大模型评测基准AIME 2024介绍
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。
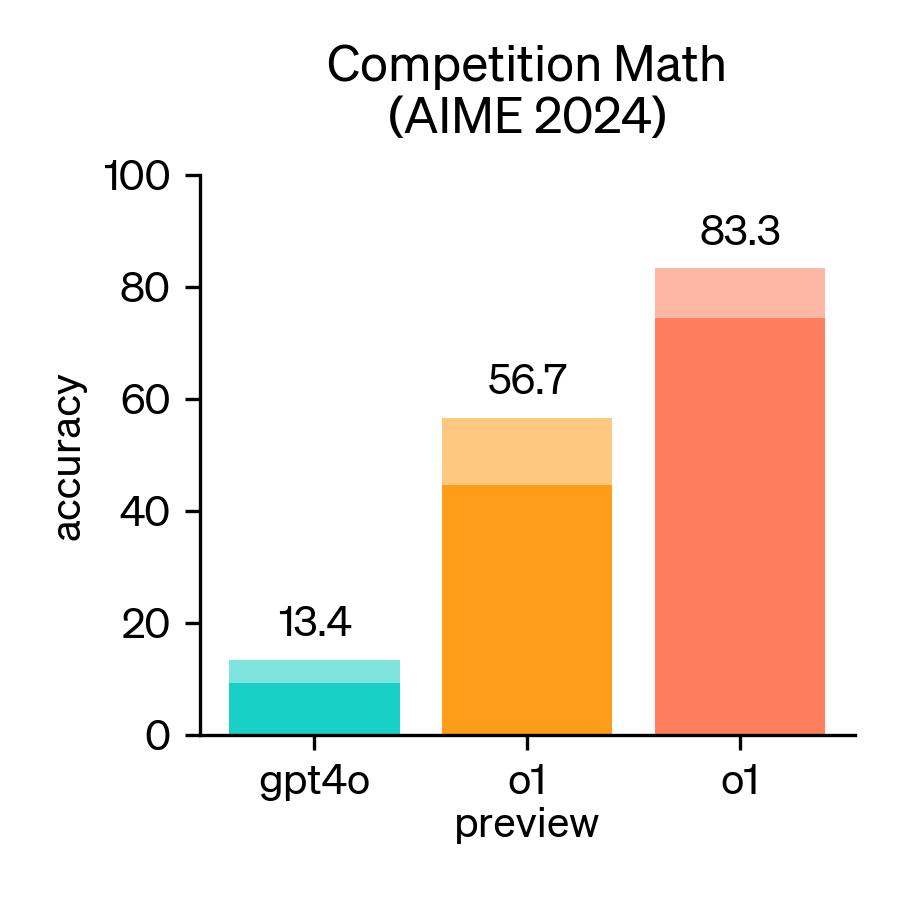
当前全球主流大模型在AIME 2024上的得分和评论参考DataLearnerAI的AIME2024排行榜数据:https://www.datalearner.com/ai-models/llm-benchmark-tests/37
AIME 2025的得分排行榜也出来了,更加具有参考性,大模型在AIME2025得分可以参考DataLearnerAI数据:https://www.datalearner.com/benchmarks/aime-2025
使用AIME 2024评估LLM
研究人员和开发者利用AIME 2024的问题来评估和提升LLM在数学推理方面的表现。例如,一个包含2024年AIME问题的数据集已被公开,用于测试LLM在应对这些高难度问题时的解题能力。
主要模型的表现
多款先进的LLM在AIME 2024基准上进行了测试:
-
DeepSeek-R1:这款开源推理模型在AIME 2024中取得了79.8%的成绩,展示了其在处理高级多步骤数学问题上的强大能力。
-
OpenAI的o1-1217:该模型在同一基准上获得了79.2%的成绩,显示出与DeepSeek-R1相当的数学推理能力。
模型评估协议的进展
AIME 2024的评估还推动了创新的AI系统优化协议的发展。其中之一是通过多个LLM评估者进行AI系统优化的方法(AIME),该方法让多个LLM独立评估生成输出的不同标准。在代码生成等任务中,这种方法提高了错误检测率,比单一LLM评估协议高出62%。
意义与未来方向
将AIME 2024作为基准,强调了在开发LLM过程中进行严格评估的重要性,特别是在复杂的数学推理领域。从这些评估中获得的见解对于指导未来的研究和开发至关重要,旨在增强AI系统在数学环境中的问题解决能力和可靠性。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
