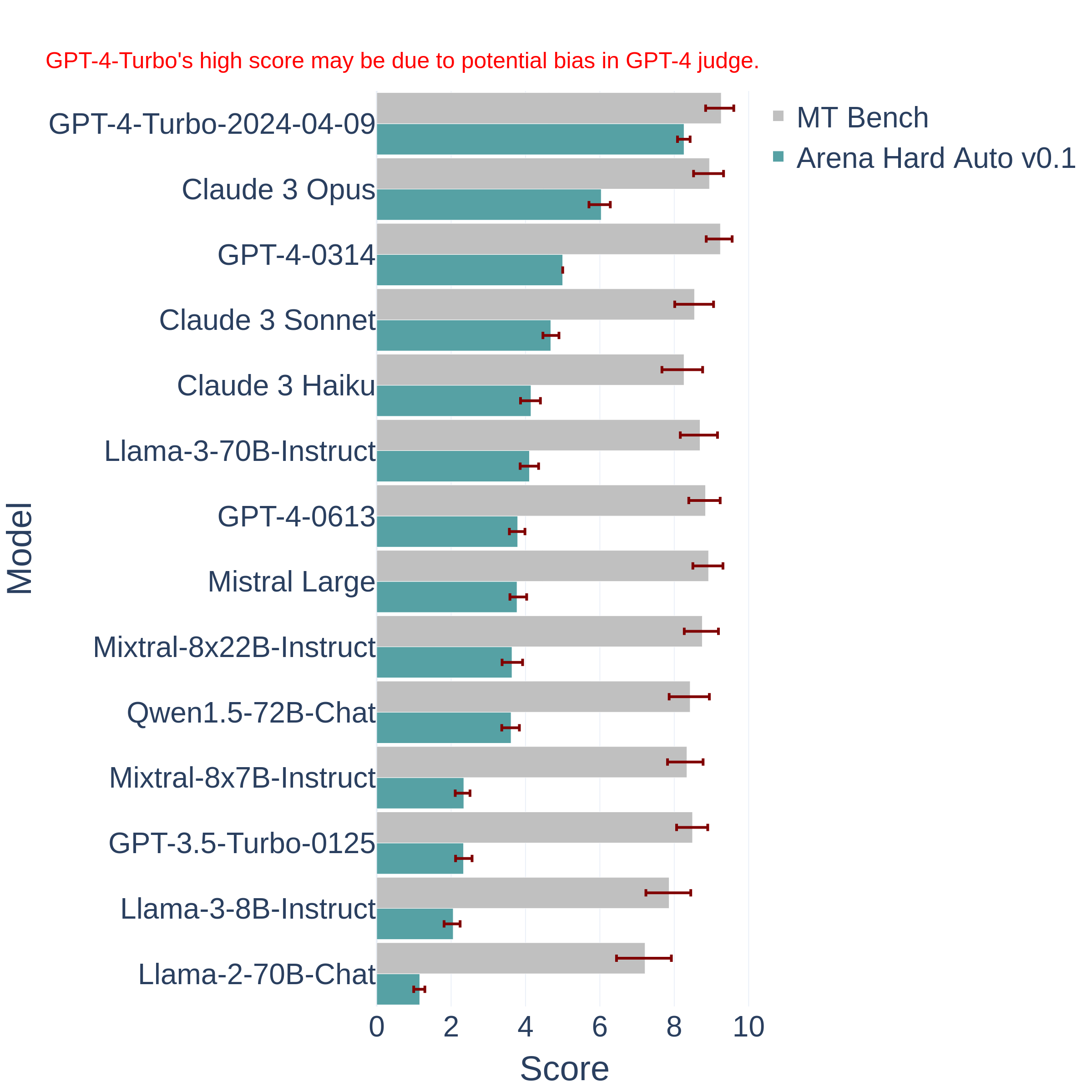
Arena Hard:LM-SYS推出的更难更有区分度的大模型评测基准
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。
汇总「ArenaHard」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。