MetaAI发布语音识别错误率是OpenAI的Whisper模型的一半且支持1107种语言的ASR模型:MMS
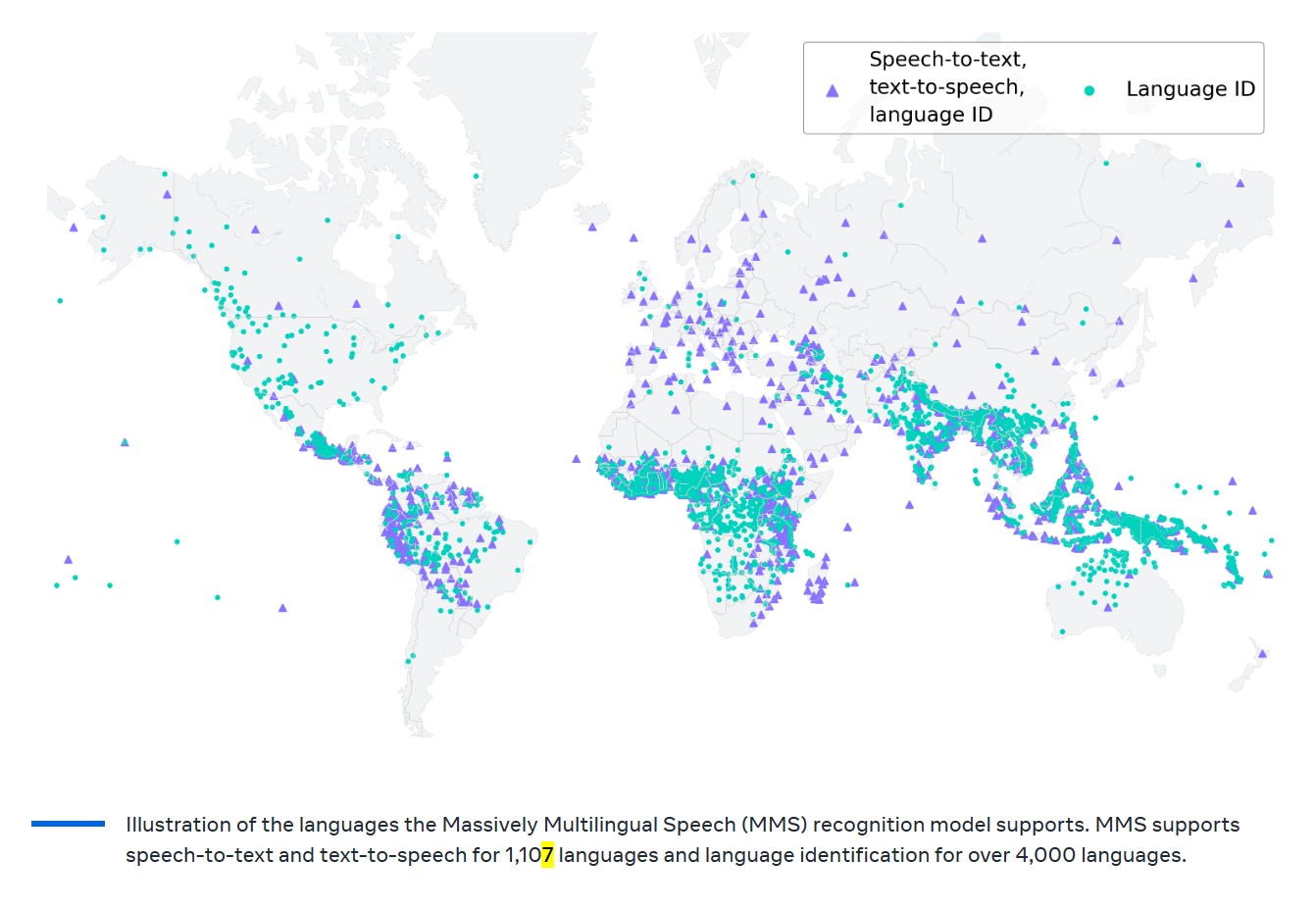
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~
汇总「语言识别」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~