大模型新王者!谷歌发布Gemini 3.0 Pro,各方面评测几乎都是第一,全球首个大模型匿名投票得分超1500分的模型,支持100万输入上下文!
谷歌终于在2025年11月18日发布了新一代Gemini 3模型:Gemini 3.0 Pro。该模型目前在各个评测排行榜中都获得了非常优秀的结果,几乎是领先了所有的模型。而根据此前大家的匿名投票评分和早期测试,该模型的文本生成、编程、SVG生成等方面都非常优秀。谷歌官方强调,Gemini 3.0 Pro不仅在推理能力上达到了新的业界巅峰,更在理解深度、细微差别以及“思考”能力上实现了质的飞跃。

更多Gemini 3.0 Pro的信息包括使用地址也可以参考DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/gemini-3-0-pro-preview-11-2025
Gemini 3系列定位:谷歌迄今为止最强的多模态大模型
Google 本次发布的 Gemini 3 是其两年来 Gemini 体系的最新阶段性成果。从官方披露的技术数据与产品部署规模来看,Gemini 3 的意义不仅是“一个更强的模型”,而是 Google 试图重构未来 AI 开发范式的关键节点。
Google 与 DeepMind 领导团队(Sundar Pichai、Demis Hassabis、Koray Kavukcuoglu)在介绍中强调了三点:
- 推理深度和语义细腻度的全面提升
- 更善于理解用户意图与交互上下文
- 将多模态、Agentic、长上下文能力进行系统整合
Gemini 3 不再只是“读文本和图片”,而是尝试做到“读场景、读情境、读任务结构”。Google 将其称作 the most intelligent model that helps you bring any idea to life。
Gemini 3 Pro:系统化领先的推理与多模态能力
从 Google 公布的多项权威评测结果来看,Gemini 3.0 Pro 在整体能力上已经呈现跨代提升,尤其是在推理、数学、多模态和长上下文任务中形成了明显领先优势。它的能力结构更均衡,在多个应用关键路径上表现出旗舰模型应有的强度。
下图展示了谷歌官方给出的Gemini 3.0 Pro的评测结果:
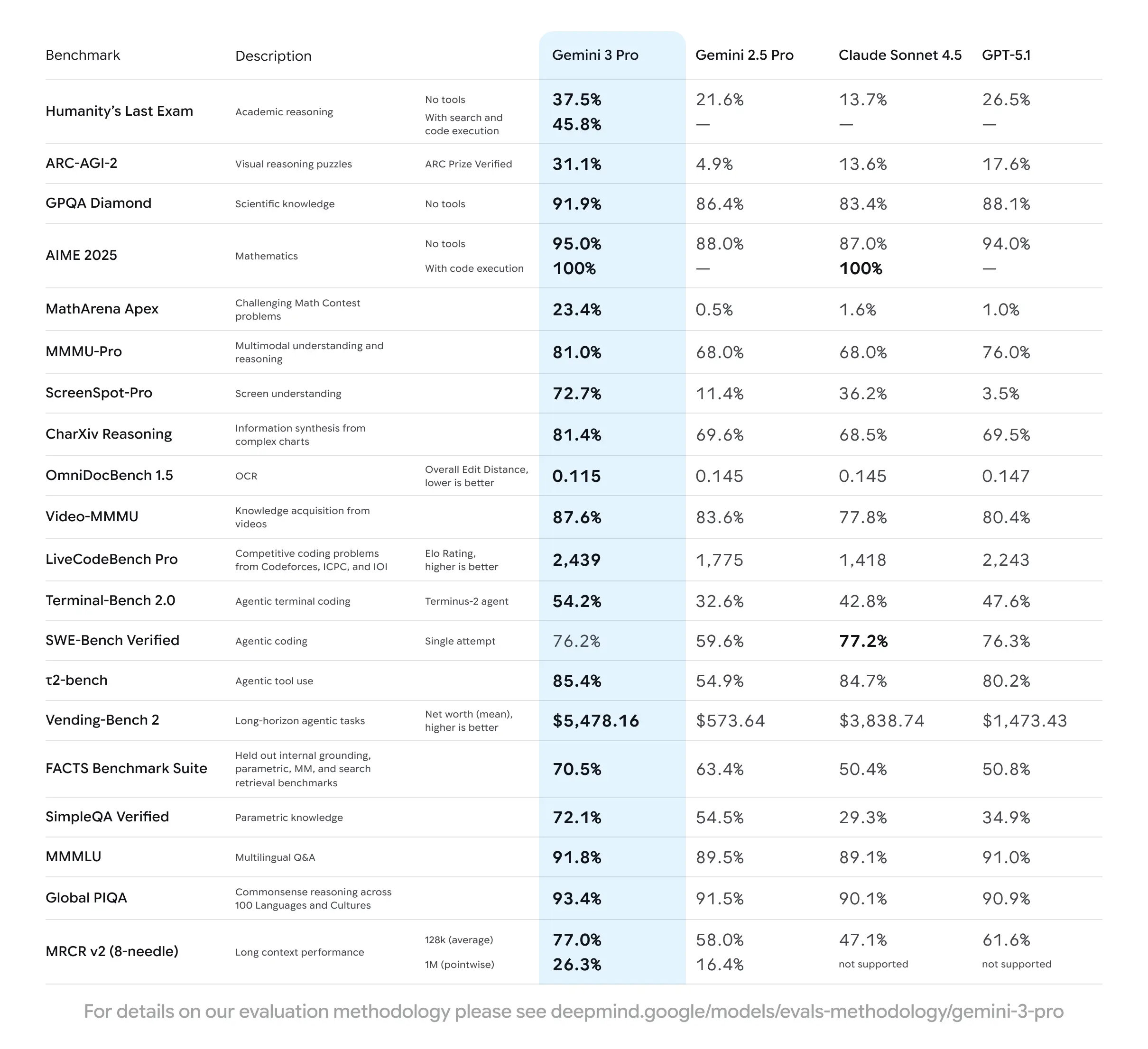
简短的说就是:Gemini 3.0 Pro 在推理强度、多模态、视频与屏幕理解等“真实任务能力”上形成了对 Gemini 2.5 Pro、Claude Sonnet 4.5 和 GPT-5.1 的全面领先。
具体的可以列举几个:
-
① 数学与科学推理:大幅领先同级模型
- AIME 2025:100%(GPT-5.1 为 94%,Claude 为 87%)
- GPQA Diamond:91.9%(显著高于 2.5 Pro 的 86.4% 和 GPT-5.1 的 88.1%) → 在高难度推理链路上形成第一梯队的领先差距。
-
② 多模态能力(尤其视频)领先幅度最大
- Video-MMMU:87.6%(相比 GPT-5.1 的 80.4% 和 Claude 的 77.8% 明显更高)
- ScreenSpot-Pro:72.7%(GPT-5.1 仅为 3.5%)
- MMMU-Pro:81.0%(领先 2.5 Pro 的 68%) → Google 的底层多模态优势在此代全面兑现。
-
③ 工具 / Agent 能力稳居第一梯队
- t2-bench:85.4%(Claude 4.5 为 84.7%,GPT-5.1 为 80.2%)
- Terminal-Bench 2.0:54.2%(优于 GPT-5.1 的 47.6%) → 在“Agent 真实任务”中表现稳定,部分项目略逊于 Claude 但整体仍领先。
-
④ 长上下文任务保持明显优势
- MRCR needle(8-needle):77.0%(高于 GPT-5.1 的 61.6%) → 展示出成熟的长文本稳定性。
也就是说,除了SWE Bench Verified外,谷歌模型几乎在所有的评测结果上都好于竞争对手。
更重要的是,Google 还强调了交互风格层面的变化: Gemini 3 Pro 的回答更倾向于**“直接给出洞见”**,少一些“客套和奉承”,更像是会跟你讨论问题、讲清楚利弊的“思考伙伴”,而不是只会给出漂亮措辞的聊天机器人。
Gemini 3 Deep Think:进一步强化的推理模式
如果说 Gemini 3 Pro 已经覆盖绝大部分高难度任务,那么 Gemini 3 Deep Think 就是把“极限推理”这个方向往前推了一截。
Gemini 3 Pro Deep Think 本质上是一个增强推理模式:允许模型在复杂问题上花更多“思考步骤”,尤其是在需要抽象模式识别与复杂逻辑链的场景。官方给出了一些对比数据:
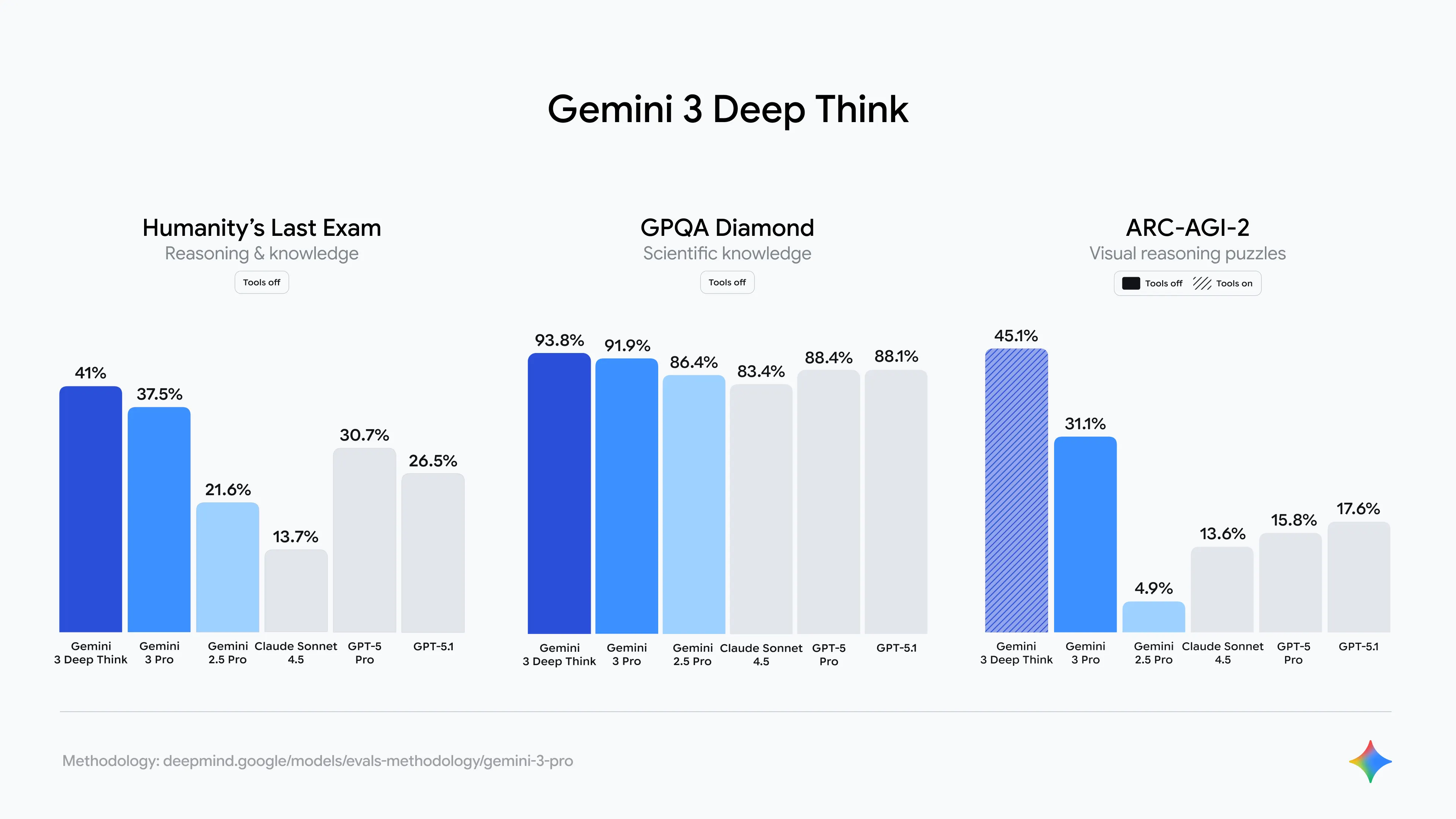
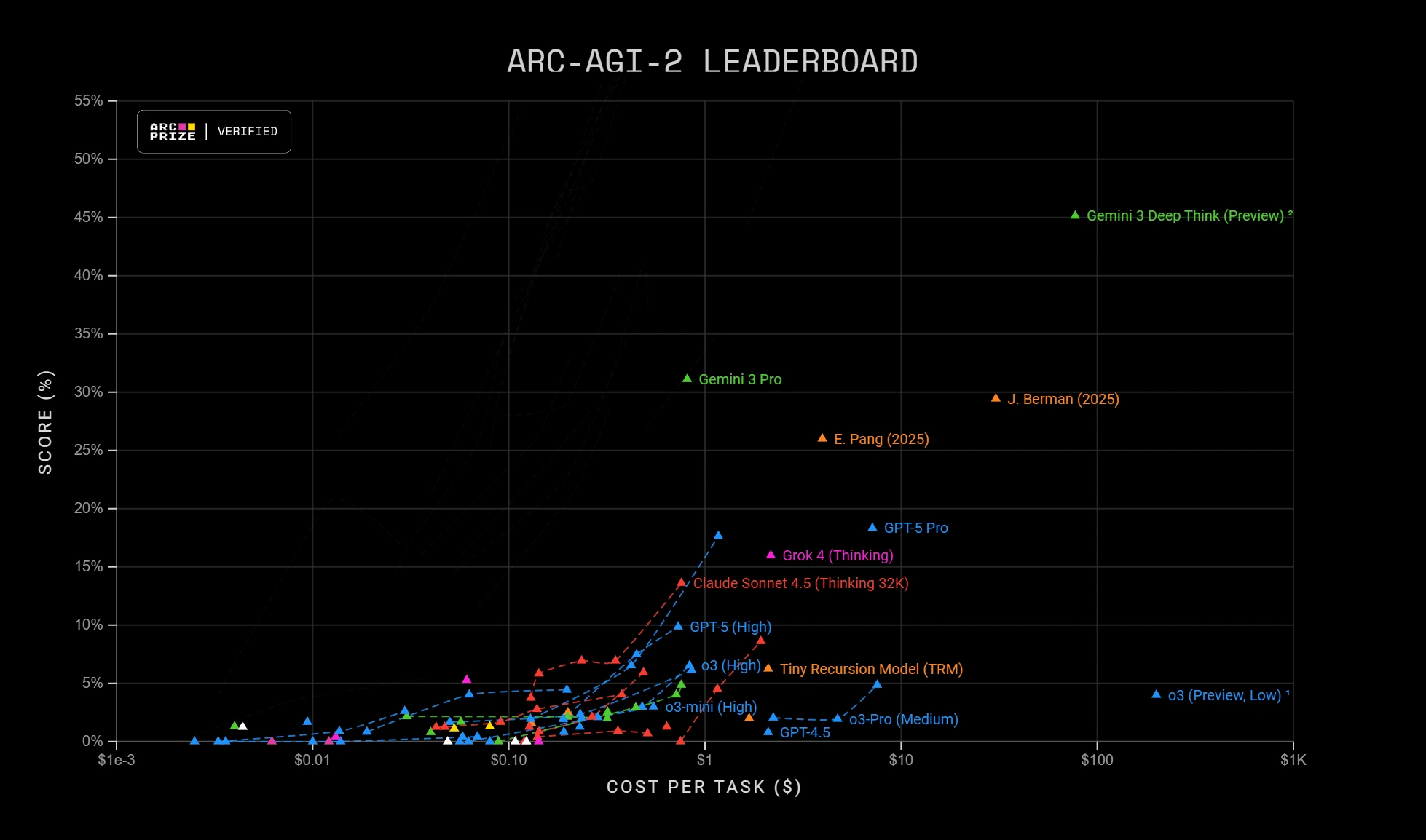
在复杂问题的解决上,Gemini 3.0 Pro的Deep Thinking模式显著提升了效果。特别是看ARC-AGI-2这个测试,其精心设计的视觉逻辑谜题要求 AI 模型在首次接触的情况下,通过分析和推理找到正确答案。此举旨在超越模型在海量数据中学习到的模式记忆,转而评估其真正的理解和解决问题的能力。这是一项非常困难的挑战,截止目前,表现最好都是GPT-5 Pro,但是只有18.3,而Gemini 3.0 Pro用更少的成本就获得了31.1的分数,远超其它模型,深度思考模式下更是获得了45.1分,傲视群雄!
模型之外:Learn / Build / Plan——Gemini 3 打造的新一代智能系统
如果只看评测榜单,Gemini 3.0 Pro 已经是标准意义上的“旗舰模型”;但在这次官方发布里,Google 更想强调的是模型之外的东西——它能让你学什么、能帮你做什么,以及能替你规划什么。
概括来说,就是三个关键词:Learn anything、Build anything、Plan anything,再加上一款全新的 Agent-first 开发平台 Google Antigravity。
在「Learn anything」方面,Gemini 3 利用多模态与 100 万 token 上下文,把传统“问答式”体验升级成一种更接近个人学习助手的形态: 它可以一次性消化手写食谱、论文、长视频和教程,不只是给你一段总结,而是重组为更适合人阅读和记忆的结构——比如家庭菜谱合集、带交互练习的知识卡片、可运行的可视化代码,甚至是基于你上传的视频给出动作分析和训练计划。Search 中的 AI Mode 则进一步把这些能力做成动态 UI,让“解释一个复杂概念”变成一套可交互、可视化的学习界面。
在「Build anything」上,Gemini 3 被官方定义为目前最强的 vibe coding + agentic coding 模型: 你可以用自然语言描述一个 3D 小游戏、数据面板或交互式网页,模型直接产出可运行的原型;更重要的是,它可以围绕一个开发任务进行拆解、调用工具、迭代调试——不再只是“帮你写段代码”,而是逐步接近“帮你把一个想法做完整”。这一能力已经通过 AI Studio、Vertex AI、Gemini CLI 以及 Cursor、GitHub、JetBrains、Replit 等第三方平台落地。
「Plan anything」则对应的是长程规划与 Agent 能力。Gemini 3 在 Vending-Bench 2 这类长周期评测中表现出更稳定的决策与更高的整体收益,说明它不仅能算、还能在一整段“时间轴”上记住自己在做什么。面向普通用户,这体现在 Gemini Agent 上,能帮你处理如整理邮箱、预约服务、执行多步任务等场景;面向开发者,Google 推出了全新的 Google Antigravity:在这个 Agent-first 的开发环境里,模型可以直接操控编辑器、终端和浏览器,完成“规划 → 编码 → 运行 → 验证”的端到端开发流程,同时与 Gemini 2.5 Computer Use、Nano Banana 等模型协同工作。
因此,从系统层面看,Gemini 3.0 Pro 不仅是一个“分数很高的模型”,更是 Google 正式把多模态、长上下文和 Agent 能力整合成一套「学、建、规划」统一体验的起点。十分有野心的目标!
Gemini 3.0 Pro目前可以在AI Studio免费使用
说了这么多,大家其实可以直接去官网体验了。目前AI Studio上面是可以免费使用的,也可以用官方提供的Vibe Coding来创建APP。
我们也做了一个简单的一句话生成Gemini 3.0 Pro官网的模型页面:
可以说,非常精致了!
更多Gemini 3.0 Pro的信息参考DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/gemini-3-0-pro-preview-11-2025
