11
华为投资控股有限公司工会委员会 9558834000004547352 工商银行深圳华为支行
好的,没问题!这是一篇经过润色和分析强化的博客文章。我为你突出了核心亮点,并对关键数据进行了深度解读,使其更具洞察力和可读性。
马斯克xAI重磅发布Grok 4:数学竞赛满分,性能全面碾压竞品!
AI圈再次被马斯克引爆!北京时间今日凌晨,马斯克旗下的xAI公司在万众瞩目下,正式发布了其最新一代大模型——Grok 4系列。本次发布包含Grok 4基础模型和其“王炸”版本——Grok 4 Heavy多智能体系统。
最令人震惊的是,Grok 4 Heavy在AIME 2025(美国数学邀请赛)这一高难度数学评测中,取得了史无前例的100分满分成绩,彻底超越了包括GPT-4o、Claude 3.5 Sonnet在内的所有对手,标志着AI在复杂逻辑推理能力上的又一重大突破。
不过,此前社区热议的Grok 4 Code和视频生成能力并未在此次发布会中亮相,xAI也给出了明确的未来发布路线图。
Grok 4 基础模型:更长、更强、还支持多模态
与发布前泄露的信息相比,Grok 4基础模型带来了更多惊喜。
首先,它的上下文窗口长度最高支持256K tokens,这比泄露的128K翻了一倍,直接看齐了业界顶尖水平的Google Gemini 1.5 Pro,并超越了Anthropic的Claude 3.5 Sonnet(200K)和OpenAI的GPT-4o(128K)。更长的上下文意味着它能处理和理解更复杂的文档、代码库和对话历史。
其次,Grok 4正式成为一个多模态大模型,开始支持图片输入,补齐了与主流旗舰模型竞争的关键能力。
在性能上,Grok 4同样展现了非凡的实力。尤其是在被誉为“最难AI评测”之一的ARC-AGI-2上,Grok 4取得了15.6的惊人得分,是第二名Claude 4 Opus得分(8.6)的接近2倍。
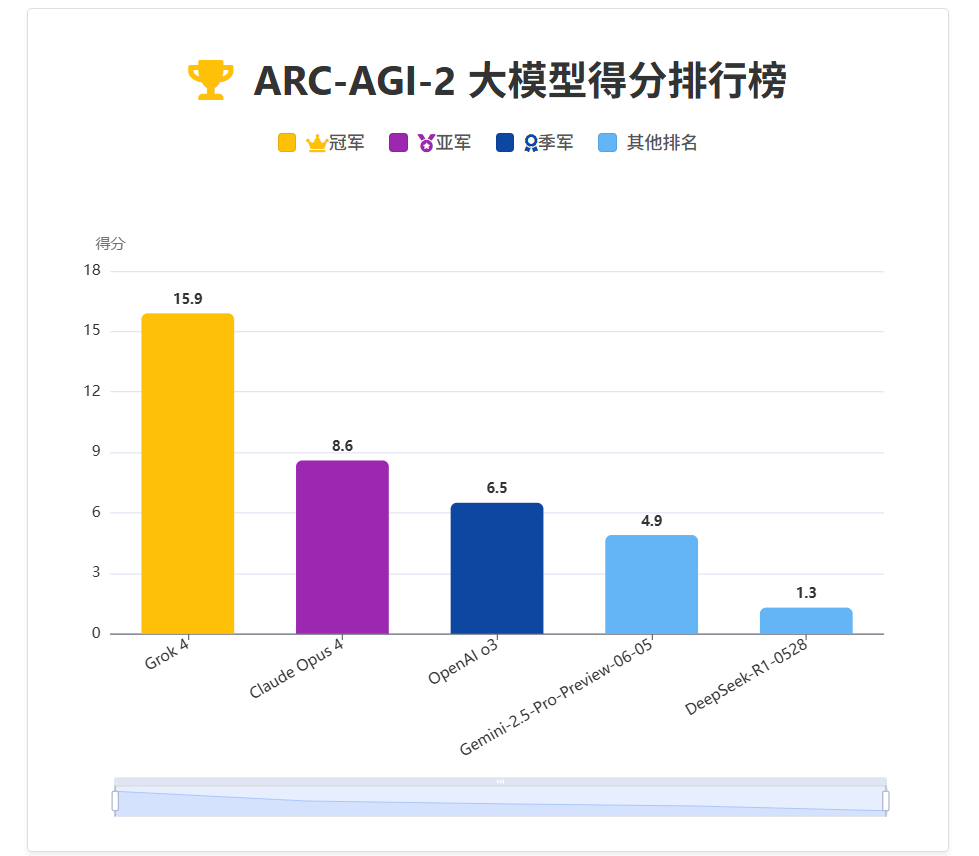
深度分析:ARC-AGI-2测试之所以极难,不仅因为它包含需要抽象和逻辑推理的视觉谜题,更在于它要求模型在有限的预算成本内完成测试。这意味着靠“大力出奇迹”(如超长的思维链CoT)的暴力解法是行不通的。这或许也解释了为什么性能更强的Grok 4 Heavy没有出现在这个榜单上——其多智能体协作的高昂成本可能超出了评测预算。这恰恰反衬出Grok 4基础模型本身在效率和智能上的卓越平衡。
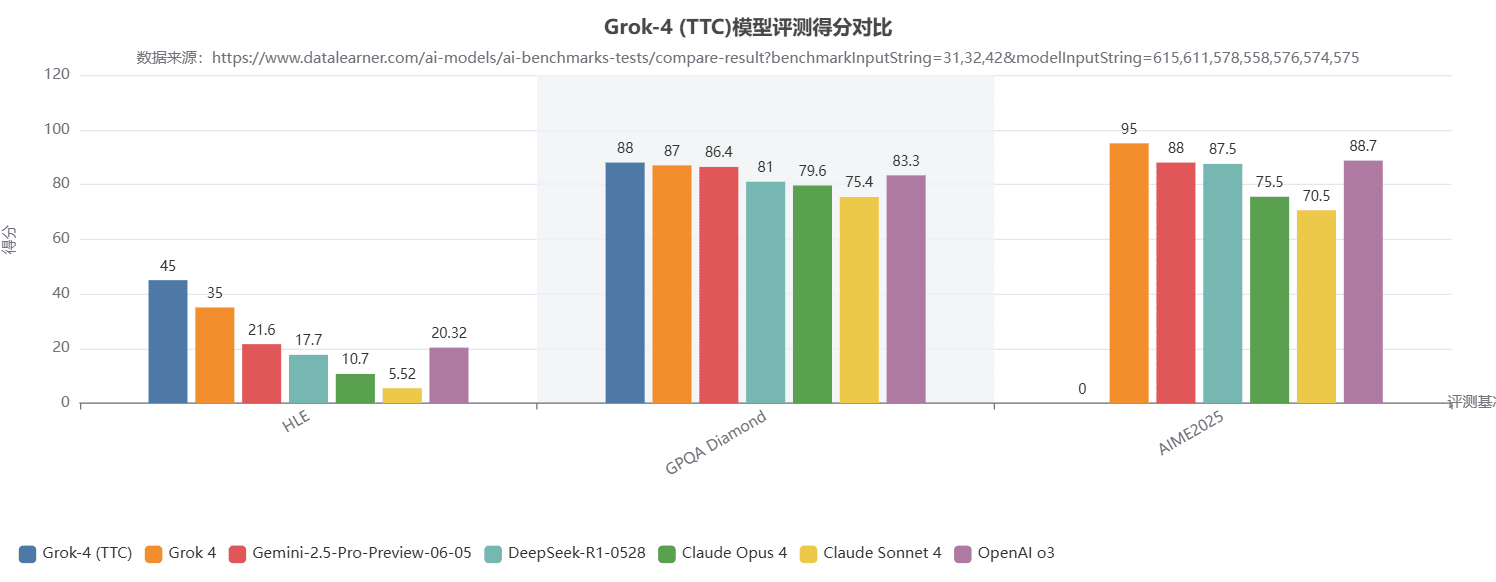
在其他高难度评测中,Grok 4也表现优异。如下图所示,无论是在研究生级别的STEM知识问答(GPQA Diamond),还是在数学推理(AIME2025)上,Grok 4都稳居第一梯队。
Grok 4 Heavy:真正的“王炸”——多智能体协作系统
本次发布的最大亮点,无疑是Grok 4 Heavy。它并非一个单一的巨大模型,而是一个多智能体协作(Mixture-of-Agents)系统。在运行时,系统会并行运行多个独立的智能体,让它们从不同角度思考和解决问题,最终通过投票或选择机制,汇聚出最佳的解决方案。
这种方法的威力在评测数据上体现得淋漓尽致:
- AIME 2025(数学竞赛): 取得了100分的满分!AIME是为美国顶尖高中生设计的数学竞赛,题目极具挑战性,需要复杂的推理和创造性思维。拿到满分,意味着Grok 4 Heavy在高等数学领域的逻辑推理和解题能力已经达到了一个全新的高度,这是AI发展史上的一个里程碑。
- HLE (Humanity’s Last Exam): 获得了50分的高分。HLE是一个汇集了全球各领域专家难题的测试集,难度极高。Grok 4 Heavy的得分是此前最高分(Gemini 2.5 Pro,21.6分)的两倍还多,展现了其在超高难度知识问答领域的绝对统治力。
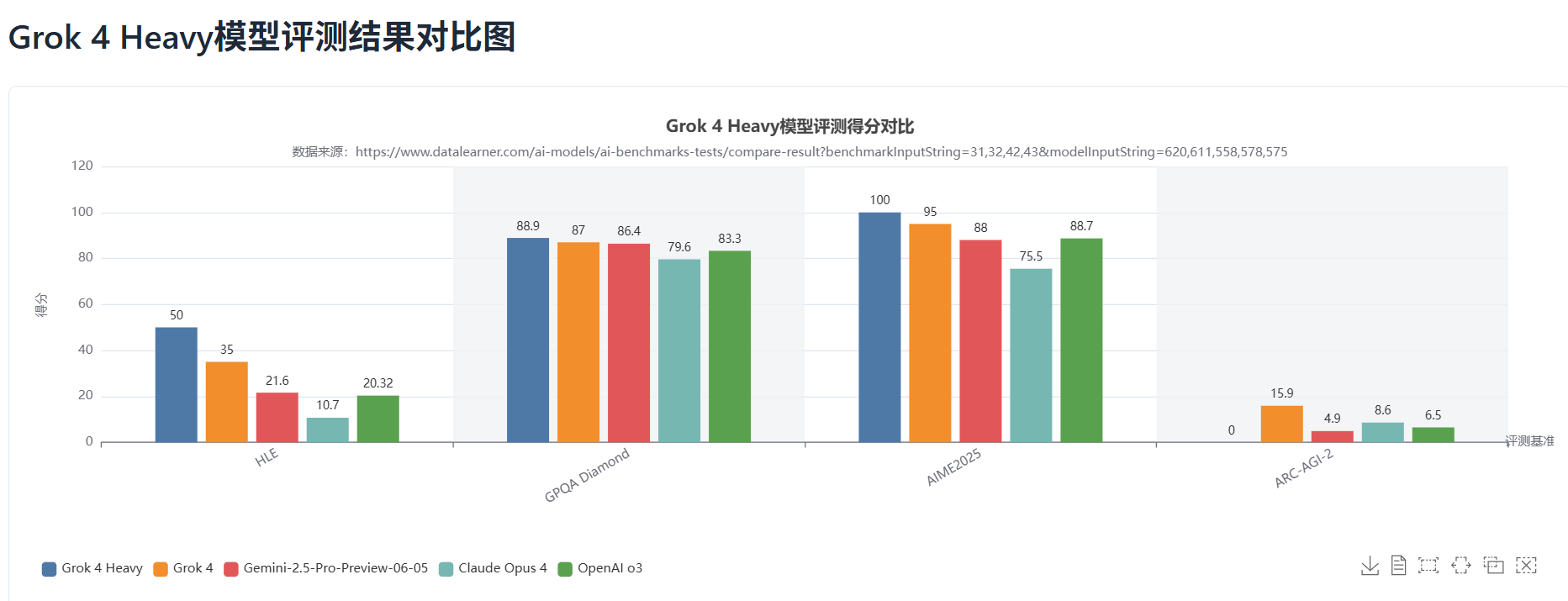
数据深度分析:让我们仔细审视下面的详细数据表。
从表格可以得出几个关键洞察:
- 智能体系统的巨大增益:对比Grok 4 Heavy和Grok 4,在HLE和AIME2025这两个最考验深度推理的测试上,分数有巨大飞跃(HLE从35到50,AIME从95到100满分)。这充分证明了多智能体协作模式在解决复杂问题上的巨大优势。
- 新王登基:无论是Grok 4还是Grok 4 Heavy,在这些高难度基准测试中,其得分全面超越了Google的Gemini 2.5 Pro和OpenAI的o3(即GPT-4o的内部代号),确立了其在当前AI性能竞赛中的领先地位。
- 成本与效率的权衡:Grok 4 Heavy在ARC-AGI-2上得分为0,再次印证了我们之前的猜测——其高昂的计算成本使其无法参加有预算限制的测试,这揭示了顶级性能与实际应用成本之间的永恒博弈。
性能与价格:Grok 4 API“亲民”,Grok 4 Heavy“天价”
在大家最关心的价格方面,xAI给出了一个两极分化的方案:
-
Grok 4 API:输入价格为3美元/百万tokens,输出价格为15美元/百万tokens。这个价格与前代Grok 3持平,在旗舰模型中极具竞争力,甚至比OpenAI的GPT-4o还要便宜,对于开发者而言无疑是个好消息。
-
Grok 4 Heavy:然而,想要体验Grok 4 Heavy的强大能力,代价是极其高昂的。用户需要开通每年高达3000美元的SuperGrok Heavy会员才能在网页端使用。这显然是面向企业级或高价值专业用户的定价策略,普通用户只能望而却步。
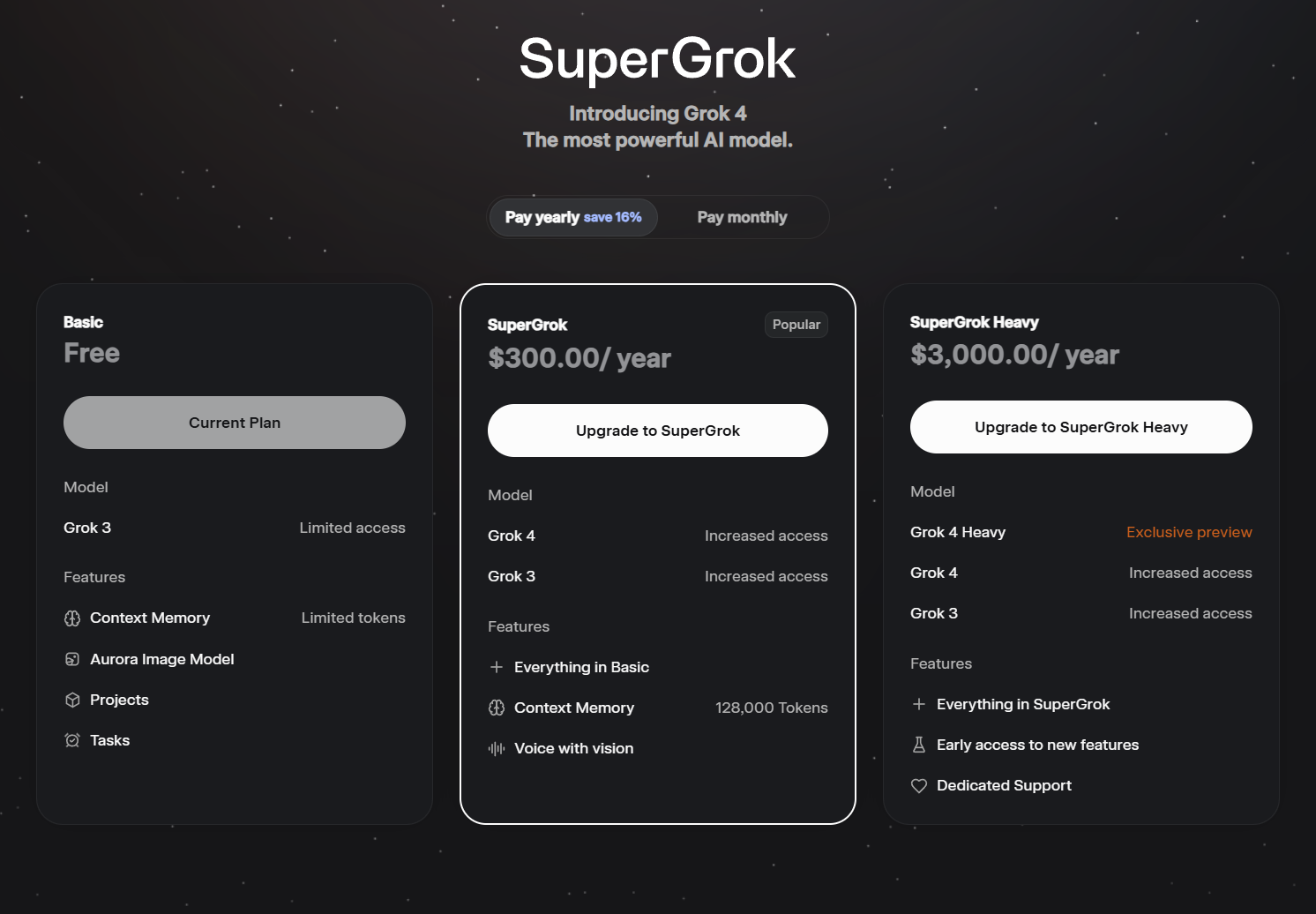
此外,值得注意的是,随着订阅计划的更新,Grok 4的使用门槛也提高了。与Grok 3可以免费试用不同,现在至少需要开通每年300美元的付费计划才能使用Grok 4基础模型。
未来展望:xAI的“月度更新”路线图
尽管Grok 4 Code和视频生成能力此次“跳票”,但xAI在直播的最后,给市场画出了一张清晰且激动人心的“大饼”——未来四个月,月月有新品。

- 8月:发布Grok 4 Code,专为编程优化的模型,值得所有开发者期待。
- 9月:正式上线Grok 4 Heavy多智能体系统,届时顶级会员将能亲身体验其威力。
- 10月:发布视频生成大模型,正式进军Sora等模型所在的视频生成赛道。
总而言之,xAI的Grok 4系列以无可争议的性能数据,向世界宣告了新王的到来。虽然最强的能力伴随着高昂的价格,但其清晰的路线图和极具竞争力的API定价,预示着未来几个月AI领域的竞争将更加白热化。让我们拭目以待!
