Baichuan系列大语言模型升级到第二代,百川开源的Baichuan2系列大模型详解,能力提升明显,依然免费商用授权
3,433 views
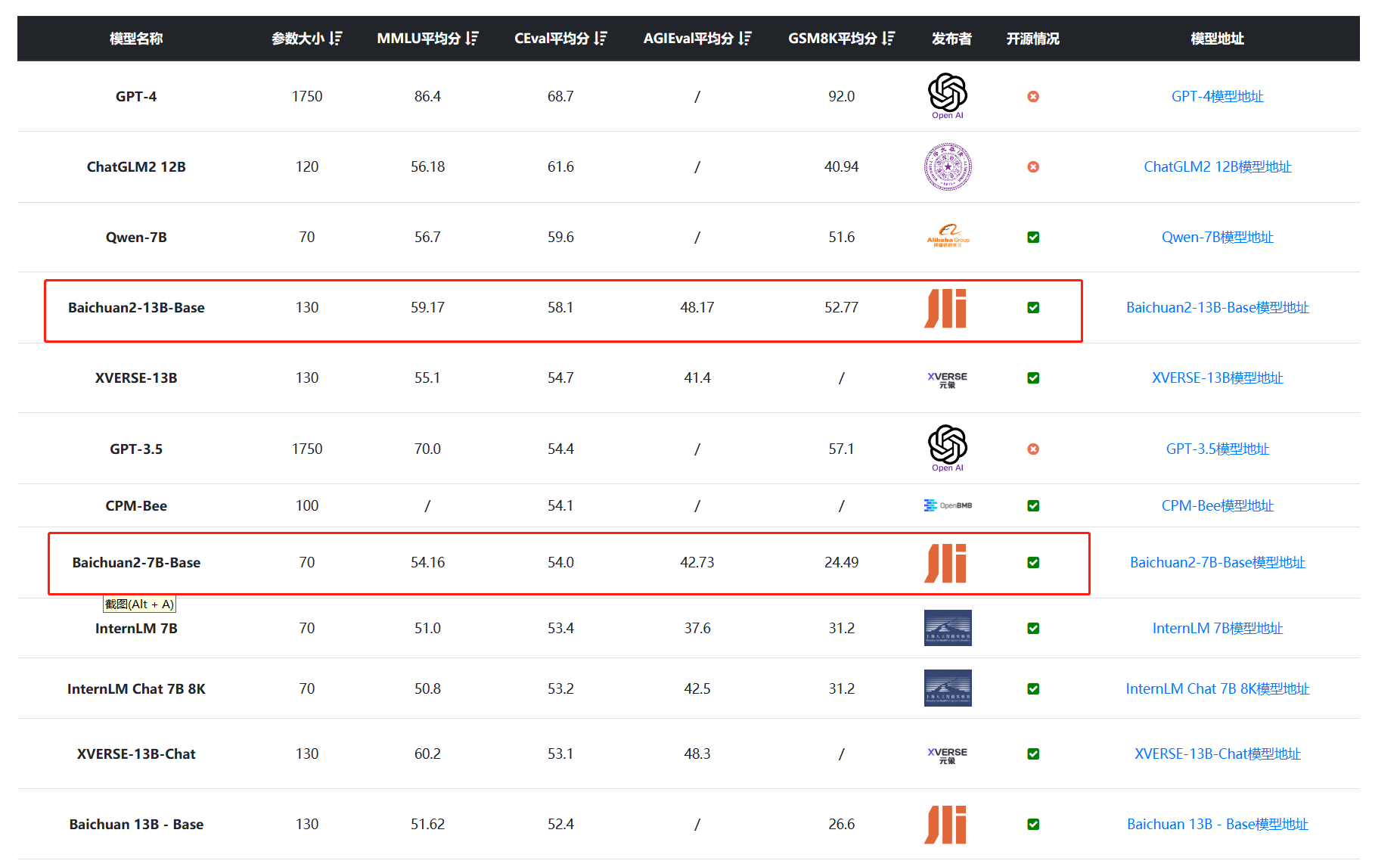
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。
Baichuan2系列模型在各项评测中提升明显: