SWE-bench Verified:提升 AI 模型在软件工程任务评估中的可靠性
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 SWE-bench Verified 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
SWE-bench Verified 是对原始 SWE-bench 测试集的优化版本,它通过人工验证和改进,解决了原测试集中存在的一些关键问题。这一新的测试集不仅提升了评估的准确性,也为 AI 评估体系的透明性和可靠性注入了新的动力。
大模型在SWE-Bench Verified排行榜的得分可以参考DataLearnerAI的网站:https://www.datalearner.com/benchmarks/swe-bench%20verified
1. 背景:SWE-bench 的局限性
SWE-bench 是一个广泛使用的基准,旨在评估 AI 模型在解决现实世界的 GitHub 编程问题中的表现。它要求模型根据给定的代码库和问题描述生成修复补丁,并通过相关的单元测试来验证修复的有效性。然而,在实践中,研究人员发现一些问题导致 SWE-bench 无法准确反映模型的实际能力:
- 问题描述不明确: 某些任务的描述存在歧义,难以理解问题的真正需求。
- 测试过于狭窄或无关: 部分单元测试过于具体,甚至与原始问题无关,导致模型即使给出正确解决方案,也可能被错误地判定为失败。
- 开发环境难以复现: 设置复杂的开发环境可能导致模型提交的解决方案被误判为无效。
这些问题使得原有的 SWE-bench 基准在评估模型时存在较大不确定性,影响了对 AI 模型能力的真实评价。
2. SWE-bench Verified:改进与创新
为了解决上述问题,OpenAI 推出了 SWE-bench Verified,这一更新版本的核心在于通过人工验证筛选测试集中的样本,确保每个问题的描述清晰、单元测试准确,且开发环境易于复现。
主要改进点包括:
-
人工标注和筛选: OpenAI 与 93 位经验丰富的 Python 开发者合作,手动审查和标注了 1,699 个随机样本,从中筛选出 500 个经验证的高质量问题。这一过程确保了每个问题描述清晰,且与解决方案相关的单元测试不会误导模型的解决方案。
-
优化的评估环境: 采用了容器化的 Docker 环境,使得评估过程更加标准化,减少了因环境配置问题导致的测试失败。
-
透明的标注和评估方法: 所有样本的标注数据都公开发布,确保外部研究者可以了解每个问题的处理过程,并在后续的研究中能够复现结果。
3. 实际表现:AI 模型的进步
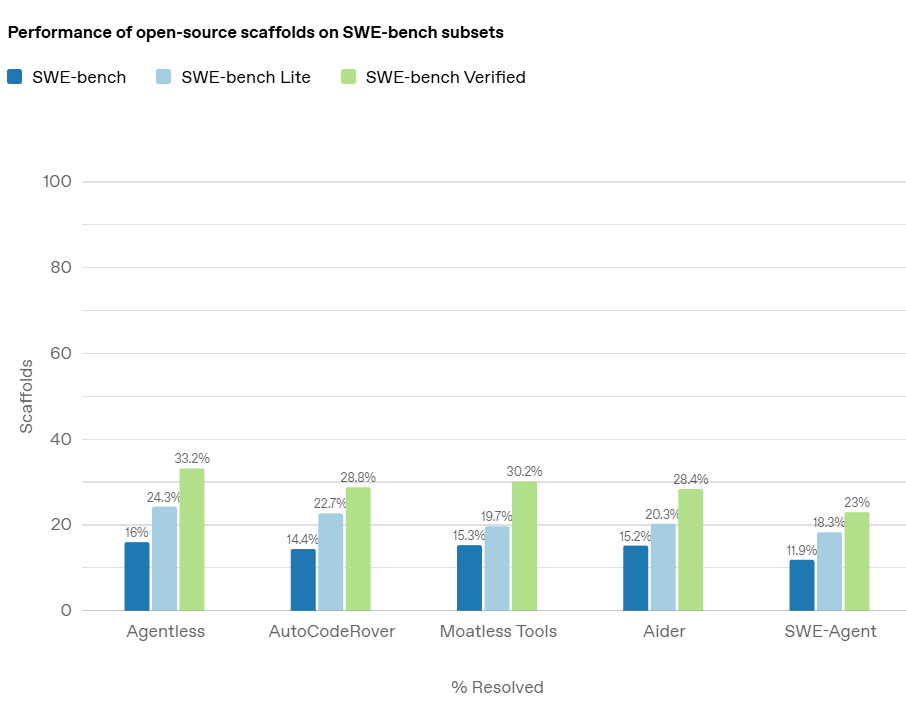
在新的 SWE-bench Verified 上,AI 模型的表现有了显著提升。例如,GPT-4o 在该基准上的成功率达到了 33.2%,相比原有测试集的成绩有了明显提高。这一进展不仅展示了模型在更清晰、更可靠评估下的进步,也说明了改进后的评估方法能够更真实地反映模型的能力。
此外,开源框架 Agentless 的表现也有了突破,其得分从 16% 翻倍至 33%,证明了更高质量的评估集能够为模型提供更准确的训练反馈,进而推动模型能力的提升。
4. 专业分析:SWE-bench Verified 的意义
从专业角度来看,SWE-bench Verified 代表了 AI 在软件工程领域评估方法的一次重要革新。通过人工验证和环境优化,这一版本不仅提升了测试的质量和可靠性,还解决了许多长久以来影响评估准确性的隐性问题。
几个关键的分析点:
-
提高评估精度: 通过人工筛选和验证,确保每个测试样本都与模型需要解决的真实问题相符,减少了不必要的错误判定和测试偏差。这使得 SWE-bench Verified 成为一个更为真实反映模型能力的工具。
-
透明度与复现性: 所有标注和评估过程的公开,提升了基准测试的透明度和学术界的信任度。研究者不仅可以看到每个问题的详细标注,还能够更容易地复现结果。
-
模型优化的反馈机制: 更准确的评估意味着模型在训练过程中能够获得更有效的反馈,从而推动其能力的提升。AI 模型在更加可靠的测试环境中获得评估后,能更好地识别自身的优劣势,改进其解决方案。
5. 结论:更为可靠的 AI 能力评估工具
总体而言,SWE-bench Verified 在提升 AI 模型在软件工程领域表现评估的准确性和可靠性方面,迈出了重要的一步。它不仅优化了测试集质量,还通过改进测试环境和透明的评估方法,为未来的 AI 评估提供了一个新的标准。对于 AI 开发者、研究人员以及行业从业者来说,这一进展无疑为推动 AI 在自动化软件开发中的应用奠定了更加坚实的基础。
通过 SWE-bench Verified,我们可以期待在更高质量的基准测试指导下,AI 模型的性能将会更加接近现实世界的需求,推动软件工程领域向着更加智能化和自动化的方向迈进。
