Anthropic发布Claude Opus 4.8:定价不变,编程与智能体能力小幅提升
2026年5月28日,Anthropic发布了旗舰模型的新版本Claude Opus 4.8。这是一次幅度不大但方向明确的迭代:模型在编程、智能体(agentic)任务、推理和知识工作类基准上全面小幅领先于前代Opus 4.7,定价保持不变,同时把"诚实性"作为本次最被强调的改进点。Anthropic官方在公告中也未回避,直接将其定性为"对前代一次温和但切实的改进(a modest but tangible improvement)"。
值得注意的是迭代节奏。Opus 4.8距离Opus 4.7发布仅41天,是Opus系列至今最快的一次版本更新。模型ID为claude-opus-4-8,提供100万token输入、12.8万token输出的上下文配置。
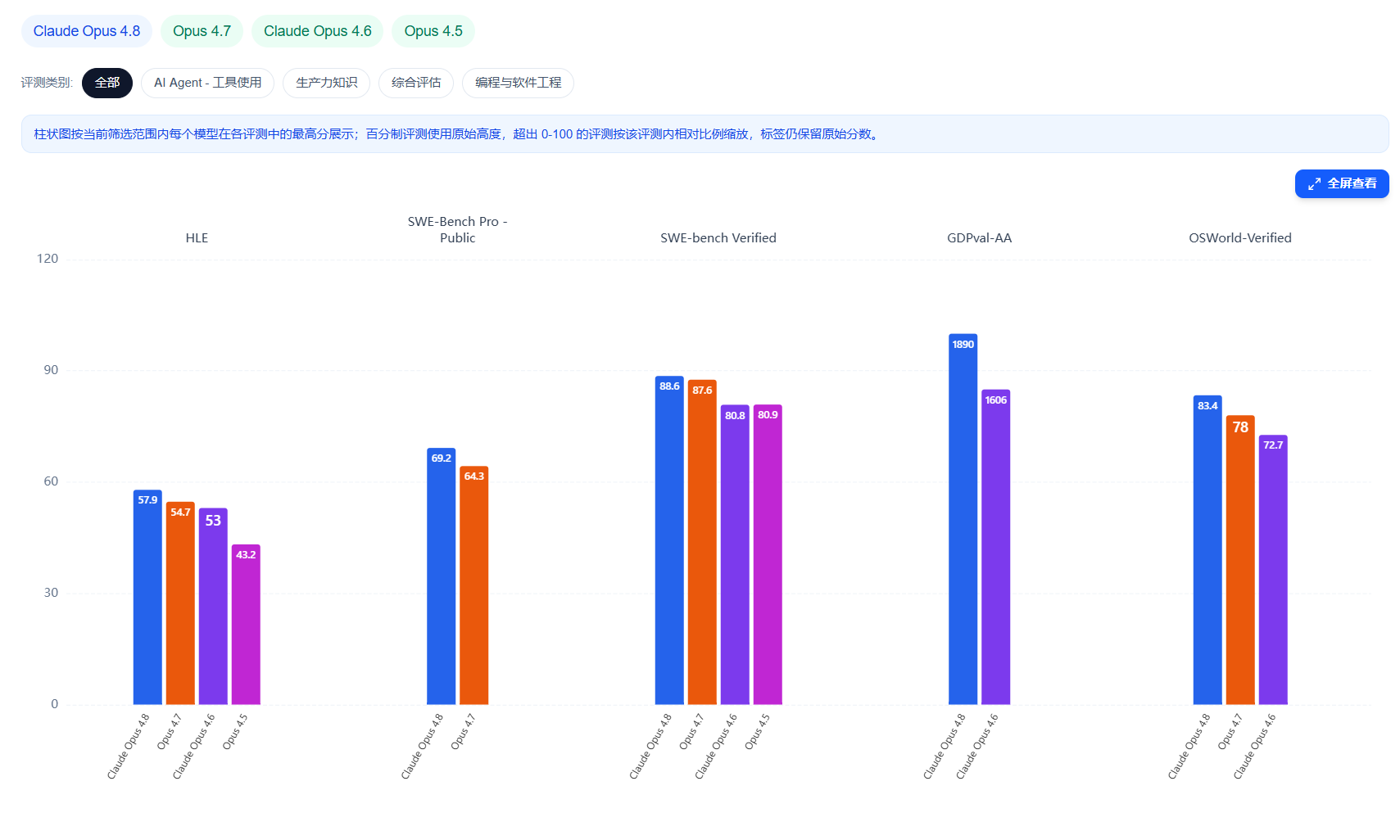
基准测试:编程提升明显,但终端任务仍输给GPT-5.5
从官方System Card公布的数据看,Opus 4.8的提升主要集中在编程和智能体能力上,但不同基准的涨幅差异很大,需要分开看。
编程方面,真正有意义的提升来自更难的SWE-bench Pro:Opus 4.8得分69.2%,较Opus 4.7的64.3%提升4.9个百分点。相比之下,已经接近天花板的SWE-bench Verified只从87.6%涨到88.6%(+1.0),SWE-bench Multilingual从80.5%升至84.4%(+3.9)。换句话说,在已经饱和的基准上几乎没有空间,提升集中在尚未饱和的更难任务上——这恰恰是判断模型实际编程能力是否进步的更可靠信号。
智能体终端任务(Terminal-Bench 2.1)是本次单项涨幅最大的一项,从66.1%提升到74.6%,足足提高了8.5个百分点。但这里必须如实说明:即便涨幅最大,Opus 4.8在这一项上仍然输给GPT-5.5。在同一套Terminus-2公开harness下,GPT-5.5得分78.2%;若使用GPT-5.5自带的Codex CLI harness,其分数更高达83.4%。Anthropic在脚注中也承认了这一点。结论很直接:如果你的工作主要在终端/CLI环境中进行,当前综合最强的模型并不等于最适合你的模型。
推理类基准的表现则呈现两极。最夸张的是USAMO 2026数学证明,从69.3%直接跃升至96.7%,单个版本周期提升27.4个百分点——这种幅度已经不是渐进式打磨,而更像是数学推理深度发生了质变。但与此同时,GPQA Diamond出现了轻微回退,从Opus 4.7的94.2%下降到93.6%。Humanity's Last Exam(带工具)从54.7%升至57.9%。
知识工作方面,Artificial Analysis的GDPval-AA评测中,Opus 4.8以1890 Elo领先,较前代1753提升137分,并明显高于GPT-5.5的1769。计算机使用(OSWorld-Verified)得分83.4%,浏览器智能体(Online-Mind2Web)达84%。综合来看,Opus 4.8在Anthropic公布的对比中7项里赢下6项,唯一输掉的就是上面提到的Terminal-Bench 2.1。
"诚实性"是本次更新被反复强调的卖点
如果说基准数字是温和提升,那么Anthropic在公告里花了最多笔墨的,其实是模型的"诚实性(honesty)"。
这里的"诚实"有明确定义:指模型避免做出自己无法支撑的断言。AI模型的一个普遍问题是,会在证据不足的情况下贸然下结论,自信地宣称任务已经完成或取得进展。Anthropic称,Opus 4.8更倾向于主动标注自己工作中的不确定性,更少给出没有依据的结论。
落到可量化的指标上:Opus 4.8在自己写的代码中,让缺陷不加标注地"蒙混过关"的概率,大约只有前代的四分之一(约低4倍)。 多位早期测试者的反馈也指向同一点——模型会主动指出输入和输出中的问题,而这正是其它模型经常遗漏、留给用户自己去发现的环节。
对于把模型用于代码审查、金融分析、法律等高风险专业工作流的用户,这一改进的实际价值可能高于任何单项基准分数的提升。 一个会说"这里我不确定"的模型,在长周期、无人值守的agentic工作流里,比一个分数更高但会自信犯错的模型更可用。
对齐评估:负面行为率接近Mythos水平
在发布前的对齐评估中,Anthropic的对齐团队给出的结论是:Opus 4.8"在支持用户自主性、以用户最佳利益行事等亲社会特质(prosocial traits)的测量上达到了新高"。
更关键的一组数据是:Opus 4.8的失准行为率(如欺骗、配合滥用)显著低于Opus 4.7,并已接近Anthropic对齐表现最好的模型Claude Mythos Preview的水平。 完整的对齐评估与一系列部署前安全测试都收录在Opus 4.8 System Card中。
同步发布的三项功能更新
除了模型本身,Anthropic在同一天还推出了三项配套更新,其中两项针对的是Opus 4.7时期用户反馈较多的"思考时间过长"问题。
第一项是Effort Control(投入度控制),在claude.ai和Cowork的模型选择器旁新增。用户可以手动选择Claude在一个任务上投入的算力与token量。Opus 4.8默认采用"高(high)"投入度——在编程任务上花费的token与Opus 4.7默认档相近,但表现更好;用户还可以选择"extra"(在Claude Code中对应xhigh)或"max"档,让模型花更多token换取更好结果。Anthropic建议在困难任务和长时间异步工作流上使用"extra"档,并相应提高了Claude Code的速率限制。
第二项是Dynamic Workflows(动态工作流),目前为研究预览,面向Claude Code的Enterprise、Team和Max套餐。它允许Claude先规划任务,再在单个会话中并行运行数百个子智能体(subagents),最后在汇报前自行验证输出。官方给出的标志性场景是:Claude Code配合Opus 4.8,可以从启动到合并,完成跨越数十万行代码的代码库级迁移,并以现有测试套件作为验收标准。
第三项面向开发者:Messages API现在允许在messages数组内部插入system条目。这意味着开发者可以在任务进行中更新Claude的指令——例如调整权限、token预算或环境上下文——而无需打断prompt缓存,也不必把更新伪装成一轮用户输入。
定价与可用性:维持不变,fast模式便宜3倍
Opus 4.8即日起全平台可用。常规使用定价与Opus 4.7完全一致:每百万输入token 5美元,每百万输出token 25美元。 开发者可通过Claude API以claude-opus-4-8调用。
变化在fast模式:该模式以约2.5倍速度运行,定价为每百万输入/输出token 10/50美元(即常规价的两倍),但相比上代Claude模型的fast模式,单位价格便宜了3倍。这一调整与近期整个行业"在能力提升的同时压低单位推理成本"的方向一致,对成本敏感的高频调用场景影响较大。
还有什么值得关注:Mythos级模型即将面向所有客户
Anthropic在公告中再次预告了下一步:计划发布一类智能水平高于Opus的全新模型。作为Project Glasswing的一部分,目前已有少数机构在用Claude Mythos Preview做网络安全相关工作。由于这一能力级别的模型需要更强的网络安全防护措施才能广泛发布,Anthropic称正在快速推进相关防护,预计将在"未来几周内"把Mythos级模型带给所有客户。
需要提醒的是,目前公开可用的最强模型仍是Opus 4.8,Mythos级模型尚未普遍开放,其实际能力与发布时间仍有不确定性。
结论
Claude Opus 4.8是一次定位清晰的"巩固型"更新,而非颠覆性升级。 它在保持定价不变的前提下,把编程(尤其是更难的SWE-bench Pro)、智能体终端任务和知识工作能力全面向上推了一档,并在数学推理上出现了USAMO 2026这种异常大的单项跃升。
但它的真正差异化,不在某个基准数字,而在两个相对"软"的维度上:一是"诚实性"——更少自信地犯错、更主动地暴露不确定性;二是对齐表现——失准行为率已逼近Mythos水平。 对追求绝对终端编程性能的用户,GPT-5.5在Terminal-Bench 2.1上仍有优势;但对需要长周期、可托付、低风险地交出真实工作量的专业工作流而言,Opus 4.8的可靠性提升可能比分数本身更有意义。
考虑到它距Opus 4.7仅41天发布、且Anthropic已明确预告Mythos级模型即将到来,Opus 4.8更像是正式发布前夜的一次稳健过渡。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
