AI Agent时代如何写Prompt?来自Manus官方的最新的Context Engineering技巧总结
Context Engineering是最近比较火的概念,来源于社区关于Prompt Engineering概念的讨论。此前的Prompt主要是大模型的指令调优,但是,走向AI Agent之后,我们的提示词更多是让大模型知道当前所处的状态以及它拥有的工具、信息登上下文环境。因此,很多LLM大佬都认为使用Context Engineering更适合AI Agent时代的提示词描述。而Manus作为通用Agent中影响力最大的一员也在很多方面表现非常棒。由于Manus本身没有开发大模型,也没有开源,因此其内部的流程实现和提示词的优化可以说是核心竞争力之一了。几天前,Manus官方发布了一个博客,总结了他们的Context Engineering的实战技巧,这里面有很多内容非常具有参考价值,因此本文总结这方面的内容供大家参考。

围绕KV缓存的提示词设计,让重复的内容只算一次钱
Manus首先就强调了他们的提示词很多是围绕KV缓存设计的。大模型KV缓存(KV-Cache)是 Transformer 架构中一项推理优化技术,专门用来节省重复计算的开销。它的核心思想是:把之前算过的 Key(K)和 Value(V)矩阵缓存下来,后续生成新 token 时直接复用,不再重新计算。
简单来说就是为了提高大模型的推理速度,减少计算的开销,我们可以将部分输入的计算结果保存下来,下次一旦碰到相同的输入的时候就可以不用从0开始计算,进而可以提高模型的推理速度,减少计算成本,大多数大模型服务提供商都提供这样的技术,命中缓存的大模型接口的价格通常比常规推理的价格低非常多,这意味着更多的命中或使用KV Cache会极大的降低成本,提高推理速度。
不过这项技术有一个非常严格的前提条件,即前N个tokens必须完全一致,即使有一个很小的差异,也会造成提前计算的结果不准确。以OpenAI为例,只有当前1024个或者更长的输入相同的时候,才有可能命中缓存。
为了充分利用KV Cache的机制来提高推理速度,并降低成本,Manus的提示词都是围绕这个机制设计的。不仅是因为成本和推理速度,同样也是因为AI Agent系统的特点,Manus官方统计:
在接收用户输入后,代理通过一系列工具使用链来完成任务。在每次迭代中,模型根据当前上下文从预定义的动作空间中选择一个动作。然后在环境中执行该动作(例如,Manus的虚拟机沙盒)以产生观察结果。动作和观察结果被附加到上下文中,形成下一次迭代的输入。这个循环持续进行,直到任务完成。 正如你所想象的,随着每一步的推进,上下文不断增长,而输出——通常是结构化的函数调用——保持相对简短。这使得代理(agents)相比聊天机器人的预填充和解码比例高度倾斜。例如在Manus中,平均输入与输出的token比例约为100:1。
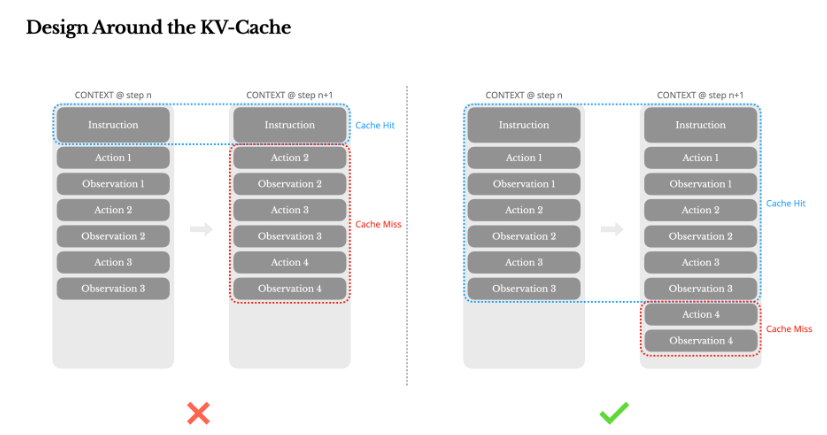
为了充分利用KV Cache的机制,Manus的提示词主要做法如下:
- 把系统提示(system prompt)写成固定模板,不要塞进实时时间戳、随机 ID 之类每次都会变的东西。
- 每次只把“新增的对话”追加到后面,绝不回头改前面的字。
- 如果必须手动插入缓存断点(某些云厂商要求),就放在 system prompt 末尾,并给每次会话固定一个 session_id,确保同一用户的请求落同一台机器。
这里对3简单介绍一下。3的描述是指不是所有的大模型厂商都会百分百命中缓存,有的厂商要求你明确告知哪部分是重复的,可以做缓存的,就是说你要设置一个缓存的断点,告诉云服务厂商,那么这时候你可以考虑把断点设计在system prompt之后,这个好处就是system prompt尽量不变,可以更高概率使用KV Cache。而固定会话id是将用户的会话请求保证落在一台服务器上可以避免一个用户的会话过程跑到另一台服务器上,另一台服务没有缓存,就造成了浪费了。
