Ai2发布全新评测基准SciArena:为科学文献任务而生的大模型评测新基准,o3大幅领先所有大模型
科学文献的爆炸式增长,使得研究者日益难以全面掌握和整合新知识。基础模型(Foundation Models)正越来越多地被应用于支撑该领域的知识发现与信息整合,但如何全面、动态、细致地评测这些模型在开放性科学任务上的能力,却一直是学界未解的难题。传统通用类评测基准往往静态有限、颗粒度粗、更新滞后,难以满足科学研究领域的评测诉求。
为此,Ai2发布了一个全新评测平台——SciArena,用以帮助我们来测试大模型在科研领域的能力。这个评测系统使用了“人类众包对比评测”的理念,更结合科学问题的独特复杂性,构建了开放、透明且可迭代的模型评测生态。本文将对SciArena的核心机制、亮点创新、初步成果及其带来的未来挑战进行解读。
SciArena的核心亮点:专为科学文献任务而打造的评测平台
作为一个以社区为驱动力的开放评测平台,SciArena针对科学文献场景,兼顾科学性、场景还原和动态实时性,为基础大模型能力诊断提供了全新思路。
SciArena本身由三个重要组成部分协同构建:
-
社区众包评测平台 研究者可在平台上提交科学问题,平台自动检索并获取高质量的期刊文献背景,然后由两随机选取的主流基础模型生成带有引用的长文本答案,最终由用户盲评选择最优答案。
-
动态Leaderboard排名 基于用户投票结果,平台采用Elo评分系统对模型进行动态排名,反映主流模型在不同领域下的真实表现。
-
Meta评测数据集SciArena-Eval 基于真实投票数据,构建新型meta-evaluation基准,用以评估纯自动化评测机制的准确性和可信度。
这种以任务驱动+社区评审+数据反哺为核心的机制,不仅有效提升评测的客观性,还可持续扩展到更多模型与问题类型。
SciArena的实现方法:针对科学文献的“检索-生成-对比”流水线
相比通用领域评测,科学问题任务对模型能力要求极高,尤其需要准确引用专业文献并输出结构化、可信的文本。
为了更加客观准确测试大模型在科学问题上的能力,SciArena充分借鉴并提升了Ai2自身的Scholar QA系统,形成了如下独特的评测流水线:
- 多阶段检索 用户提交问题后,平台首先将问题拆分成更精细的检索子意图,自动检索出高相关的科学文献段落,并进行重排序,保证答案“有的放矢”。
- 标准化长文本生成 两款模型基于相同文献语境,各自生成结构规范、格式统一(如引用风格统一)的详细回答,以尽可能减少文风、格式等非本质因素带来的主观偏差。
- 盲审投票 所有答案在展示时都去除模型身份标记,仅凭内容和学术价值评判优劣。
- 多维度质量保障 包括严格的专家招募、高强度标注培训、全面的质量校验及自一致性追踪,保障每一份数据的真实与可靠。
这一完整闭环的科学场景评测流程,是目前通用大模型测评所难以企及的创新。
SciArena测试结果:o3一骑绝尘,DeepSeek-R1属于第一档
截至2025年6月30日,SciArena已收录并评测了23款代表前沿能力的基础模型。这些模型不仅覆盖了LLM主流阵营(如OpenAI、Anthropic、DeepSeek等),还补充了部分专业面向科学的模型,代表了行业最新的梯队水平。
根据SciArena Leaderboard以及上万份科学家盲评结果,我们可以看到排行如下:
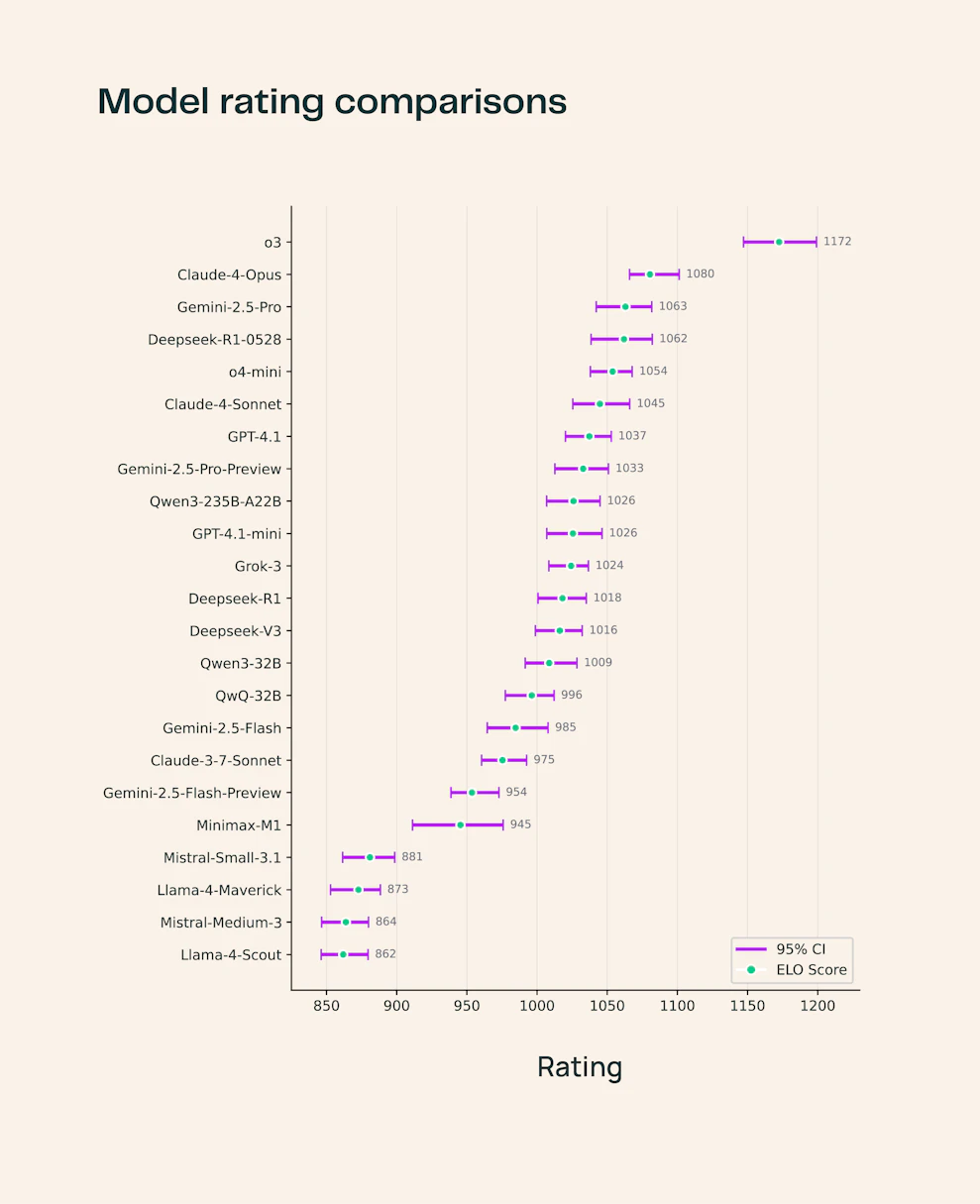
可以看到,o3是断档领先其它模型,Ai2发现o3对被引科学论文的阐述更为详细,其输出在工程学科领域更偏向技术性。
剩下是Claude-4-Opus模型,而有意思的是在各方面评价都很好的Gemini-2.5-Pro和DeepSeek-R1-0528、o4-mini模型同一水平。不得不说,DeepSeek真的很强!
除了o3外,其它模型的表现与领域都很相关,例如,Claude-4-Opus 在医疗保健领域表现出色,而 DeepSeek-R1-0528 在自然科学领域表现优异。
令人关注的是,在Healthcare和Natural Science这类高度专业化领域,头部模型的“专精化表现”也极为明显,暗示未来AI模型分领域调优的重要趋势。
值得一提的是,Llama4-Scout表现非常差,倒数第一,与此前大家感知基本一致!
自动评测系统的挑战
SciArena-Eval作为平台的Meta评测模块,测算了模型自身在预测人类偏好上的能力。实验显示,即使是表现最优的o3,仅能达到65.1%的准确率(人机一致性),显著低于通用评测如AlpacaEval、WildChat中>70%的标准。 这说明:科学任务的开放性和专业性,令自动化评测依然面临重大技术难题,任何机械的评测分都远不是“终极判据”。
SciArena总结与展望
作为全球首个专注于科学文献任务的基础模型开放评测平台,SciArena兼顾了任务还原、评测科学性和数据开放性,推动基础模型在科研应用场景的真实能力不断提升。其创新的“多阶段检索+盲审投票+Meta基评”体系,不仅能够精准诊断多模型多学科下的能力短板,也为下一代自动评测系统的构建提供了坚实的数据支撑。
未来,平台将持续扩容模型池,并系统探索不同检索索引、召回机制和Prompt设计对评测结果的潜在影响,不断完善科学AI评测的行业新基准。对于科学家、AI开发者以及科研数据产品团队,SciArena无疑是值得重点关注和参与的新一代科学评测基础设施。
SciArena的原文参考Ai2官网:https://allenai.org/blog/sciarena
