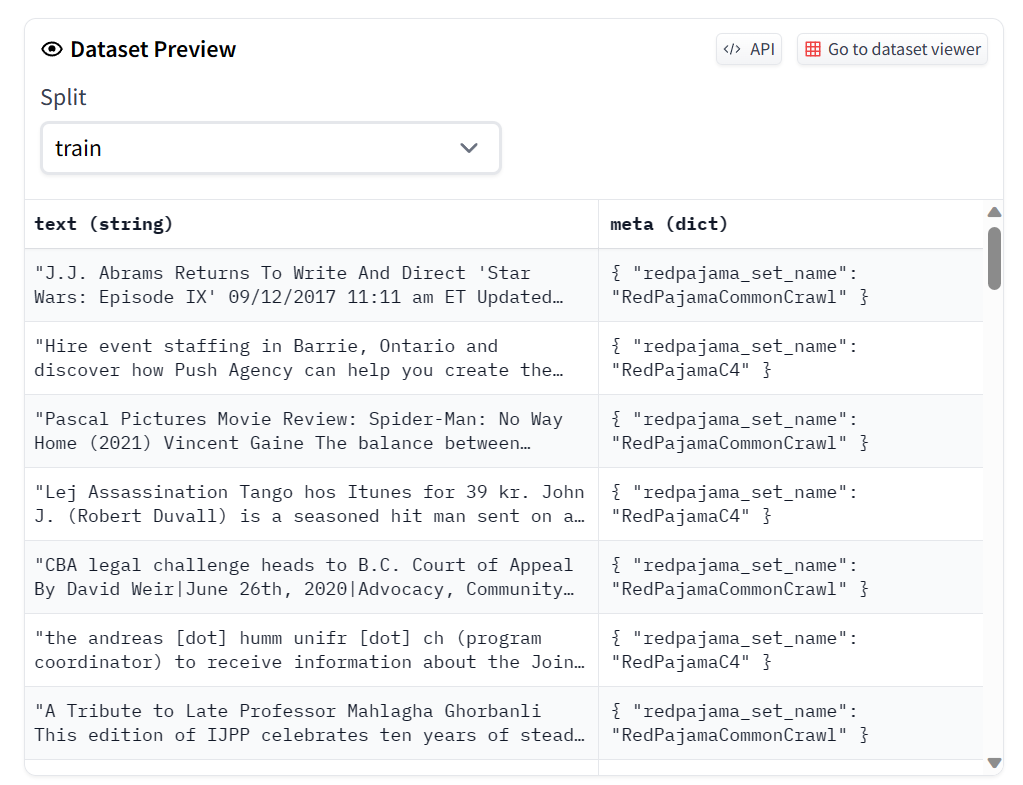
样例如下:
SlimPajama的数据集下载地址:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/train SlimPajama测试数据集地址:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/test SlimPajama验证数据集地址:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/validation SlimPajam数据集处理工具:https://github.com/Cerebras/modelzoo/tree/main/modelzoo/transformers/data_processing/slimpajama SlimPajama的DataLearner信息卡:https://www.datalearner.com/ai-dataset/SlimPajama
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
