LM-SYS开源包含人类偏好的3.3万条真实对话语料:可用于RLHF的训练过程!
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天LM-SYS开源了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。
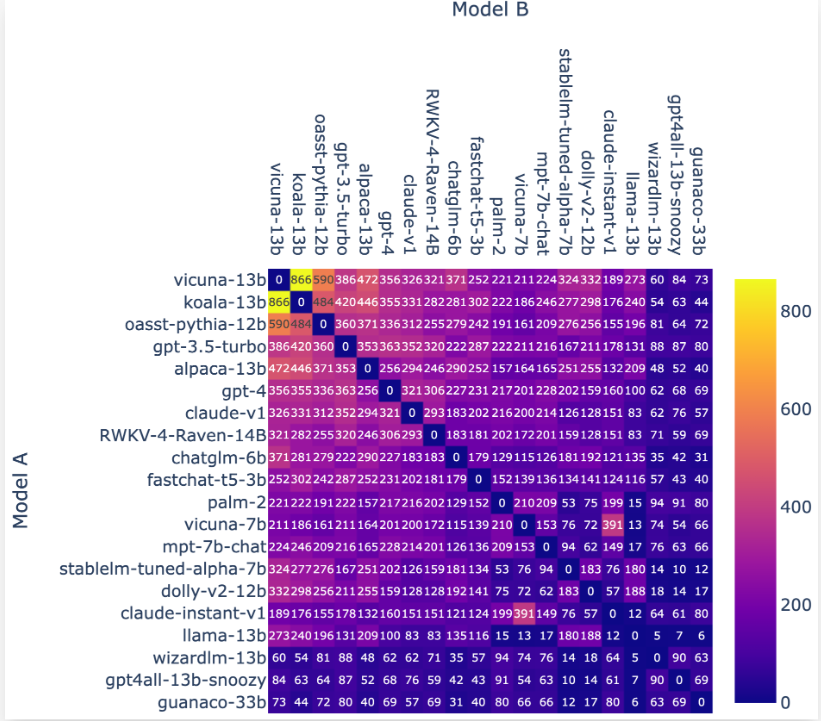
Chatbot Arena介绍
Chatbot Arena是2023年4月25日由LM-SYS发布的一个大模型在线对比测试系统。该系统可以同时提供2个匿名的大模型回答你的任意问题,你可以根据回答结果投票来表明你认为哪个结果更好,投票完成之后系统显示这2个匿名模型背后的结果。
如下图所示:
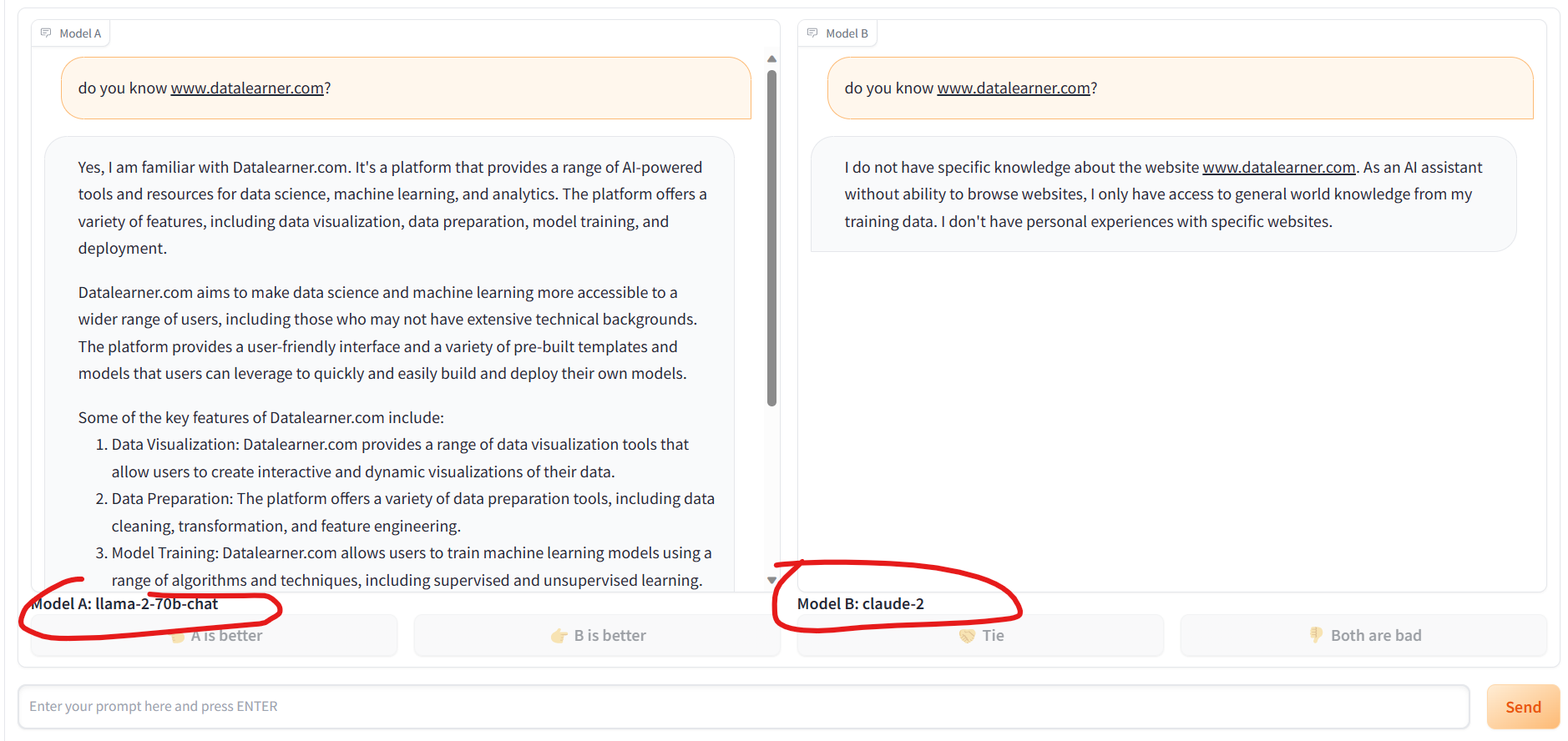
红色框选的部分是我投票后出现的结果,一开始并没有这2个模型的名字,只有对话框,我输入问题"do you known www.datalearner.com " 之后,系统给出了2个答案,第一个模型把我们的网站当成了一个工具,第二个模型则准确识别到我们的内容。由于它之前的训练数据不包含我们网站,所以不了解,回答准确,因此我把票投给了第二个模型,之后就显示了2个模型的名字。
这种匿名评测的方式反应了大多数普通人对不同模型结果的偏好程度,是一种非常典型的众包收集反馈结果的思路。
Chatbot Arena发布之后就引起了广泛的关注,最开始4月份上线的时候仅仅包含8个主流模型,而现在平台已经托管了43个模型以及这些模型的对比结果。
Chatbot Arena Conversation Dataset介绍
本次开源的Chatbot Arena Conversation Dataset就是来自上述匿名评测结果。
自三4月份推出以来,Chatbot Arena已成为一个广泛引用的LLM(大型语言模型)评估平台,强调大规模、社区参与和互动人类评估。在这短短的时间内,LM-SYS从1.9万个唯一的IP地址收集了约5.3万次投票,用于22个不同模型的评估。
基于这些数据,LM-SYS发布了两个用于人类偏好相关研究的数据集:
- 3.3万条来自Chatbot Arena的众包对话,带有人类偏好注释。
- 3000条来自MT-bench的专业级人工注释。
在LLaMA2分析博客文章中,官方估计MetaAI在LLaMA 2的人类偏好数据上花费了约800万美元,而那个数据集目前不可用,没有对大家开发。而此前业界发布的包含人类偏好的高质量对话数据集主要只有2个,一个是Anthropic发布的Anthropic/hh-rlhf和OpenAssistant发布的OpenAssistant/oasst1。
3.3万条Chatbot Arena的众包对话数据集
这个数据集包含了从2023年4月到6月在Chatbot Arena上收集的3.3万个经过清理的对话,带有成对的人类偏好。每个样本包括两个模型名称、完整的对话文本、用户投票、匿名用户ID、检测到的语言标签、OpenAI审核API标签、额外的有害标签以及时间戳。
为了确保数据的安全发布,LM-SYS已尽力删除包含个人身份信息(PII)的所有对话。此外,他们还包括了OpenAI审核API的输出,以标记不适当的对话。然而,LM-SYS选择不删除所有这些对话,以便研究人员可以研究与LLM在实际应用中使用以及OpenAI审核流程相关的安全性问题。
例如,LM-SYS还包括了由他们自己的有害标签生成的额外有害标签,这些标签是通过在手动标记的数据上对T5和RoBERTa进行微调训练得到的。
与现有的人类偏好数据集(如Anthropic/hh-rlhf和OpenAssistant/oasst1)相比,这个数据集具有以下特点:
- 包括20个LLM的输出,包括更强大的LLM,如GPT-4和Claude-v1。它还包含了这些最先进模型的许多失败案例。
- 包括来自超过13,000名用户的无限制对话。
3000条MT-bench人工注释对话数据集
这个数据集包含了6个模型对80个MT-bench问题生成的模型响应的3,300份专业级成对人工偏好。这6个模型分别是GPT-4、GPT-3.5、Claud-v1、Vicuna-13B、Alpaca-13B和LLaMA-13B。大部分标注者都是在每个问题的主题领域具有专业知识的研究生。因此是十分高质量的数据集。
MT-BENCH是一个专门为评估对话系统和指令性任务的模型而设计的评估基准。它涵盖了多轮对话,并包括了一系列复杂问题,旨在测试模型的理解能力、上下文理解和指令遵循能力。这个基准的目标是提供一个有挑战性的测试集,以帮助研究人员更好地理解模型在实际对话场景中的表现。也是LM-SYS为了弥补众包偏好收集缺陷所提出的一个评测系统。
Chatbot Arena Conversation Dataset详细字段和下载地址
Chatbot Arena Conversation Dataset是开源的数据集,具体包含了如下字段:
可以看到,数据集包含的信息非常丰富。此外,需要注意的是Chatbot Arena Conversation Dataset包含2中开源协议,其中用户输入的prompt是CC-BY-4.0开源协议,可以免费商用,而模型输出部分的开源协议是CC-BY-NC-4.0,不允许商用!
Chatbot Arena Conversation Dataset下载地址:https://huggingface.co/datasets/lmsys/chatbot_arena_conversations
MT-bench人工注释对话数据集(expert-level human annotations)详细字段和下载地址
MT-bench人工注释对话数据集(expert-level human annotations)的主要字段格式和上面一样,都包含如下:
可以看到,相比较此前的数据集字段,MT-bench人工注释对话数据集(expert-level human annotations)主要是删除了有害标记部分,因为这是人类专家注释的,所以结果可控。这部分数据集开源协议是CC-BY-4.0开源协议,完全免费商用授权。
MT-bench人工注释对话数据集(expert-level human annotations)下载地址:https://huggingface.co/datasets/lmsys/mt_bench_human_judgments
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
