MMMU基准:多模态多学科复杂推理能力的权威评估体系
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
什么是MMMU基准?
MMMU(Massive Multi-discipline Multimodal Understanding and Reasoning)是首个以大学水平学科知识为基础构建的多模态评测基准,旨在系统评估模型在跨学科、多模态场景下的复杂推理能力与专业知识应用水平。
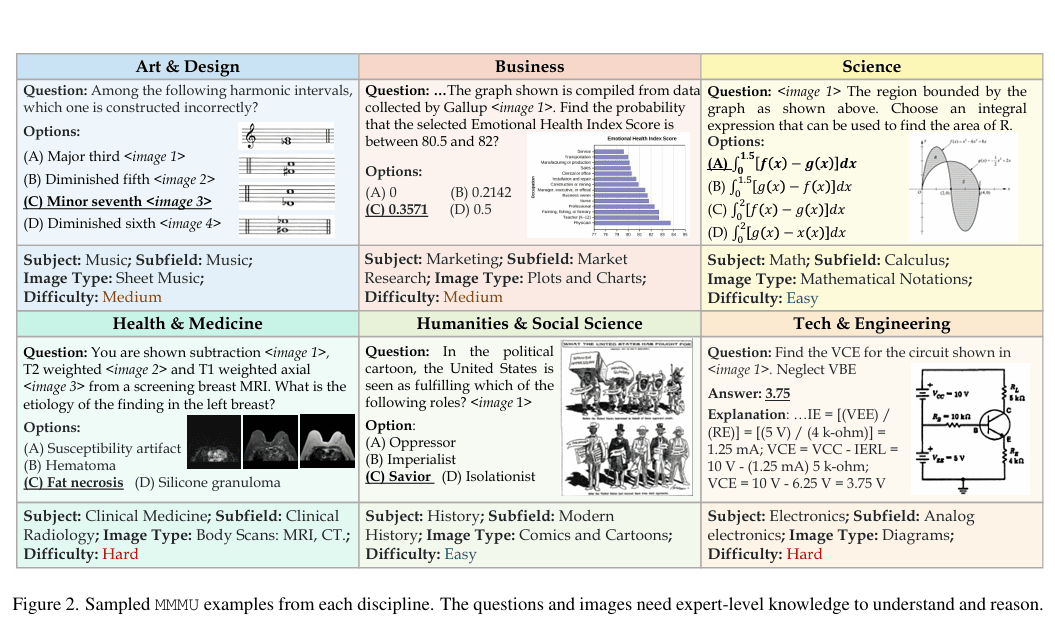
MMMU包含来自大学考试、测验和教材的11,500个多模态问题。这些问题涵盖六个核心学科:艺术与设计、商业、科学、健康与医学、人文与社会科学以及技术与工程。在这些学科中,基准覆盖了30个科目和183个子领域。它包含30种不同的图像类型,包括图表、示意图、地图、表格、乐谱和化学结构,要求模型有效处理文本和视觉输入。
该基准测试模型的感知和推理技能,问题设计需要专家级知识。例如,任务可能涉及分析化学结构或解读历史地图,需要深入的背景理解。这种结构使MMMU区别于早期基准,模拟了人类专家面临的现实世界挑战。
MMMU的重要性
MMMU解决了之前基准的局限性,例如大规模多任务语言理解(MMLU),后者主要关注基于文本的通用知识。通过整合多模态复杂性和大学水平学科内容,MMMU提供了对AI能力的更全面评估。其对多样化图像类型和特定领域推理的强调,为模型优缺点提供了洞察,指导研究改进多模态系统。这一重点与开发能够执行专业化、跨学科任务的AGI的更广泛目标一致。
主要LLM在MMMU上的表现
在零样本设置下,多个大语言模型已在MMMU上进行测试,无需微调或演示。这些结果反映了多模态AI的当前状态,并突显了改进空间。
- GPT-4V:由OpenAI开发的GPT-4V,准确率为56%。这一分数表明,尽管该模型在语言任务上表现出色,但在处理复杂视觉感知和特定领域推理方面仍面临挑战。
- Claude 3.5 Sonnet:Anthropic的Claude 3.5 Sonnet以68.3的最高分表现优异,跨多个学科表现突出。然而,其仍低于人类专家的表现,人类专家的得分范围为76.2%至88.6%。
- Gemini 1.5 Pro:谷歌的Gemini 1.5 Pro得分为62.2,优于早期版本如Gemini Ultra(59.4%),显示了多模态能力的进步。
- Llama 3.2 Multimodal:Meta的Llama 3.2 Multimodal(90亿参数)得分为60.3,优于较小的模型如Claude Haiku(50.2)和GPT-4o mini(59.4),展示了大规模开源系统的潜力。
这些结果表明,尽管取得了进步,但即使是表现最佳的模型也未达到人类专家标准,特别是在需要整合多模态理解的任务上。
对多模态AI和AGI的影响
MMMU的性能数据揭示了当前多模态模型与专家级熟练度之间的差距。56%至68.3%的得分表明,在视觉解读和专业知识应用等领域需要进一步发展。通过使用特定领域内容增强训练数据集,可以解决这些不足,提高模型在专家任务上的准确性。 MMMU对整合文本和视觉信息的关注反映了人类认知过程,使其成为衡量AGI进展的重要指标。随着模型在该基准上的改进,它们将更好地处理复杂的现实世界场景,推动多模态AI领域的发展。
结论
MMMU基准标志着评估多模态模型的重要一步,提供了对跨学科感知和推理的严格测试。其全面的设计和具有挑战性的任务清晰地展示了当前AI能力和局限性。随着主要LLM的不断发展,MMMU将继续是跟踪朝专家级AGI进展的关键工具,塑造人工智能研究和发展的未来。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
