连续变量离散化(Scala版本)
这段代码是Spark MLLib中决策树算法中的代码片段,是将连续的变量离散化。输入参数为:
1、featureSamples:在原始版本中,某一个特征下的数据可能很多,为了避免对过多的数据进行离散化导致速度上太慢,于是对于大于10000条数据的特征进行了抽样,这里就是抽样结果的数据,是一个double类型的数组 2、metadata:元数据,就是描述特征情况的,包括是离散的还是抽样的等 3、featureIndex:特征索引,表明是第几个特征
大致思路如下: 首先需要统计出不同变量值的个数,以及总的不同特征值的数量。假设总共有N个不同的值,那么一般情况下是将N个不同的值按照从小到大排序好,总共需要N-1个点将其分开(例如将1.2、2.3、3.2切分成三个区间,只需要1.75和2.75两个数字即可,结果为$(\infty,1.75]$、$(1.75,2.75]$、$(2.75,\infty]$)。
但是在此之前已经给该特征设置了划分的区间数,当期望分割数大于不重复数据点数量,那么直接按照不同变量个数来分即可。如果期望分割的区间数小于这个值,那么按照期望分割的数量来切分。其切分逻辑如下图所示:
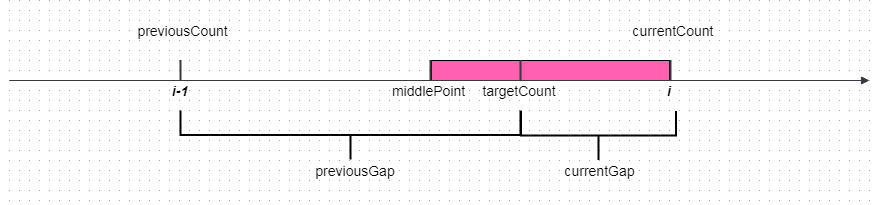
i-1是上一个数据点的值,如1.2,previousCount表明到第i-1这个值为止的数据点总数(假设1.2这个数据点有4个,那么previousCount=4)。i是当前数据点(例如之前的2.3),currentCount是previousCount+count(i)的结果(假设2.3数据有3个,那么currentCount=7)。middlePoint是二者中间的位置(即1.75)。targetCount是我们离散化数据点的分割点,这个值是用数据点总数除以(期望分割数+1)得到的(也就是下面代码中的stride)。其中:
