大模型多模态评测基准MMMU介绍
1,239 阅读
大模型多模态评测基准MMMU(大规模多学科多模态理解和推理基准)是一项旨在评估多模态人工智能模型在复杂跨学科任务中综合能力的测试工具。
1. 设计背景与目标
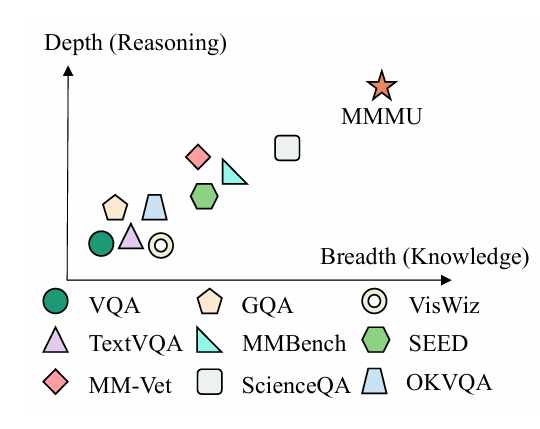
MMMU的提出源于现有多模态基准(如VQA、OK-VQA等)的局限性,这些基准往往局限于常识性任务或单一学科,难以评估模型对专业领域知识和深度推理的能力。MMMU的目标是模拟大学水平的跨学科考试场景,要求模型具备人类专家级的图文理解和推理能力,从而推动多模态模型向更接近通用人工智能(AGI)的方向发展。
2. 核心原理与结构
数据集构成
- 覆盖领域:涵盖六大核心学科(艺术与设计、商科、科学、健康与医学、人文与社会科学、技术与工程),细分30个科目和183个子领域,例如物理学中的电磁学、化学中的有机合成等。
- 问题类型:包含1.15万个多模态问题,每个问题均以图文混合形式呈现,例如图表、化学结构图、地图等30种图像类型,并搭配文本描述或问题选项。问题来源包括大学考试题、教科书及专业测验。
- 输入模式:支持文本与图像混合输入,部分问题需同时解析图像中的视觉信息和文本内容才能正确回答,例如通过图表推导物理定律或通过分子结构图判断化学反应路径。
评测维度
- 感知能力:要求模型从图像中提取关键信息(如识别图表中的趋势、分子结构中的官能团)。
- 知识运用:结合学科专业知识(如医学诊断标准、工程学原理)进行推理。
- 复杂推理:涉及多步骤逻辑推导,例如数学证明或基于历史事件的社会学分析。
增强版MMMU-Pro
为进一步提升评测的鲁棒性,MMMU-Pro通过三步改进原版:
- 过滤纯文本可回答问题:确保问题必须依赖图像信息才能解答。
- 增加候选选项至10个:降低模型通过猜测答对的概率。
- 引入纯视觉输入设置:将问题直接嵌入图像中,要求模型同时“阅读”图像内文本并理解视觉内容,模拟现实场景(如处理屏幕截图)。
3. 评测结果与分析
- 模型表现:在MMMU原版测试中,顶级模型如GPT-4V的准确率仅为55.7%,而人类专家的预期表现接近90%。在MMMU-Pro中,模型性能进一步下降(如GPT-4o准确率下降10.7%),表明新基准对模型真实能力的考察更为严格。
- 关键挑战:
- 视觉与文本整合:模型在处理纯视觉输入时性能显著下降,例如LLaVA-OneVision-72B在视觉设置下准确率下降14%。
- 抗干扰能力:增加选项后,模型需更深入理解问题而非依赖统计模式,例如GPT-4o在10选项设置下准确率降至54%。
- 思维链(CoT)的作用:引入CoT提示可提升部分模型性能(如Claude 3.5 Sonnet提升12.3%),但效果因模型而异,部分模型因指令遵循能力不足反而表现更差。
4. 影响与意义
- 推动技术发展:MMMU暴露了现有模型在专业领域和复杂推理中的短板,激励研究者改进视觉编码器、跨模态对齐机制及推理架构。
- 标准化评测工具:MMMU已成为多模态模型的主流评测基准,被GPT-4o、Gemini等顶级模型采用,并为后续研究(如DocPedia高分辨率文档理解模型)提供参考。
- 促进AGI研究:通过模拟人类专家级的跨学科认知,MMMU为评估通用人工智能提供了更接近现实的测试环境,推动了多模态模型向深层次理解和应用场景的扩展。
5. 相关资源
- 论文与数据:原版MMMU论文发布于arXiv:2311.16502,数据集可通过Hugging Face获取。
- 扩展研究:MMMU-Pro的构建方法详见arXiv:2409.02813。
MMMU及其增强版通过高难度、多学科和多模态的设计,为人工智能在多模态理解和推理领域的发展设立了新的标杆,同时也为实际应用(如教育、医疗诊断)提供了技术验证平台。
