Arena Hard:LM-SYS推出的更难更有区分度的大模型评测基准
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。
什么是Arena Hard
Arena Hard不仅仅是另一个静态测试;它是一个复杂的数据管道,利用来自Chatbot Arena(一个受欢迎的众包LLM评估平台)的实时数据构建高质量的基准。这个创新的方法确保了基准测试始终保持最新,反映了现实中的用户互动,避免了测试集泄漏的问题。目前,基准测试的版本是Arena-Hard-Auto v0.1,包括500个直接来自Chatbot Arena的挑战性用户提问。
传统的基准测试存在几个主要缺点
传统的大模型评测基准,如MMLU等,其实已经无法有效区分大模型的能力了。2023年3月份,GPT-4在MMLU获得了86.4分之后,大模型在这个评测基准上的得分非常有限,一部分是因为这个评测本身包含了一些错误,一部分也是因为评测基准本身不够复杂,无法区分强的大模型的能力。
传统的这些基准测试主要的问题可以总结如下:
- 静态问题集:固定的数据集可能导致模型只针对基准本身进行优化,而非真正的改进。
- 缺乏现实相关性:许多基准使用人工任务或选择题格式,这些并不反映实际的LLM使用场景。
- 区分度差:随着模型越来越复杂,传统的基准测试常常无法有效区分它们的表现。
Arena Hard的出现,正是为了应对这些具体问题,提供一种更为相关、可靠且动态的评估方法。
Arena Hard的工作原理
LM-SYS是一个多个高校研究人员组成的大模型研究机构,此前,该机构最著名的是推出了大模型匿名竞技场,即Chatbot Arena,让普通人使用这个平台对大模型提问,然后不同的匿名模型同时返回答案,用户投票选择谁更好的方式来做大模型评测。
关于LM-SYS具体的问题介绍:https://www.datalearner.com/ai-organizations/LM-SYS
Arena-Hard 的数据来源于 Chatbot Arena。Chatbot Arena 收集了超过 200,000 条用户查询,Arena-Hard 从这些数据中自动提取高质量的提示(prompts),以确保评测基准的多样性和质量。
而Arena Hard是他们最新的成果,简单总结如下: 首先用主题模型和大模型从众包问题中提取不同类型的问题,大约有4000个,然后从中筛选250个高质量主题,每个主题下再随机抽取2个历史用户的提示词,组成包含了500个提示词的评测集。
评测新模型的时候,让新模型回答这个评测集,再将答案与基准模型(GPT-4)答案对比,用更强的模型对比新模型和基准模型,获得最终的分数。
Arena Hard的主要特点
- 实时数据驱动:利用实际用户互动生成相关且具有挑战性的提问。
- 自动化评估:使用GPT-4-Turbo作为自动评判工具,比对模型的回答,减少人工评估的需求。
- 高可分离性:有效区分不同模型的表现。
- 与人类偏好高度一致:与用户在Chatbot Arena上表达的偏好高度契合。
- 成本高效且快速:自动化评估使得评估过程比传统方法更快捷、更经济。
- 定期更新:定期刷新,确保基准测试的相关性,并防止过拟合。
Arena Hard和其它评测基准的对比
LM-SYS官网对Arena Hard和一些评测基准做了对比,发现Arena Hard对于模型有更好的区分度。
下表是对比结果:
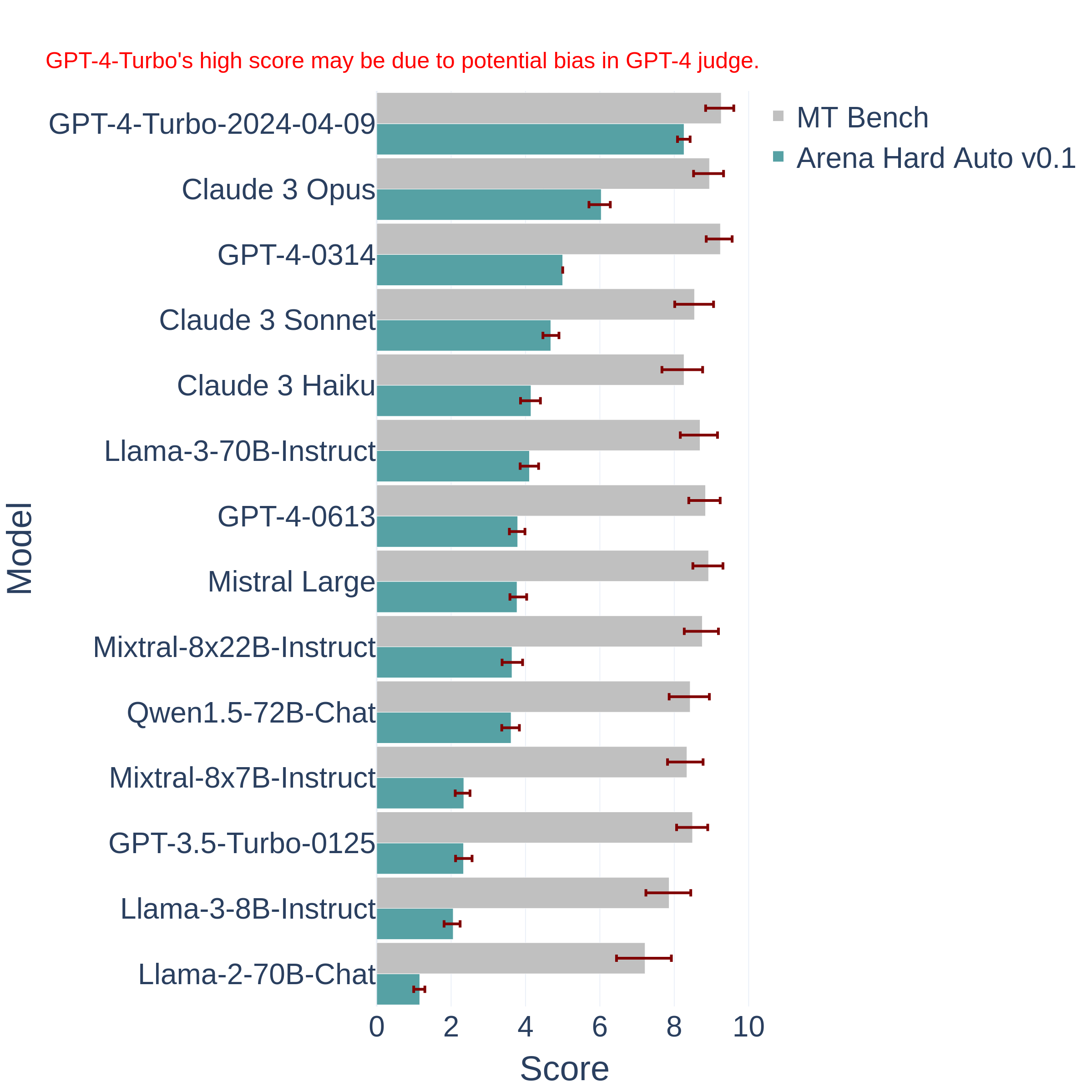
同时,LM-SYS也给出了Arena Hard对不同模型的评测结果:
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
