如何让大模型(GPT)按照特定的JSON格式输出?OpenAI给出新答案:GPT模型现在可以支持更加友好和精确的格式化JSON输出了!
今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了return_format={"type":"json_schema","json_schema": {...}}参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!

OpenAI的GPT接口强大的JSON输出能力
在此之前,大多数大语言模型都难以可靠地输出JSON格式化内容。但是在2023年11月的OpenAI开发者大会上,OpenAI在其官方接口中引入了return_format参数,当我们设置return_format={"type":"json_object"}的时候,使得大模型可以以JSON格式输出,大大提高了JSON输出的可靠性。但是,这个参数不能保证模型的响应符合特定的JSON模式(schema)。
今天,OpenAI进一步提升了大模型的格式化输出能力,支持以指定的JSON模式输出。这意味着大模型在格式化输出方面的能力进一步增强,为开发者和企业提供了更高效的解决方案。
此前,开发者一直通过开源工具、提示和反复请求等方法来解决LLM在生成符合系统需求的输出格式时的局限性。如LangChain的格式化输出工具等。今天,OpenAI的结构化输出解决了这个问题,通过约束OpenAI模型以匹配开发者提供的模式,并训练我们的模型更好地理解复杂的模式。
在OpenAI官方的复杂JSON模式遵循的评估中,新模型gpt-4o-2024-08-06使用结构化输出的得分为满分100%。相比之下,gpt-4-0613的得分不到40%。
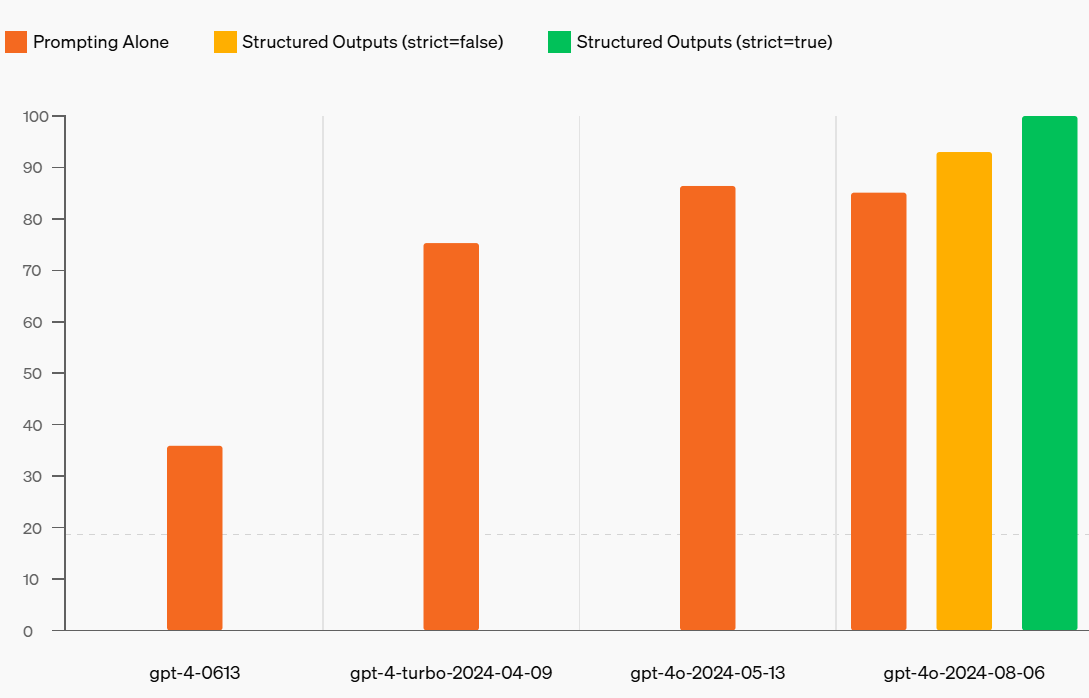
在上图中,复杂的JOSN输出测试中,单纯地依靠Prompt工程,GPT-4-0613只能达到40%的准确率,随着OpenAI模型版本的迭代,能力也在增强,但是当设置了严格的格式化输出参数后,最新的模型已经可以百分百满足复杂的格式化JSON模式输出了!
OpenAI的JSON Format和JSON Schema两种参数的差异
说到这里,大多数人可能依然无法明确知道本次OpenAI能力的提升具体点。以及新的JSON Schema参数的作用。
详细来说,OpenAI的官方GPT接口中有一个return_format参数,可以帮助我们控制大模型的输出。在去年推出的时候,这个参数只能用来确保大模型生成合格的JSON结果(用{"type":"json_object"}表示)。本次OpenAI则增加了{"type":"json_schema","json_schema": {...}}参数支持,可以让大模型按照特定的JSON模式输出。
这两个参数 (json_schema 和 json_object) 在设置响应格式时具有不同的功能和应用场景:
json_schema
- 参数设置:{ "type": "json_schema", "json_schema": {...} }
- 功能:启用结构化输出,确保模型生成的输出符合您提供的JSON模式(schema)。
- 应用场景:当您需要模型生成的JSON输出严格遵循特定结构或格式时使用。比如,当您有明确的字段要求和数据类型时,这种模式会非常有用。它确保模型输出的每个字段都符合指定的模式,减少了后期数据处理的复杂性。
json_object
- 参数设置:{ "type": "json_object" }
- 功能:启用JSON模式,确保模型生成的消息是有效的JSON格式。
- 应用场景:当您只需要保证输出是有效的JSON格式,但不需要严格遵循特定的结构时使用。在这种模式下,您仍需通过系统或用户消息指示模型生成JSON。否则,模型可能会生成一个包含大量空格的无效输出,直到达到令牌限制,导致请求长时间运行且看似卡住。此外,如果生成超出最大令牌数或会话超出最大上下文长度,消息内容可能会部分被截断。
主要差别总结
- json_schema:适用于需要严格控制输出结构的情况,通过提供具体的JSON模式,确保输出符合预定义的结构。
- json_object:适用于只需确保输出为有效JSON格式的情况,模型需要明确指示生成JSON内容。
从这里可以看到二者的区别,在复杂的应用开发中,这个特性将大幅降低大模型应用的门槛。
哪些场景支持json_schema
官方的描述中,OpenAI的GPT接口中支持在Response Format参数和Function Calling参数中设置返回结果为JSON Schema格式,且有一个strict参数来确保模型是否严格遵守JSON模式。
以下是关于API中两处可以使用JSON Schema的场景,并区分strict与否的总结:
这两种场景分别在函数调用和响应格式设置中使用了JSON Schema,并通过strict参数控制输出是否严格匹配提供的Schema。
大模型稳定输出JSON意味着什么?
人工智能大语言模型的一个显著特点是能够生成自然流畅的文本内容。最早广为人知的ChatGPT应用正是凭借其与人类对话的能力引起了广泛关注。这种交互方式非常适合聊天类应用,为用户提供了全新的体验。
然而,随着大语言模型逐渐向生产工具领域拓展,单纯的文本输出在与现有系统对接时面临着诸多挑战。在开发者应用或企业级系统中,结构化的数据交换格式(如JSON)往往能提供更高的效率和准确性。
官方给出了支持JSON Schema之后模型强大的灵活能力。
根据用户意图动态生成交互页面
即当我们定义了一套HTML的代码逻辑之后,大模型严格按照字段输出结果。获得这个结果直接渲染得到页面。这种方式我们只需要定义一套输出逻辑,就可以根据用户不同的输入展示输出结果。代码也可以嵌套生成。
使用思维链推理提高模型效果,同时获得最终答案
大模型推理一个重要的prompt技巧是思维链。即让模型根据特定的步骤输出每一个步骤的结果进行推理。这种方式的优点是结果准确性大幅提高,但是由于推理结果包含推理过程,对于仅需要最终答案的场景来说是很麻烦的。
这种情况,定义模型将推理步骤放入特定字段,最终结果放入指定字段后,我们可以充分利用思维链技术获得大模型最终答案。
如下是定义返回json schema的一个例子:
{
"model": "gpt-4o-2024-08-06",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant"
},
{
"role": "user",
"content": "9.11 and 9.9 -- which is bigger?"
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "reasoning_schema",
"strict": true,
"schema": {
"type": "object",
"properties": {
"reasoning_steps": {
"type": "array",
"items": {
"type": "string"
},
"description": "The reasoning steps leading to the final conclusion."
},
"answer": {
"type": "string",
"description": "The final answer, taking into account the reasoning steps."
}
},
"required": ["reasoning_steps", "answer"],
"additionalProperties": false
}
}
}
}
然后GPT的接口返回结果则是:
{
"reasoning_steps": [
"First step is to compare the numbers 9.11 and 9.9.",
"Both numbers have the same whole number part, which is 9.",
"To compare the decimal parts, convert them to the same number of decimal places.",
"9.11 has two decimal places: it is 9.11.",
"9.9 has one decimal place: it can be rewritten as 9.90.",
"Now, compare 9.11 and 9.90 by looking at the decimal parts.",
"Compare 11 with 90.",
"90 is greater than 11, so 9.90 is greater than 9.11."
],
"answer": "9.9 is bigger than 9.11."
}
这样既能大幅提高准确率也能获得而最终结果!
从非结构化数据中提取结构化信息
例如给出一个大段文本,然后提取日程列表。以前的结果非常麻烦。但是最新的定义则很容易获取。只需要描述提取的字段,GPT接口可以自动组装提取列表。
OpenAI是如何实现JSON Schema输出的?
总的来说,官方提升模型的同时采用了工程化技巧来解决这件事情。这里我们不细说了,我们直接翻译如下:
内部工作机制
我们采用了两部分的方法来提高模型输出与JSON Schema匹配的可靠性。首先,我们训练了最新的模型gpt-4o-2024-08-06,使其理解复杂的模式并且能够最好地生成与之匹配的输出。然而,模型行为本质上是非确定性的——尽管该模型的性能有所提升(在我们的基准测试中达到了93%),但仍未达到开发人员构建可靠应用程序所需的可靠性。因此,我们还采用了一种基于工程的确定性方法来约束模型的输出,以实现100%的可靠性。
约束解码技术
我们的方法基于一种称为约束采样或约束解码的技术。默认情况下,当对模型进行采样以生成输出时,它们是完全不受约束的,可以从词汇表中选择任何token作为下一个输出。这种灵活性使模型容易出错;例如,即使在生成无效JSON时,它们通常也可以随时采样大括号token。为了强制生成有效的输出,我们将模型约束在根据提供的模式有效的token,而不是所有可用的token。
在实践中实现这种约束是具有挑战性的,因为在模型输出的不同阶段,有效token是不同的。假设我们有以下模式:
在输出的开始,有效token包括{, {“, {\n等。然而,一旦模型已经采样了{“val, 那么{就不再是一个有效的token。因此,我们需要实现动态约束解码,并在每个token生成后确定哪些token是有效的,而不是在响应开始时就确定。
为此,我们将提供的JSON Schema转换为上下文无关文法(CFG)。文法是一组定义语言的规则,而上下文无关文法是符合特定规则的文法。可以将JSON和JSON Schema视为具有定义其有效性规则的特定语言。就像在英语中没有动词的句子是无效的一样,在JSON中有尾随逗号也是无效的。
因此,对于每个JSON Schema,我们计算出一个表示该模式的文法,并预处理其组件,以便在模型采样期间易于访问。这就是为什么第一次请求新模式会有延迟的原因——我们必须预处理模式以生成这个在采样期间可以高效使用的工件。
在采样期间,每个token之后,我们的推理引擎将根据先前生成的token和文法中的规则来确定接下来哪些token是有效的。然后我们使用这个token列表来屏蔽下一次采样步骤,有效地将无效token的概率降低到0。由于我们已经预处理了模式,我们可以使用缓存的数据结构高效地完成这一操作,延迟开销最小。
替代方法
解决此问题的替代方法通常使用有限状态机(FSM)或正则表达式(通常由FSM实现)进行约束解码。这些方法的功能类似,因为它们在每个token生成后动态更新哪些token是有效的,但与CFG方法有一些关键区别。值得注意的是,CFG可以表达比FSM更广泛的语言类别。实际上,对于非常简单的模式,这并不重要。然而,我们发现,对于涉及嵌套或递归数据结构的更复杂模式,这一差异是有意义的。举例来说,FSM通常无法表达递归类型,这意味着基于FSM的方法可能难以匹配深度嵌套JSON中的括号。以下是一个支持OpenAI API结构化输出的递归模式示例,但用FSM是无法表达的。
请注意,每个UI元素可以有任意的子元素,这些子元素递归地引用根模式。这种灵活性是CFG方法所提供的。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
