MATH vs. MATH-500:数学推理评测基准的对比与解析
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。
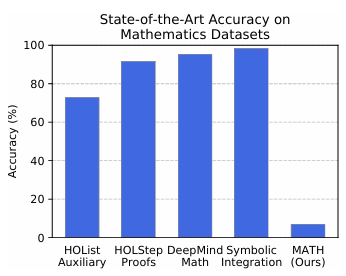
Math与MATH-500
MATH基准测试由亨利·托马斯(Henry Thomas)等人于2021年发布,旨在提供一个涵盖广泛数学主题和难度的评测数据集,以全面评估LLM在数学问题上的表现。
MATH-500基准测试由OpenAI于2023年推出,作为评估其最新模型(如GPT-4o)数学能力的工具。该基准测试包含500道高难度的数学竞赛题目,旨在挑战模型的极限,评估其在复杂数学问题上的推理和解题能力。
评测目标:
MATH的目标是测试模型在各个数学领域和难度级别上的通用解题能力,包括代数、几何、概率等。
MATH-500则专注于高难度竞赛级别问题,评估模型在面对复杂、多步骤推理问题时的表现,特别关注模型在高级数学推理和创新解题策略方面的能力。
对比结果:
在MATH基准测试中,GPT-4o模型取得了76.6%的准确率,展示了其在广泛数学问题上的强大解题能力。
而在MATH-500基准测试中,GPT-4o的准确率为94.8%,表明其在高难度数学竞赛问题上的卓越表现。
这反映出MATH-500基准测试对模型的挑战性更高,能够更有效地评估模型在复杂数学推理任务中的能力。
总结:
MATH和MATH-500基准测试各有侧重,前者涵盖广泛的数学主题和难度,用于评估模型的通用数学解题能力;后者聚焦于高难度的竞赛题目,旨在测试模型在复杂推理和高级解题策略方面的表现。对于研究者和开发者而言,选择合适的基准测试应根据评估目标和模型的预期应用场景来确定。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
