MiniMaxAI开源全球推理长度最长的推理大模型MiniMax-M1:100万tokens输入,最高支持80K的推理长度
MiniMaxAI于2025年6月17日正式发布了其新一代大模型——MiniMax-M1。MiniMax-M1的核心亮点在于结合了混合专家(MoE)架构和创新的闪电注意力(Lightning Attention)机制。MiniMax-M1不仅原生支持高达100万Token的上下文长度,推理的tokens也支持最高80K,是当前支持的最多推理长度的大模型。此外,MiniMax-M1在计算效率上也很高,例如在生成10万Token时,其FLOPs消耗仅为DeepSeek R1的25%!

MiniMax-M1模型特点与核心创新
MiniMax-M1是一个混合专家架构(Mixture of Experts,MoE)模型,它基于其前代模型MiniMax-Text-01(包含4560亿总参数,每Token激活459亿参数)训练得到,模型首先在MiniMax-Text-01的基础上,使用了额外7.5T Token进行持续预训练,数据优化了质量和混合比例,其中STEM、代码、书籍和推理相关数据占比提升至70%。长上下文训练从32K逐步扩展到1M Token,以避免梯度爆炸。 之后,通过监督微调(SFT)注入期望的行为模式(如基于反思的思维链CoT),为后续RL阶段打下坚实基础。SFT数据覆盖数学、编码、STEM、写作等领域,其中数学和编码样本约占60%。
MiniMax-M1主要特点如下:
- 混合专家架构 (MoE): M1采用了混合专家架构,总参数量达到4560亿,每个Token激活45.9亿参数,并设有32个专家。
- 闪电注意力机制 (Lightning Attention): 这是M1的核心创新之一,通过该机制,模型在测试时计算(test-time compute)的扩展效率得到显著提升。
- 超长上下文支持: M1原生支持高达100万Token的上下文长度,是DeepSeek R1(128K)的8倍,远超当前其他主流开源模型。
- 卓越的计算效率: 得益于闪电注意力,M1在长序列生成时展现出极高的计算效率。例如,与DeepSeek R1相比,在生成长度为10万Token时,M1消耗的FLOPs(浮点运算次数)仅为其25%。
- 强大的推理能力: M1通过大规模强化学习(RL)进行训练,训练数据涵盖从传统数学推理到基于沙盒的真实世界软件工程环境等多样化问题。
- 创新的强化学习算法CISPO: 为进一步提升RL效率,MiniMaxAI提出了CISPO算法,该算法通过裁剪重要性采样权重而非Token更新,表现优于其他竞争性RL变体。
- 高效的训练成本: 结合混合注意力和CISPO算法,MiniMax-M1的完整RL训练仅用512块H800 GPU,在短短三周内完成,租赁成本仅为53.47万美元。
MiniMax-M1最大的特点是推理长度达到80K
MiniMaxAI发布了两个版本的MiniMax-M1模型,分别具有40K和80K的“思考预算”(即最大生成长度)。这个两个版本差别不大,80K版本似乎评测结果中也不是很明显的优势。
注意,这里的推理长度不是模型的最大输出长度,而是<think></think>标签之间的长度。
与业界其他模型相比,MiniMax-M1是开源的最长推理长度的模型,在闭源模型中,也是仅次于OpenAI o3模型水平。
MiniMax-M1的闪电注意力 (Lightning Attention) 让其推理成本更低
大型推理模型(LRMs)的成功主要归功于测试时计算的新扩展维度——在生成过程中为扩展推理过程投入更多FLOPs,模型性能会持续提升。然而,传统Transformer架构中Softmax注意力的二次计算复杂度限制了推理过程的持续扩展。
MiniMax-M1引入的闪电注意力(Lightning Attention)(Qin et al., 2024b)是一种I/O感知的线性注意力变体实现(Qin et al., 2022a)。在M1的注意力设计中,每七个采用闪电注意力的Transnormer模块之后,会跟随一个采用标准Softmax注意力的Transformer模块。这种混合设计理论上使得推理长度能够高效扩展至数十万Token。

如下方图表所示(图1 右),与DeepSeek R1相比,M1在生成长度为64K Token时消耗的FLOPs不到50%,在100K Token长度时约为25%。这种计算成本的大幅降低使得M1在推理和大规模RL训练中都更为高效。
MiniMax-M1评测结果略超Qwen3-235B-A22B
MiniMax-M1在多项标准基准测试中,展现了与当前顶尖开源模型(如原始DeepSeek-R1、Qwen3-235B)相当甚至更优的性能,尤其在复杂的软件工程、工具使用和长上下文任务上表现突出。
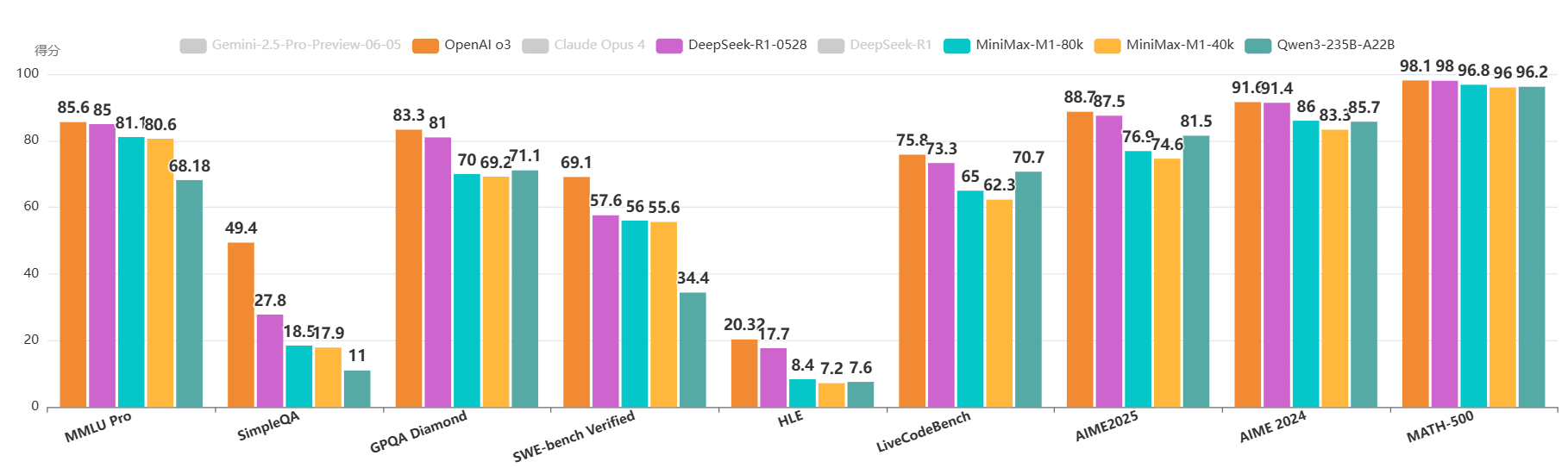
在数学推理(AIME 2024)等传统强项上,M1-80k表现稳健,在开源模型中仅次于最新的DeepSeek-R1-0528。 在复杂场景中,M1的优势尤为突出:
- 软件工程 (SWE-bench):得益于基于执行环境的RL训练,M1在解决真实世界GitHub问题的能力上,取得了56.0%的优异成绩,大幅超越除DeepSeek之外的其他开源模型。
- 长上下文理解 (OpenAI-MRCR):凭借其1M上下文窗口的硬件优势,M1在该项测试中得分高达73.4%,不仅碾压所有其他开源模型,甚至接近了顶尖闭源模型Gemini 2.5 Pro,仅次于后者,全球排名第二。
- 智能体工具使用 (TAU-bench):M1在模拟动态对话和API工具使用的场景中同样表现出色,超越了所有对比的开源模型。
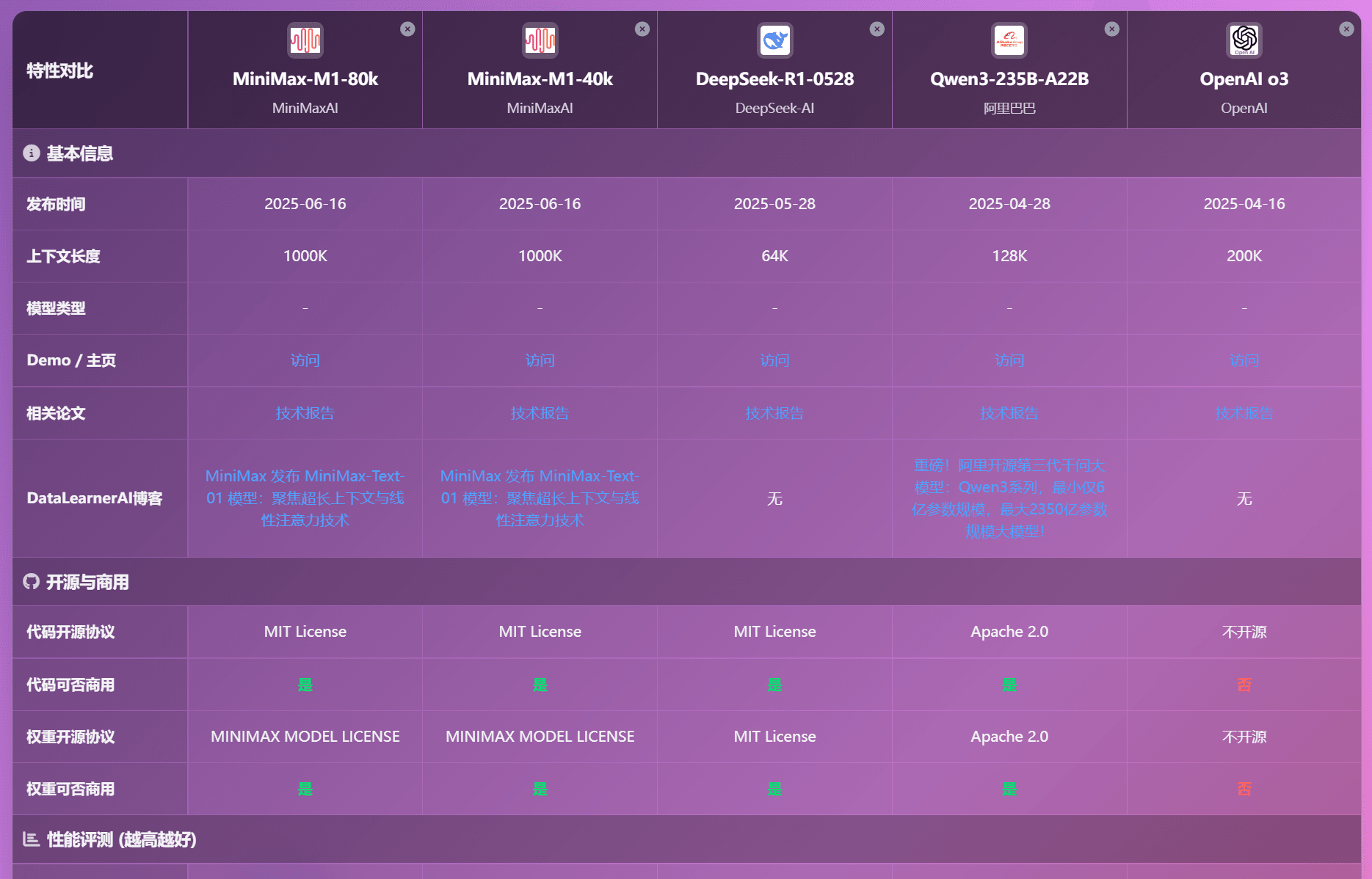
大家也可以在DataLearanerAI新的模型对比页面对比MiniMax-M1和其它模型情况:
MiniMax-M1的开源总结与展望
MiniMax-M1是完全开源商用授权,可以免费使用。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
